




SubQuery入门开发 | 第二期:SubQuery项目结构及区块处理
SubQuery中文站热度: 41811
一文了解SubQuery入门开发 | 第二期:SubQuery项目结构及区块处理

SubQuery 由 OnFinality 团队构建,允许用户在整个链中运行索引器来构建可通过 GraphQL 查询的数据集。该工具套件包括一个命令行界面,该命令行界面使项目可以生成自己的 SubQuery 项目,从而定义索引器应如何遍历和聚合自己的网络。
SubQuery 节点程序包将为网络建立索引并支持 GraphQL 查询。借助这些工具,任何人都可以轻松创建和运行查询。其目标是成为 Substrate / Polkadot 生态系统的核心基础架构。
OneBlock+ 与 SubQuery 在2021的最后一个月共同推出了「SubQuery 入门——轻松学会区块链数据索引开发」课程,已于2022年1月10日开课。通过课程 6 大模块的讲解,让你熟悉掌握如何将你的区块链项目建立 SubQuery 数据源从而进行链上数据索引,包括开发复杂的 SubQuery 项目和将其部署到 SubQuery 项目托管中。
以下是第二课的课程回顾:
本节课程内容
- SubQuery 项目的目录结构
- 清单文件
- schema文件
回顾:SubQuery的工作原理
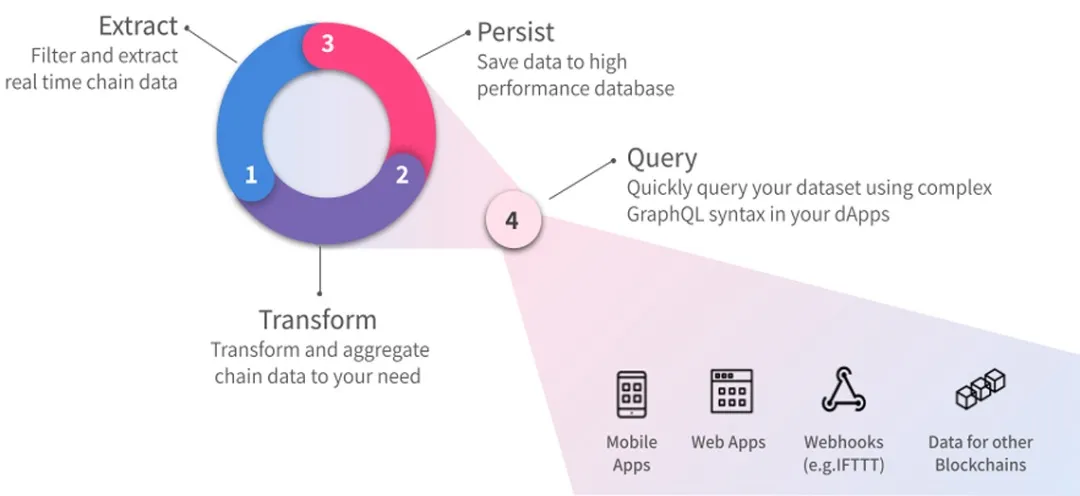
- 从区块链中实时获得和过滤数据;
- 将数据保存到高性能数据库中;
- 从分布式应用中,使用复杂的GraphQL语法查询数据集。
SubQuery的目录结构
当使用 subql init --specVersion 0.2.0 PROJECT_NAME 命令生成一个SubQuery项目时,这个项目的目录结构如下所示:
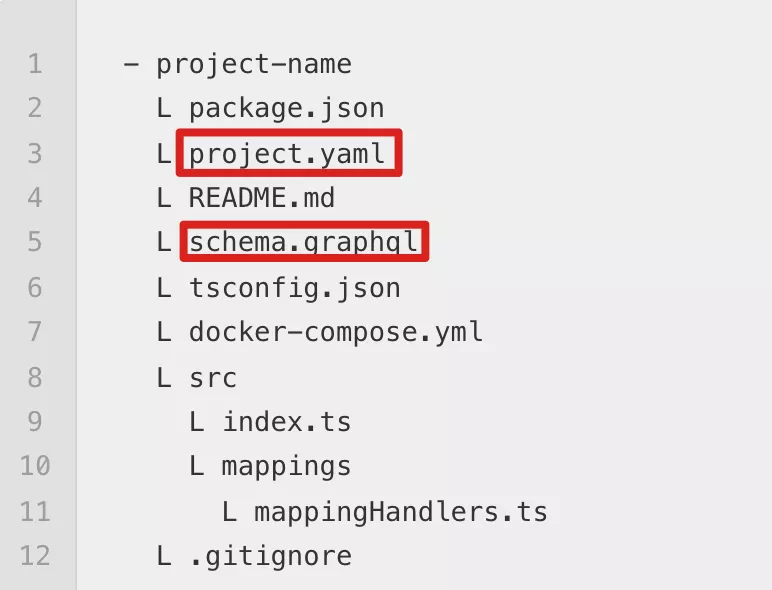
其中比较重要的就是清单文件 project.yam 和schema文件 schema.graphq 。
清单文件
- project.yaml 文件又被称为清单文件,可以看做是整个项目的入口点,它定义了SubQuery 如何对区块链数据进行索引和转换的细节;
- 清单文件可以是 YAML 或 JSON 格式。下面是一个YAML格式的清单问卷project.yaml 的示例。

Schema 文件
1. schema.graphql 文件定义了 GraphQL的模式。基于GraphQL 查询语言的工作方式,schema文件决定了来自 SubQuery 中数据的存储形态。
2. 对schema文件进行任何更改后,需要使用以下命令 yarn codegen重新生成相应代码。
3. schema文件的主要组成成分是实体(Entity)。每个实体必须使用 ID! 的类型定义其必填字段 id。id用作主键,在所有相同类型的实体中是唯一的。同时,实体中的不可为空的字段由 ! 指示。请看下面的例子:
type Example @entity { id: ID! # id field is always required and must look like this name: String! # This is a required field address: String # This is an optional field}
关于我们
One Block+ 是中国最大的 Substrate 技术开发者社区,也是 Parity 在亚洲唯一的运营合作伙伴,波卡生态早期项目的创始人、CTO、核心开发者大部分都来自 One Block+ 社区。
关于SubQuery
SubQuery是Polkadot的领先数据提供商,支持在Layer_1区块链(Polkadot)和去中心化应用程序之间建立索引和查询层。SubQuery的数据服务目前在大多数Polkadot,Kusama crowdloan和平行链拍卖网站使用。SubQuery 的协定是通过 SubQuery SDK 提取出区块链数据的特性,允许开发人员专注于部署其核心产品,而无需在定制后端技术上浪费精力。
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容