



SubQuery 入门开发 | 第六课:如何在SubQuery项目中进行性能调优
SubQuery中文站热度: 60231
一文了解SubQuery 入门开发 | 第六课:如何在SubQuery项目中进行性能调优
SubQuery 由 OnFinality 团队构建,允许用户在整个链中运行索引器来构建可通过 GraphQL 查询的数据集。该工具套件包括一个命令行界面,该命令行界面使项目可以生成自己的 SubQuery 项目,从而定义索引器应如何遍历和聚合自己的网络。
SubQuery 节点程序包将为网络建立索引并支持 GraphQL 查询。借助这些工具,任何人都可以轻松创建和运行查询。其目标是成为 Substrate / Polkadot 生态系统的核心基础架构。
OneBlock+ 与 SubQuery 在 2021 的最后一个月共同推出了「SubQuery 入门——轻松学会区块链数据索引开发」课程,已于 2022 年 1 月 10 日开课。通过课程 6 大模块的讲解,让你熟悉掌握如何将你的区块链项目建立 SubQuery 数据源从而进行链上数据索引,包括开发复杂的 SubQuery 项目和将其部署到 SubQuery 项目托管中。
以下是第六课的课程回顾:
本节课程内容
1. SubQuery 索引项目的耗时分析
2. SubQuery 索引项目的索引速度优化
3. SubQuery 索引项目的查询速度优化
耗时分析
一个 SubQuery 索引项目的主要耗时由 2 部分组成:
一:block 查询时间 ---->(由 SubQuery 处理)
block 的查询时间由获取 block range 的时间和查询,组装SubstrateBlock 对象所用的时间组成。
查询和组装 SubstrateBlock 对象
1.查询 header
2.查询 specVersion
3.查询 metadata
4. 查询 events
二:Block处理时间 ----> (是由用户在mapping函数里面实现的逻辑决定的)
● State query (状态查询)
● DB IO operations(数据库,IO的一些操作)
耗时分析工具
SubQuery-node 已经集成了这个工具,我们在 Profiler 模式下就可以查看某个方法的耗时情况
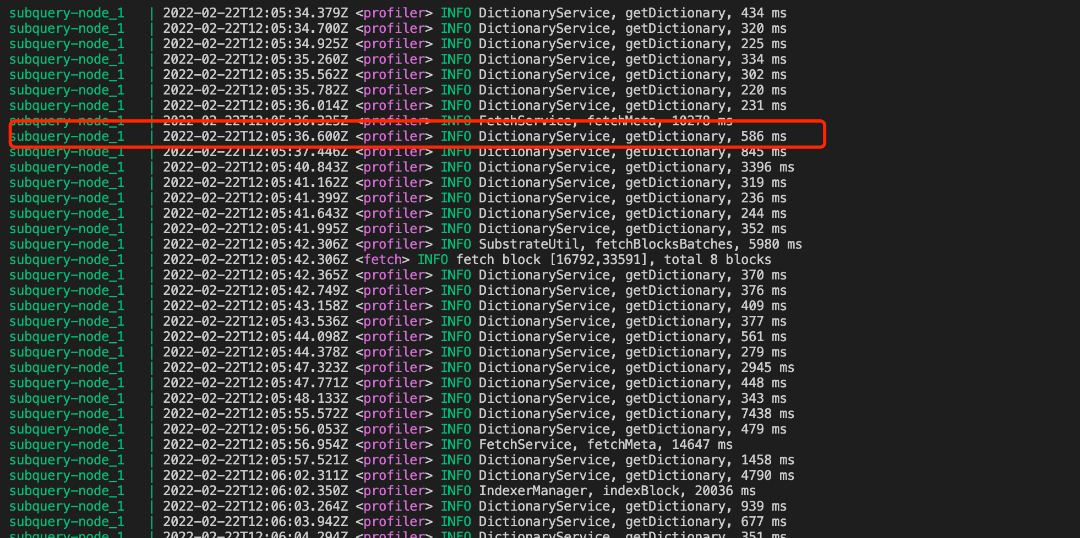
打开 profiler 模式
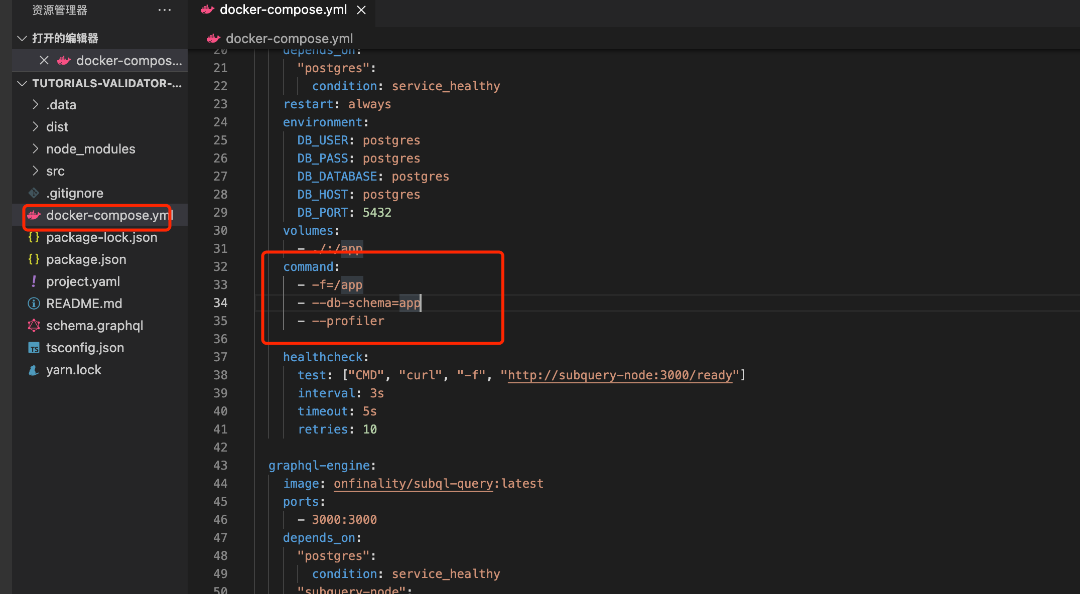
在 docker-compose.yml 文件中添加 - --profiler
SubQuery 的工作原理
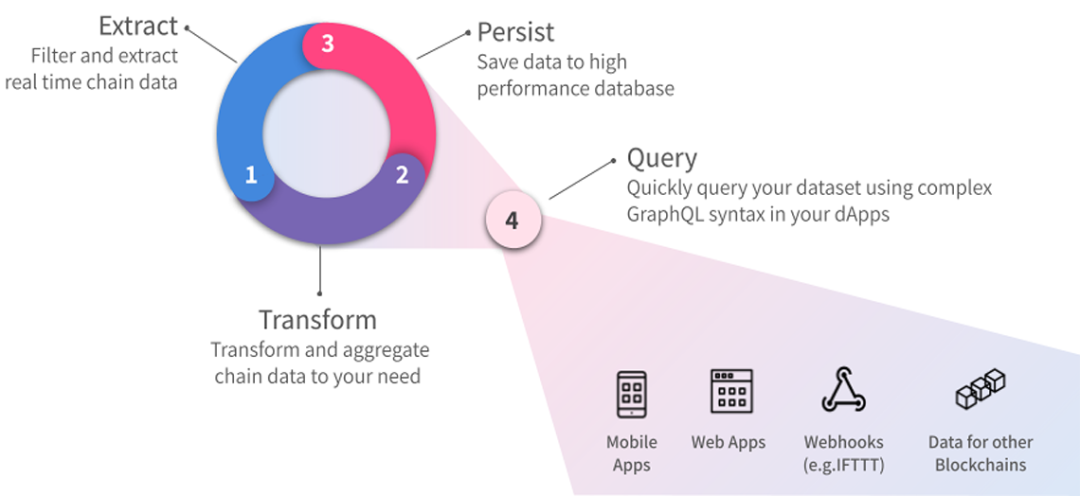
1. 从区块链中实时获得和过滤数据;
2. 将数据保存到高性能数据库中;
3. 从分布式应用中,使用复杂的 GraphQL 语法查询数据集。
通过 SubQuery 的工作原理的理解,我们可以将优化的重心放在索引速度和查询速度两个方面。
索引速度的优化
● 尽可能使用 filter 和字典
当使用字典时,索引器将首先将调用和事件过滤器作为参数,并将其合并为一个 GraphQL 查询。然后它使用字典的 API 来获取一个相关的区块高度列表,只包含特定事件和相关信息。
例如,想象一下,您需要检索转账的相关事件。并非所有区块都有这个事件(在下面的图像中,区块 3 和 4 中没有转账的事件)。
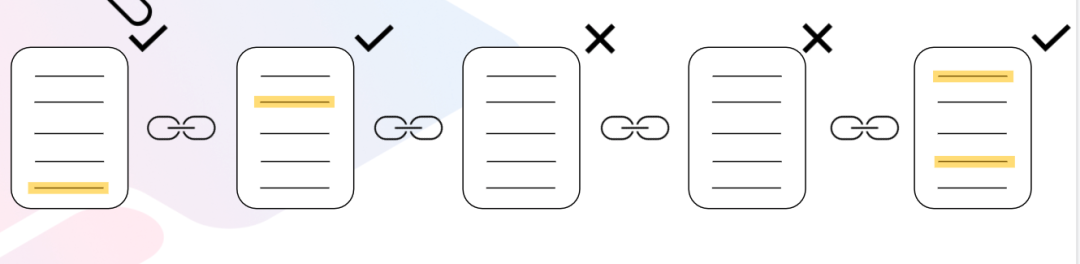
字典允许您的项目跳过这些区块,而不是在每个区块中寻找一个转账事件。它跳到了区块 1,2 和 5。这是因为字典是事先计算的每个区块中所有调用和事件的参考值。
这意味着使用字典可以减少索引器从该区块链中获得的数据数量,并减少当地缓冲区中储存的“不想要的”区块的数量。但与传统方法相比,它增加了一个额外步骤,需要从字典的 API 获取数据。
● 局部并行/批量处理
- ● 使用 api.queryMulti () --> 查询所有
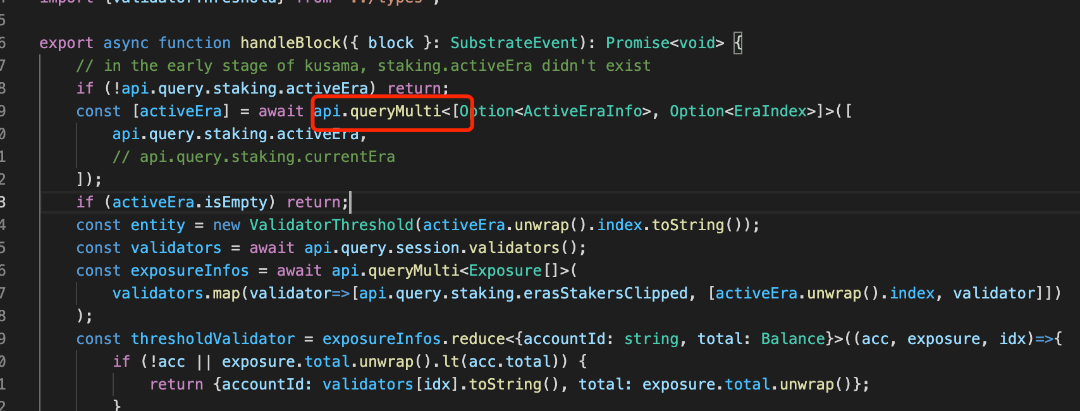
- ● 使用 Promise.all ()
可以 api 查询和数据库查询混合在一起,进行并行的加速
- ● 使用 store.bulkCreate ()
数据库的操作,如果向同一个表插入多条数据的时候,可以将指令合并之后一起插入,如果是多张表的话不会合并操作
● 尽可能的减少/最小化 State 查询
查询速度的优化
● Schema 设计
- a. 合理的拆分
- b. 减少非必要的数据
在 GraphQL 生成查询语句的时候,减少 join 的操作,缩短生成查询语句的时间
- c. 创建合理的索引
● 优化查询条件
- ● 尽量使用条件来减少返回的数据集
- ● 只查询必要的字段
- ● 大的数据表,避免在没有加上条件的时候查询 totalCount
参考资料
- ● 课程示例代码:https://github.com/subquery/tutorials-validator-threshold● GraphQL 开发原则:https://principles.graphql.cn/● SubQuery 开发文档:https://doc.subquery.network/
🎉 新课预告:「SubQuery 入门——轻松学会区块链数据索引开发」第二期开启报名,由 OneBlock+ 与 SubQuery 共同推出!通过课程 6 大模块的讲解,你将熟悉掌握如何将你的区块链项目建立 SubQuery 数据源从而进行链上数据索引,包括开发复杂的 SubQuery 项目和将其部署到 SubQuery 项目托管中。即使你是零基础开发者也可以学习本次课程,实现轻松为一个新区块链项目构建数据源,学会区块链数据索引开发。
关于我们
One Block+ 是中国最大的 Substrate 技术开发者社区,也是 Parity 在亚洲唯一的运营合作伙伴,波卡生态早期项目的创始人、CTO、核心开发者大部分都来自 One Block+ 社区。
Twitter: https://twitter.com/OneBlock_
Medium: https://medium.com/@OneBlockplus
Telegram: https://t.me/oneblock_dev
Discord: https://discord.gg/z2XZZWEcaa
Bilibili: https://space.bilibili.com/1650224419
YouTube: https://www.youtube.com/channel/UCWo2r3wA6brw3ztr-JmzyXA
关于SubQuery
SubQuery是Polkadot的领先数据提供商,支持在Layer_1区块链(Polkadot)和去中心化应用程序之间建立索引和查询层。SubQuery的数据服务目前在大多数Polkadot,Kusama crowdloan和平行链拍卖网站使用。SubQuery 的协定是通过 SubQuery SDK 提取出区块链数据的特性,允许开发人员专注于部署其核心产品,而无需在定制后端技术上浪费精力。
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容