




以Oasis、Arweave、Mina为例:探讨Web 3时代数据计算的可能范式
国盛区块链研究院热度: 55929
Web 3.0时代的区块链基础设施,光靠共识机制创新以及跨链是远远不够的,脱链/链外计算(off-chain)目前已经成为解决问题的大趋势。
原标题 | Web3.0程序该跑在哪里?
文 | 宋嘉吉 任鹤义
Web3.0时代,互联网底层不会全部基于区块链构建,数据计算也不会全部跑在公链的“独木桥”上。考虑到数据计算的效率问题、以及不同底层程序语言环境,Web3.0时代的数据计算基础层将是复杂多样的环境。因此,如何破解区块链时代数据计算效率成为下一代计算范式的重点方向。
Web3.0时代的区块链基础设施,光靠共识机制创新以及跨链是远远不够的,脱链/链外计算(off-chain)目前已经成为解决问题的大趋势。由于不可能三角的束缚,探索链外计算采用偏中心化等手段能够得到更高的扩展性,这种方案的关键是如何将链外计算结果在链上得到一致共识,通过TEE、零知识证明等技术手段实现链外数据计算结果回到主链上达成一致共识和安全。本报告分析以Oasis、Arweave、Mina等链下计算模式为案例,分析了Web3.0时代数据计算的可能范式,以及如何实现链上链下、链间数据计算协同的可能方式。
围绕性能的升级,公链的演进大致经历了如下历程:
1)共识机制的探索。共识机制经历了从POW到POS、再到各类POS机制的改进版本,无非是想解决公链的扩展性问题,但依然受不可能三角束缚;
2)跨链试图以多链来承载应用。跨链则是为了考虑一条公链不能适用于所有场景,需要多个公链来解决数据承载和计算运行。跨链依旧要对束缚行业的不可能三角进行相应的平衡;
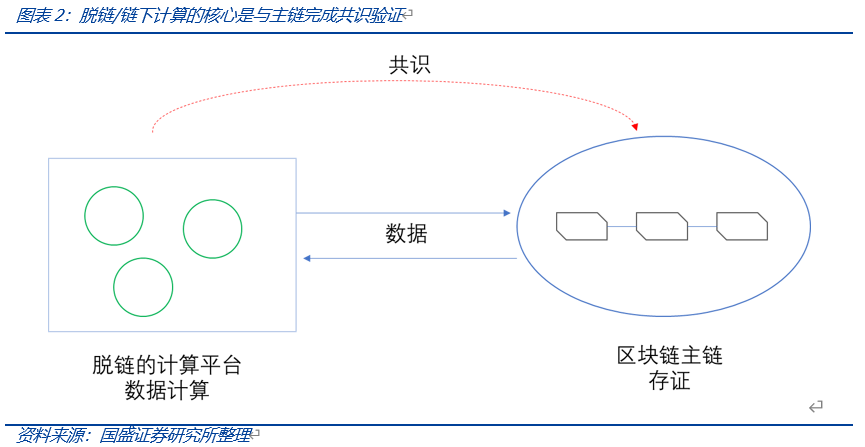
3)Off-chain(脱链计算、链外计算)来解放主链负担正在成为趋势。从以太坊2.0的分片到L2网络,全部工作无非围绕如何解放主链负担来进行。整体上的思路就是脱链/链外计算,把计算(存储等资源消耗)与存证分开。脱链计算最核心的问题就是链上链下数据验证问题,或者说,如何使链下的数据计算在链上得到共识,使得这种方式能够被去中心化用户相信。
本章节介绍Oasis、Arweave的SCP模式以及MINA生态的Snapp三个典型的脱链计算项目案例。从这些不尽相同的实现方式,可以窥见Web3.0世界的数据计算实现方案繁杂的真实一面。未来Web3.0世界,也许不是理想的公链独木桥,而是纷繁复杂的百花齐放。
在Web2.5时代,如何将数据在两个生态之间共享、程序如何跨两个生态运行、两个生态系统融合将是时代的刚需。将数据在中心化世界和去中心化世界共享,将催生预言机类应用的巨大需求。Web2.0时代的数据和应用将在通往Web3.0时代的路上长期存在,并将不断与Web3.0进行融合——数据将在所谓的新的Web3.0应用生态和当西Web2.0生态之间共享,应用程序将横跨Web3.0和Web2.0系统之间运行(Web2.5时代),用户将同时属于两个生态世界。另外,庞大的Web2.0时代的数据资产和计算方式将会继续长期存在,这些势必构成了Web3.0时代的一部分。对于这部分数据和计算如何与区块链主导的新生态进行融合,同时数据的存储、网络和计算内存等互联网基础资源的调用该如何协调,这些都是巨大的挑战。这方面的问题不是光靠跨链、预言机就能够解决的。
风险提示:区块链商业模式落地不及预期;监管政策的不确定性。


一、核心观点
Web3.0时代,互联网底层不会全部基于区块链构建,数据计算也不会全部跑在公链的独木桥上。考虑到数据计算的效率问题、以及不同底层程序语言环境,Web3.0时代的数据计算基础层将是复杂多样的环境。因此,如何破解区块链时代数据计算效率成为下一代计算范式的重点方向。
对于去中心化系统,光靠共识机制创新以及跨链是远远不够的,脱链/链外计算(off-chain)目前已经成为解决问题的大趋势。由于不可能三角的束缚,探索链外计算采用偏中心化等手段能够得到更高的扩展性,这种方案的关键是如何将链外计算结果在链上得到一致共识,通过TEE、零知识证明等技术手段实现链外数据计算结果回到主链上达成一致共识和安全。本报告分析以Oasis、Arweave、Mina等链下计算模式为案例,分析了Web3.0时代数据计算的可能范式,以及如何实现链上链下、链间数据计算协同的可能方式。
二、Web3.0的共识:公链独木桥外可以做很多事
以以太坊为代表的公链在基础性能方面的限制,光靠共识机制方面的创新是不够的,靠多链之间的跨接亦不足以承载web3.0的数据和计算。于是以太坊2.0的分片、L2、波卡平行链等各类扩展方案成为当下现实的解决方案。这些方案细节尽不相同,但最终都传递了一种市场共识:即,Web3.0数据和计算不会都跑在公链这个独木桥上,大量数据和计算处理会在公链之外实现(可以是L2、平行链,甚至可以是其他非区块链方式)。也就是说,脱(主)链计算(off-chain)已经成为行业的共识,尤其是对于大量的数据处理和计算,会在主链之外完成。
本文暂时称各类在底层公链主链之外的方式为链外计算。如何在公链之外建立有效的数据和计算平台,承载Web3.0各类应用成为未来重要的问题。
2.1.通往Web3.0之路:从共识机制、跨链、模块化公链的探索
公链基础性能是行业一个绕不开的终极问题。围绕性能的升级,公链的演进大致经历了如下历程:
1) 共识机制的探索。共识机制经历了从POW到POS机制,再到各类POS机制的改进版本,无非是想解决公链的扩展性问题。但无论怎样的共识机制,完成一致性的共识势必牺牲系统的工作性能,这是牢不可破的不可能三角;
2) 跨链试图以多链来承载应用。跨链则是为了考虑一条公链不能适用于所有场景,需要多个公链来解决数据承载和计算运行。例如,波卡(Polkadot)作为一个可伸缩的异构多链系统,能够传递任何数据(不只限于代币)到所有区块链,实现各个链之间资产与数据的互相流通。这对于区块链网络的扩展性和应用多样性来说非常重要,单独一条区块链的性能毕竟有限,且在专用和通用之间难以平衡。同时,束缚行业的不可能三角(即扩展性、安全和去中心化不可能同时达到)也要进行相应的平衡。
3) Off-chain(脱链计算、链外计算)来解放主链负担。从以太坊2.0的分片到L2网络,全部工作无非围绕如何解放主链负担来进行。即,繁重的数据计算交给主链之外进行——可能是分片这类划分任务群组的方式,或者L2、甚至是非区块链系统来承载数据计算,最终结果返回到主链存证。主链的一致性共识提供数据结果的验证,保证充分的去中心化和安全,而繁重的数据计算交给主链之外的平台进行。
虽然这些性能卓越的平台工作时牺牲了一些去中心化或者安全,但可以通过零知识证明、TEE等技术手段实现主链对链外平台的监督和验证。整体上的思路就是脱链/链外计算,把计算(存储等资源消耗)与存证分开。
近期,行业出现一个新提法:模块化公链。类似互联网协议分层,未来公链会分执行层(Execution Layer )、结算层(Settlement Layer)、数据可用性层(Data Availability Layer)。在以太坊上,执行层就是运行各类Dapp的L2,然后将打包的的交易数据(Rollup)返回到以太坊主链上做验证上链,目前数据同样是存储到以太坊上(当然是做Rollup打包后),但对于日益膨胀的原始数据,有人考虑设立数据可用性层来存储数据,进一步解放以太坊主链,使其只做验证计算工作(共识)——毕竟,庞大的链上链下数据验证问题数据存储会进一步限制以太坊的性能。
当然,这种理想的分层方法还未得到验证,包括Vitalik也对数据可用性层安全性提出了质疑的声音。脱链计算最核心的问题就是链上链下数据验证问题,或者说,如何使链下的数据计算在链上得到共识,使得这种方式能够被去中心化用户相信。

对于分片、L2和链外计算,公链就好比是货物运输管理严格的主干道(一致共识),不可能所有数据都跑在主干道上,支路的运输车辆,通过零知识证明等手段证明自己工作严谨、可信的前提下,可以将繁复的乡村毛细小路上的货物打包装箱后运行在主干道上。如何向主链证明其数据结果可信,则要借助零知识证明、TEE等灵活的技术手段,以适应不同的工作场景。
另外,庞大的Web2.0时代的数据资产和计算方式将会继续长期存在,这些势必构成了Web3.0时代的一部分。对于这部分数据和计算如何与区块链主导的新生态进行融合,同时数据的存储、网络和计算内存等互联网基础资源的调用该如何协调,这些都是巨大的挑战。这方面的问题不是光靠跨链、预言机就能够解决的。
三、Web3.0数据计算:链外计算的三种模式
虽然数据计算脱离了主链,但分片、L2等技术手段还是考虑基础数据计算依托区块链,兼顾了去中心化的考虑。由于不可能三角的束缚,探索链外计算采用偏中心化等手段能够得到更高的扩展性,这种方案的关键是如何将链外计算结果在链上得到一致共识,通过TEE、零知识证明等技术手段实现链外数据计算结果回到主链上达成一致共识和安全。
链外计算的核心问题是是脱离主链,数据计算如何获得共识?也就是说,如何使得用户相信主链之外的计算?
本章节介绍三个典型案例。从这些不尽相同的实现方式,可以窥见Web3.0世界的数据计算实现方案繁杂的真实一面。未来Web3.0世界,也许不是理想的公链独木桥,而是纷繁复杂的百花齐放。
3.1.Oasis:共识层与执行层(ParaTime)分离的模块化分层设计
Oasis网络是一个运用权益证明(POS)、去中心化的Layer1区块链网络,其使用的模块化架构实现了共识层和智能合约执行层ParaTime层两部分的解耦合,即数据计算(合约执行)脱离了L1主链(即共识层),放在ParaTime层执行,且充分考虑了隐私计算。同时在设计上,对共识层进行了尽可能简单化的设计,共识层仅处理Token的转移、质押以及解绑定等较为简单的操作,这一设计类似于以太坊Layer2项目将智能合约的执行与共识操作隔离相类似,均有助于提高网络的安全性与效率。而在ParaTime层的设计上,Oasis将该层的各个ParaTime模块相分离,不同的ParaTime模块可针对不同的需求做出相应的优化调整,彼此之间互相独立的完成运行。
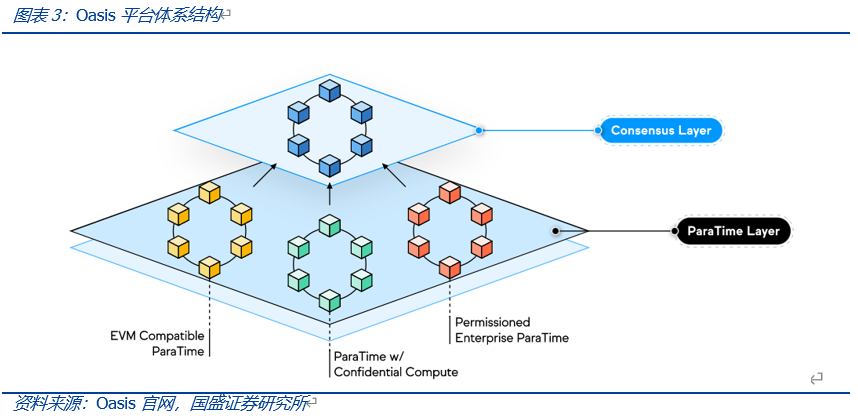
运行时,不同的ParaTime构建各自不同的执行环境、验证机制以及加密机制,智能合约在ParaTime层完成执行后,将其结果值提交至共识层。共识层则从ParaTime层中接受各类参数值,并将这些值写入下一个区块之中,同时处理较为基础的操作。而在运行过程中,若存在某个ParaTime的运行超载或出错,其仅会影响出错ParaTime提交到共识层的状态更新,不会对其他ParaTime的运行产生影响。为防止某一ParaTime层恶意向共识层发送过多的垃圾信息导致共识层运行速度降低,每一ParaTime层必须向共识层支付交易费用,从而增加负载攻击的成本。
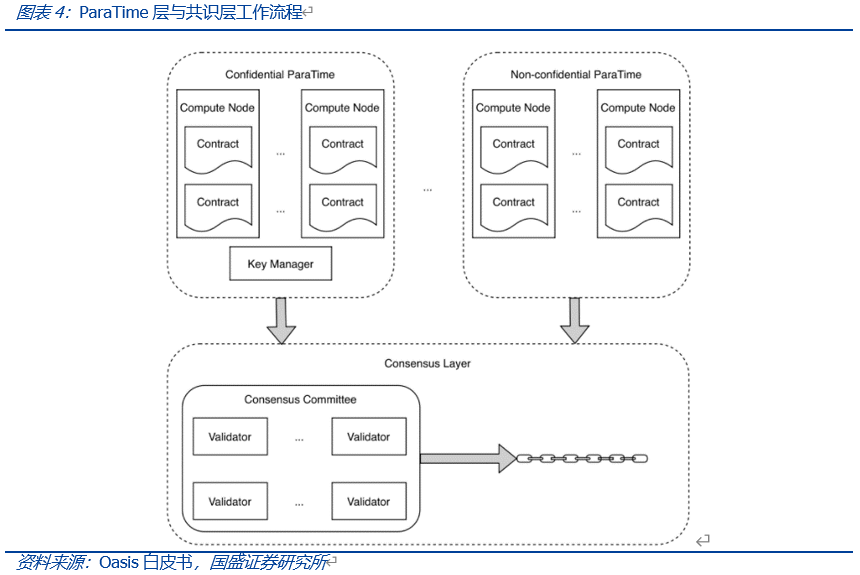
那么ParaTime层如何与L1主链完成对接以及达成共识呢?在执行结果的验证方面,Oasis采用差异检测来对ParaTime的执行结果进行验证。在执行差异检测时,会从节点中随机选择计算节点组成计算委员会,当委员会所有成员同意结果时,则会接受结果。如若检测到差异,则使用差异解析协议对其进行处理。差异检测成本更低执行更快,而差异解析则往往会耗费更多的成本。具体执行过程中,计算节点首先将执行结果通过Gossip协议网络发送到差异检测器,检测结果若无异常,则由验证器提交至共识层完成处理和出块。若是存在争议,则会启动差异解析协议来确定正确结果,并对产生争议结果的节点进行惩罚,由争议节点支付差异解析的成本。
不同的ParaTime在进行并行运算时,可以将每个结果同步提交至共识层,也可定期提交多个结果的融合值,以此实现ParaTime结果产出量与共识层出块数量的解耦合。但其缺点在于无法确定不同ParaTime之间的相对顺序,如ParaTime A产出的结果TA与ParaTime B产出的结果TB被同时提交至同一区块,则无法判断TA与TB的发生顺序。除此以外,Oasis还支持通过IBC协议(链间通信协议,Inter-Blockchain Communication Protocol)为不同ParaTime间提供通信,通过TEE(可信执行环境)为平台提供更高的隐私和安全性。
隐私计算是Oasis的亮点。Oasis网络支持隐私计算基础上的智能合约,充分体现了隐私计算的特点。在加密的ParaTime中,节点需要使用TEE(可信执行环境,Trusted Execution Environment)安全计算技术,TEE相当于为智能合约执行提供一个安全岛。数据对节点运营商或应用开发者来说是完全加密的。计算层采用TEE可信执行环境运行智能合约,使Oasis网络可以兼顾性能和隐私,且支持计算密集性应用场景,如近期流行的机器学习和深度学习。
总结而言,Oasis通过将共识层与计算层分离的方式,实现了节点功能的解耦合,从而大大降低了网络各个节点的运行压力,提高了平台的运行速度。同时TEE为数据计算提供了隐私与安全解决方案,在Web3.0时代有着丰富的想象空间。
3.2.Arweave:基于存储共识的计算范式
Arweave(AR)通过去中心化的运行方式以及POA(Proof Of Access)共识机制为用户提供数据存储服务,同时向提供存储服务的矿工给予AR奖励。POA实现的基础为Arweave独创的Blockweaves结构,每一区块不仅与先前块(Previous Block)相连,还同时与一个召回块(Recall Block)相连,召回块的生成则取决于先前块的哈希值以及区块高度。在决定出块矿工时,矿工必须证明他们能够访问召回块中的数据,从而获得出块权,进而获得出块奖励。因此这就要求矿工1)尽可能多的复制各类区块;2)尽可能的保存难以复制的区块:3)尽可能的保存存储人数较少的区块,从而在开采新块时获得更多的优势。同时由于区块链特有的数据可验证和可追溯的特性,能够极大程度的确保链上数据的可信性,从而实现可信的永久存储。
Arweave采用 "一次付费,永久存储 "的模式。长期来看AR的存储的成本非常低,甚至接近于零。且AR的存储效率较快,因此,AR常被比喻为图灵机的磁带,就像磁带一样、以较低的成本存储用户数据。
因此,利用AR的高效、低成本的存储,可以将数据计算放在链下进行,而数据源来自于AR链上、且计算结果也会存证上链。SCP(基于存储的共识范式,Storage-based Consensus Paradigm)正是实现基于AR的计算,即AR作为数据来源的图灵磁带,为链下应用程序提供数据源,计算结果亦上传到AR存证。其效率决定于链下应用程序和计算机的性能,自然比基于共识机制的链上计算要高。
在以太坊等传统Layer1上,计算、存储以及共识等功能均由节点负责,通过POW等共识机制完成上链存证,而受不可能三角的束缚,其效率可想而知。而SCP则将链上存证与计算功能相分离。简而言之,公链本身更像是计算机硬盘,只负责数据的存储。在保证链上存储数据可信的前提下,智能合约的执行则可以在链下任何具有计算能力的设备上进行。
SCP的理念源于SmartWeave,其为建立在Arweave上的智能合约平台,通过懒惰评估过程(The Process of Lazy Evaluation)将智能合约的执行负担转移到用户身上。不同于以太坊每个节点都要执行每一笔交易(这样的共识会影响计算效能),SmartWeave采用“惰性评估”系统,将交易验证的计算交给用户。当用户与 SmartWeave 合约交互时,他们会评估 dApp 上的每笔先前交易,确认与链上存储数据最新状态一致,然后将交易结果写入 Arweave 网络进行存证,如此重复。运行时,可将SmartWeave看作是链外运行的虚拟机。其通过读取应用程序的代码以及Arweave上的输入参数,在本地完成交易的执行,之后再将输出结果与Arweave同步,从而实现链上存储与链下计算的分离。用户的验证工作类似区块的链式结构,逐级追溯、验证交易,而这一切并不需要在链上完成,而是用户在链下完成的工作,也就是说,这个环节可以不受共识机制的束缚。
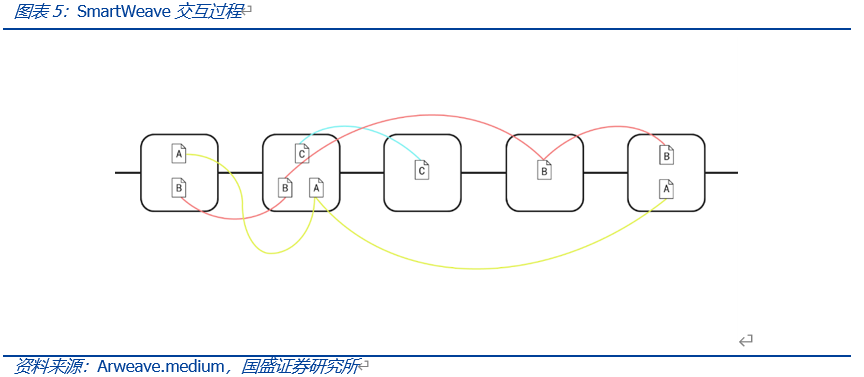
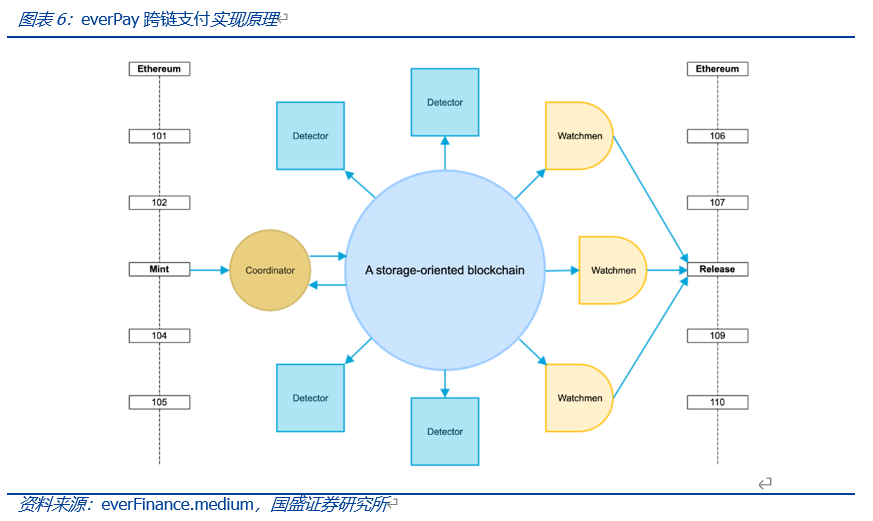
SCP的另一个开发实例是Arweave上的everPay。everPay是一个跨链代币支付协议,为用户和商户之间提供实时的代币支付服务。everPay将其他公链的各类资产锁定在一个智能合约之中,并将其映射成相应的资产。如当用户将资产从Ethereum跨链至Arweave时,首先由Coordinator收集和验证交易,并将各笔交易放入序列化的待处理交易池中,随后待处理的交易会被分批打包,每隔一段时间上传至Arweave。此后Detector会对链上全局状态以及账户余额进行验证,任何用户都可以申请成为Detector节点。而Arweave上未经处理的交易则会由Watchmen来使用多重签名或阈值签名来完成,并将完成结果返回至Ethereum。因此,合约的执行均在链下完成,数据均存储于链上,实现存储与计算的分离。
总结而言,基于存储的共识范式建立起了Offchain-Dapp的原型。链上存储,链下运行,充分发挥链上存储可溯源、不可篡改的特性。在基于数据可信的基础上,解放链上运行所带来的的负载压力,将其分散至用户方,更合理的使用Web3.0资源的同时,提高Dapp的运行效率。同时,SCP的开发可以基于任何编程语言进行,且链下计算的效能提高了可用性和可扩展性,存储成本低;同时,链下部署应用程序与Web2.0应用可以进行很好的对接。
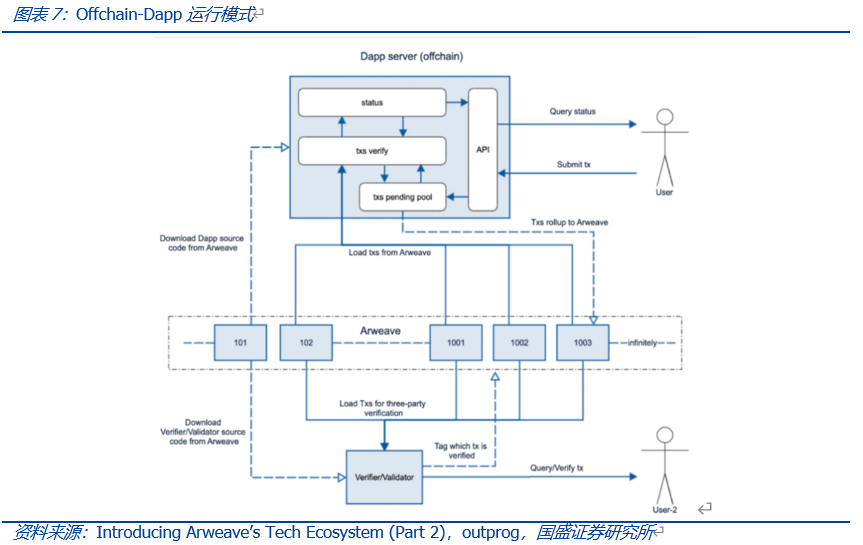
另外,如何确保链下应用程序执行的计算可信——即如何实现SCP的共识?数据来自于AR链上,应用程序也可以开源发布在链上,因此,计算程序和数据均有链上存证保证,如果用户本地修改应用程序和数据,那么相当于形成了一次分叉,并不源数据和应用程序的计算结果共识。这一点与区块链项目的开源代码类似,矿工节点运行一样的开源客户端脚本,形成一致共识。如果对客户端代码(或者数据源)进行修改,那么将形成一次分叉。因此,虽然运算是在链下执行,但来自于链上的数据源和开源程序代码确保了链下结果可信。
3.3.Mina:零知识智能合约Snapp
在主链和外部应用环境之间进行数据计算协同工作,为了使得最终的结果达成共识,需要证明每次计算使用的数据与链上的区块中数据一致。对于存储在一连串历史区块中的数据,在主链和外部应用环境之间,如何以较轻便的、去中心化的方式来验证数据的有效性?Mina作为目前最为轻量级的公链平台,通过递归零知识证明将区块链替换为易于验证、区块大小恒定的加密证明,不必穷尽所有区块,而以最新区块(21kb左右)就可以实现验证。这样大幅减少了每位用户需要下载的数据量,降低用户点对点连接的门槛,提高了网络的去中心化程度。
一般区块链公链整个账本数据量非常大(如比特币账近400G),且按照时间顺序分散在很多区块中,为数据验证带来较大是负担。Mina则使用递归zk-SNARK(零知识证明)实现验证证明,只需要把每个区块中的交易做一次验证证明,然后将证明存入区块中,且不会为每一个区块单独做一次证明,而是每一次新区块做证明时连带上一次的区块证明一起生成一次证明,存入最新区块。可以简单理解为,类似套娃一样,最新区块将本区块内的数据和前一个区块的验证证明数据一起做一个类似快照的证明。这样,每一个区块都只需要一个次证明结果,就可以将所有历史区块的数据证明包含在内。举一个例子比喻,旅行者为了证明自己到过哪些景点,可以每到一个景点便打卡拍照,且下一次景点拍照时候手拿上一次景点照片一起拍照,如此递归下去,每一张照片都套娃式的包含了前面所有景点的打卡信息,那么只需要一张最新的照片,就能够证明该旅行者确实到过所有的景点。
这样就实现了一种效果:区块链上储存的全都是交易正确性的证明,而非交易本身。因为前面说到的这种证明占用空间很小,因此区块的大小得以被压缩。
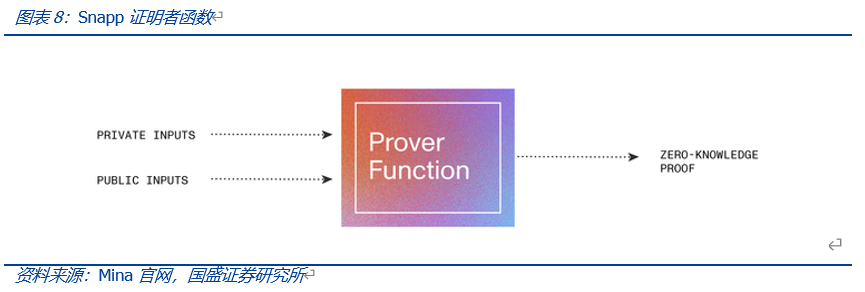
在此基础上,Mina开发了更具可延展性以及以隐私为中心的Dapp——Snapp。Snapp由智能合约和UI界面两部分组成。由于Snapp基于零知识证明(zk-SNARKs)构建,开发者需要构建证明者函数和相应的验证者函数来生成和处理零知识证明。
证明者函数作为Snapp的一部分直接运行在用户的web浏览器,当用户与Snapp的UI界面交互时,用户需要将私有数据输入(PRIVATE INPUTS)和公共数据输入(PUBLIC INPUTS)提交给证明者函数以生成零知识证明。
在生成零知识证明之后,不再需要用户提供任何私有数据输入,进而保护用户隐私安全。验证者函数则用于验证零知识证明是否通过了证明者函数中定义的所有约束函数(也就是数据是否有效),一般由Mina网络完成验证。
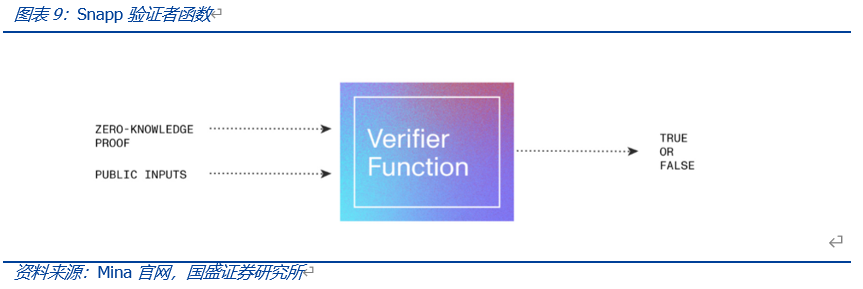
具体运行上,证明功能在用户的web浏览器上完成,其生成的零知识证明(验证密钥)则会被存储在给定Snapp账户的链上,之后发送至Mina网络进行验证。因此,交易的生成和数据计算在链下完成,同时该过程会生成可用于验证交易的零知识证明,而用户原始私有数据隐私是得到充分保护的。链上只负责对该证明进行验证,通过验证后将其上链保存,并对Snapp的状态进行更新。
从用户的角度来看,当用户与Snapp进行交互时,用户通过智能合约的前端UI与之进行交互,之后Snapp通过证明者函数将用户输入的数据在本地生成零知识证明,数据可以是私有的(不会被透明公开)也可以是公共(存储在链上或链下)的。除此以外,还会生成与交易有关的Snapp状态更新列表,用于更改Snapp状态。之后用户将数据提交至Mina网络,Mina网络会通过Snapp给出的验证者函数对该笔交易进行验证,成功通过后更新Snapp的状态。
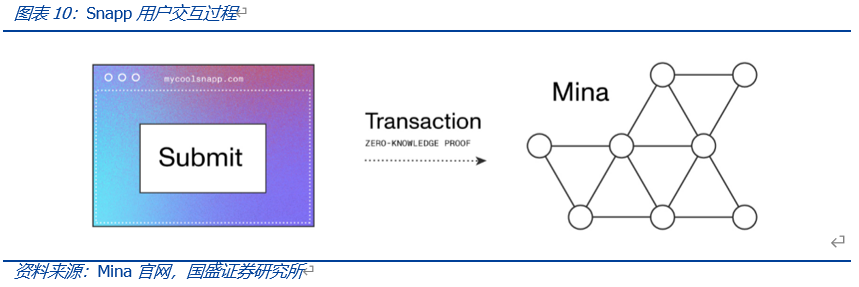
例如用户可以将自己的征信数据在本地生成证明并提交上链,可以在不泄露自身隐私数据的情况下,得到DeFi系统灵活的信贷服务;而传统的DeFi借贷服务都是需要以资产的超额抵押为前提。这个应用场景的意义在于,将多个生态的数据和应用实现快速对接,这些生态可以是区块链、也可以是链下生态。因此,Snapp应用可以很方便充当跨链、跨链上链下的桥梁角色。
3.4.小结
从上述三个案例来看,Oasis平台在设计时就考虑到了模块化分层设计,因此在设计之初就完成了计算与共识的分层。而Arweave与Mina更类似使用分层解决方案来主动的将计算与存储等功能进行分离,如Arweave的SCP与Mina的Snapp均是在公链运行一段时间后才诞生的。总结而言,前者为设计上的分层,后两者为解决方案上的分层。抛开这两类不同路径的整体表现情况,对于现有公链而言,解决方案的路径似乎能够更快速的完成共识、计算与存储的分层,并且能根据自身特点做出相应的调整。但如若分层与模块化将成为不久将来的发展方向,前者的设计架构上的转变似乎才能更好的面对时代的需求。
四、Web2.5时代的刚需:预言机
也许未来Web3.0的真是样子难以预测,但毫无疑问的是,Web2.0时代的数据和应用将在通往Web3.0时代的路上同时存在,并将不断与Web3.0进行融合——数据将在所谓的新的Web3.0应用生态和当西Web2.0生态之间共享,应用程序将横跨Web3.0和Web2.0系统之间运行,用户将同时属于两个生态世界。我们不妨将Web2.0向Web3.0过渡的时期成为Web2.5时代。
在Web2.5时代,如何将数据在两个生态之间共享、程序如何跨两个生态运行、两个生态系统融合将是时代的刚需。将数据在中心化世界和去中心化世界共享,将催生预言机类应用的巨大需求。
Web2.0时代API接口成为App获取外部数据的重要方式。API接口即应用程序接口(Application Programming Interface)是一组预先定义好的函数或HTTP接口,其允许用户或开发人员不访问源码而直接调用程序的例程。对于app而言,API接口成为了APP获取外部数据以及输出自身数据的窗口。而对于链上应用程序Dapp而言,由于区块链本身确定、封闭的特性,Dapp一般无法直接获取链外数据(如Dapp从Coingecko上获取BTC实时报价)。预言机(Oracle Machine)正是区块链外信息写入区块链内的机制,其本质是为智能合约提供外部信息的第三方服务,当智能合约请求链外数据时,由预言机将链外数据输入链上。
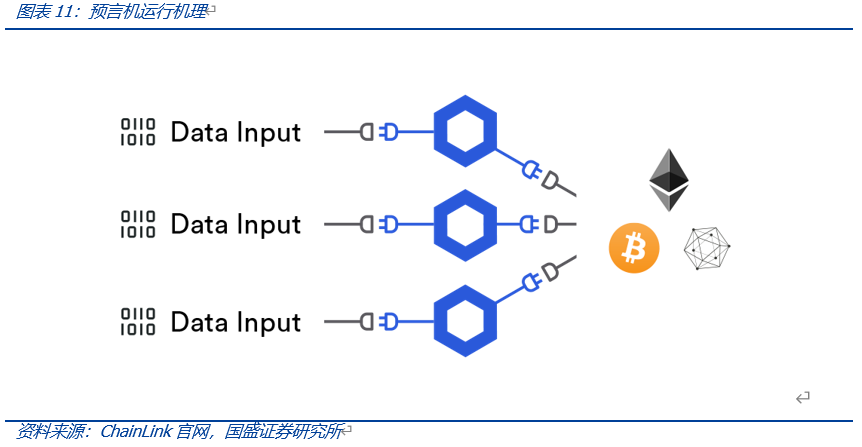
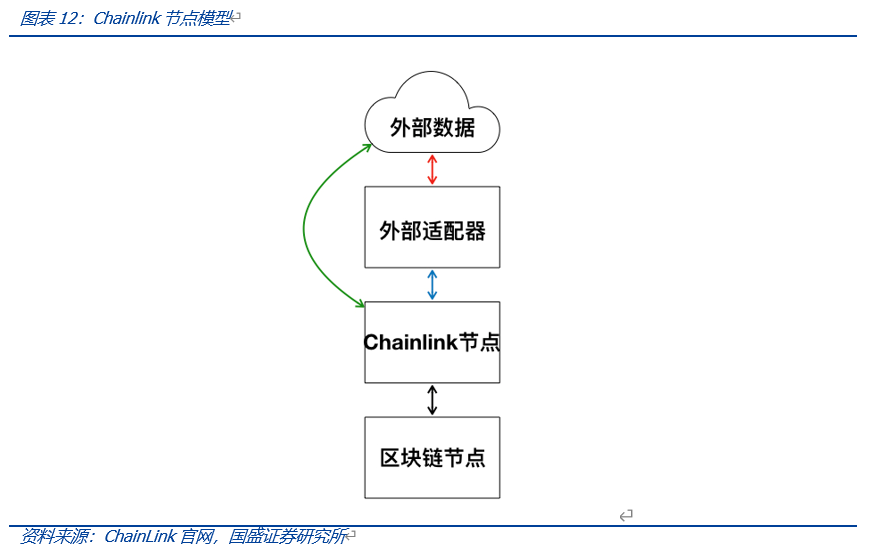
目前ChainLink为链上使用较多的预言机协议之一,其使用第三方预言机的方式运行,即在链上合约请求外部数据时,合约的请求将发送给预言机合约,之后预言机合约将相关事件发送给第三方的链下Chainlink网络,由ChainLink网络完成外部数据的收集工作,此后再次通过预言机合约将数据返回请求数据的合约。该方法的好处在于由Chainlink提供的第三方预言机通过预定的共识规则来确定结果能够确保数据传输的安全性,然而无效冗余(第三方预言机没有API提供者直接提供外部数据高效)和缺少透明度(第三方网络无法得知数据来源)的存在导致第三方预言机仍面对不少的挑战。
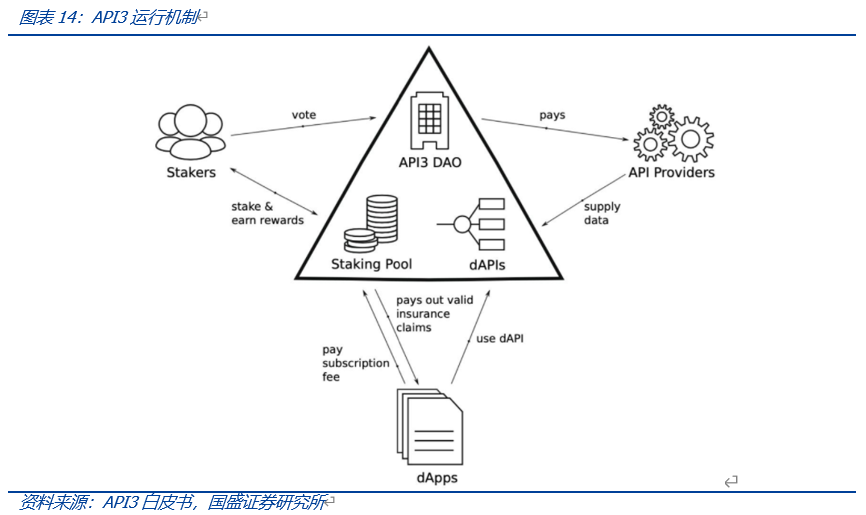
API3为解决第三方预言机存在的问题,其采用第一方预言机的方式将API的提供直接交给了由数据提供商运营的预言机,组成dAPI,并通过DAO管理其数据馈送。
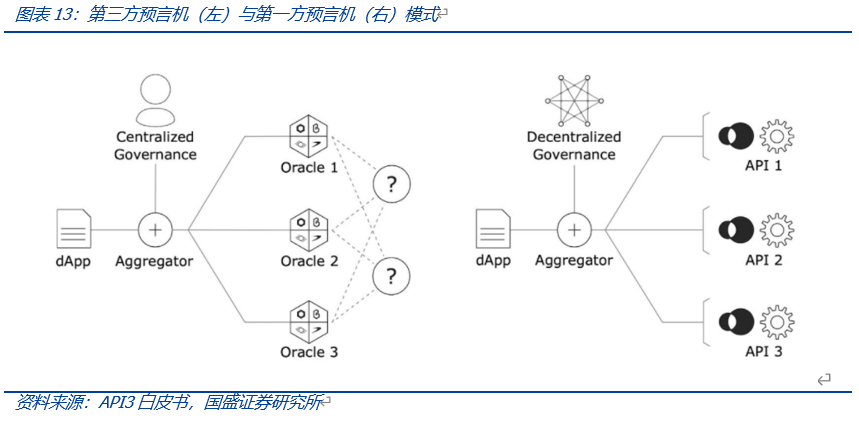
运行时,dApps订阅dAPIs服务并支付相应的订阅费,以此获取数据或服务,当调用的数据出错时,使用Staking Pool中的资金为订阅支付赔偿。API提供着向提供dAPIs,各自运行各自的预言机服务,由API3 DAO向其支付相应的报酬。Stakers通过质押API3 Token,为质押池提供保险金并参与API3 DAO的治理,主要包括选择较为优质的服务商进入聚合器dAPIs。
链下计算很重要的一点在于保证链上数据的可信性,如按照数据来源将链上数据分为链上产生和链下导入两类,则需要同时保证该两类数据的可信性。API3等预言机协议的存在保证了链下导入数据的可信性,但是否存在一种更为高效的方式,将原本需要链下导入的数据直接交由链下计算,从而减少链上负载,还值得我们去探索。
风险提示
区块链商业模式落地不及预期:Web3.0基于区块链、密码学等技术,相关技术和项目处于发展初期,存在商业模式落地不及预期的风险。
监管政策的不确定性:Web3.0实际运行过程中涉及到多项金融、网络及其他监管政策,目前各国监管政策还处于研究和探索阶段,并没有一个成熟的监管模式,所以行业面临监管政策不确定性的风险。
本文节选自国盛证券研究所已于2022年3月9日发布的报告《国盛区块链|Web3.0程序该跑在哪里?》,具体内容请详见相关报告。
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容