



Paradigm:如何准确测量区块链网络延迟和吞吐量
Foresight News热度: 20931
测量大规模分布式系统至关重要的是识别交易请求数量瓶颈和当网络处于超载下的预期行为。
撰文: Lefteris Kokoris-Kogias 编译:Aididiao
如何正确测量区块链网络延迟和吞吐量是系统在设计和评估时最重要的步骤之一。由于许多共识协议和变体具有各种性能和可拓展性,到目前为止,仍然没有普遍认可的方法和值得参考的案例。本文我们尝试概述一种从数据中心系统测量获得启发的方法进行测量延迟和吞吐量,并讨论在评估区块链网络时要避免的常见错误。
网络延迟和吞吐量及其相互作用
开发区块链系统时应考虑两个重要指标:延迟和吞吐量。
交易延迟是从发起交易或付款到收到确认其有效之间的时间,交易延迟的长短会直接影响用户体验。在 BFT 系统(例如 PBFT、Tendermint、Tusk & Narwhal 等)中,交易被确认就算是完成了;而在 PoW 或 PoS 共识链(例如 Nakamoto Consensus、Solana 和 Ethereum PoS)中,包含信息的区块需要进行传输和验证,结果导致网络延迟会比较长。
区块链网络的吞吐量是指系统每单位时间处理的总负载,通常以每秒交易数表示。
这两个关键指标似乎是彼此相反的,吞吐量以每秒交易数来衡量,延迟以秒为单位,我们自然会联想到吞吐量 = 负载 / 延迟。
然而事实并非如此,许多系统在生成表格时,习惯于在 Y 轴上显示吞吐量或者延迟,在 X 轴上显示节点数。但如果我们想要观察吞吐量和延迟之间的关系,最好 Y 轴代表延迟,X 轴代表吞吐量。从下图可以看出,它们显然不是线性关系。
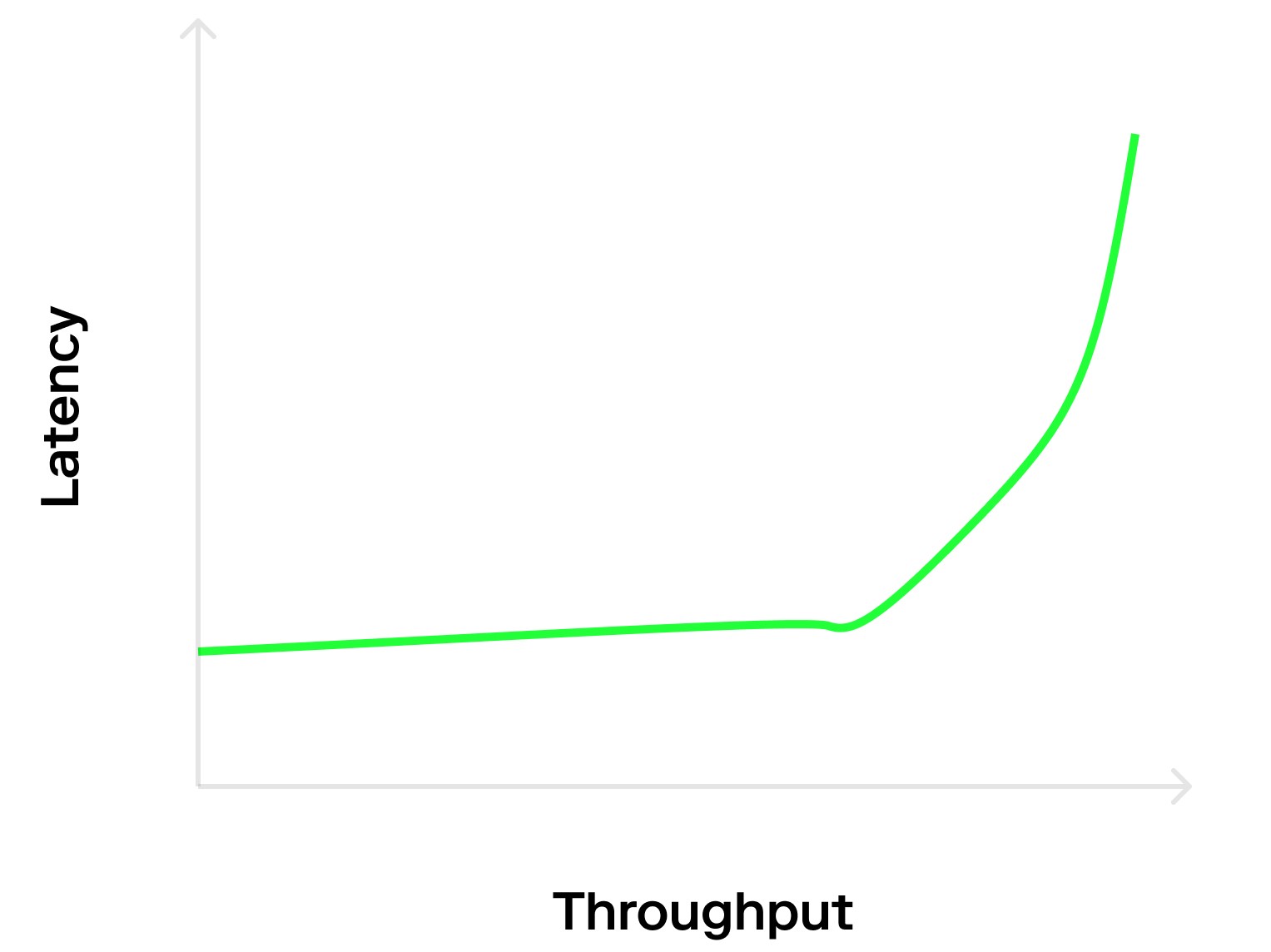
当网络交易数较少时,延迟是恒定的,并可以通过改变负载来改变吞吐量。在这种情况下,交易延迟几乎为零,完成交易只需要一个固定的成本即可。
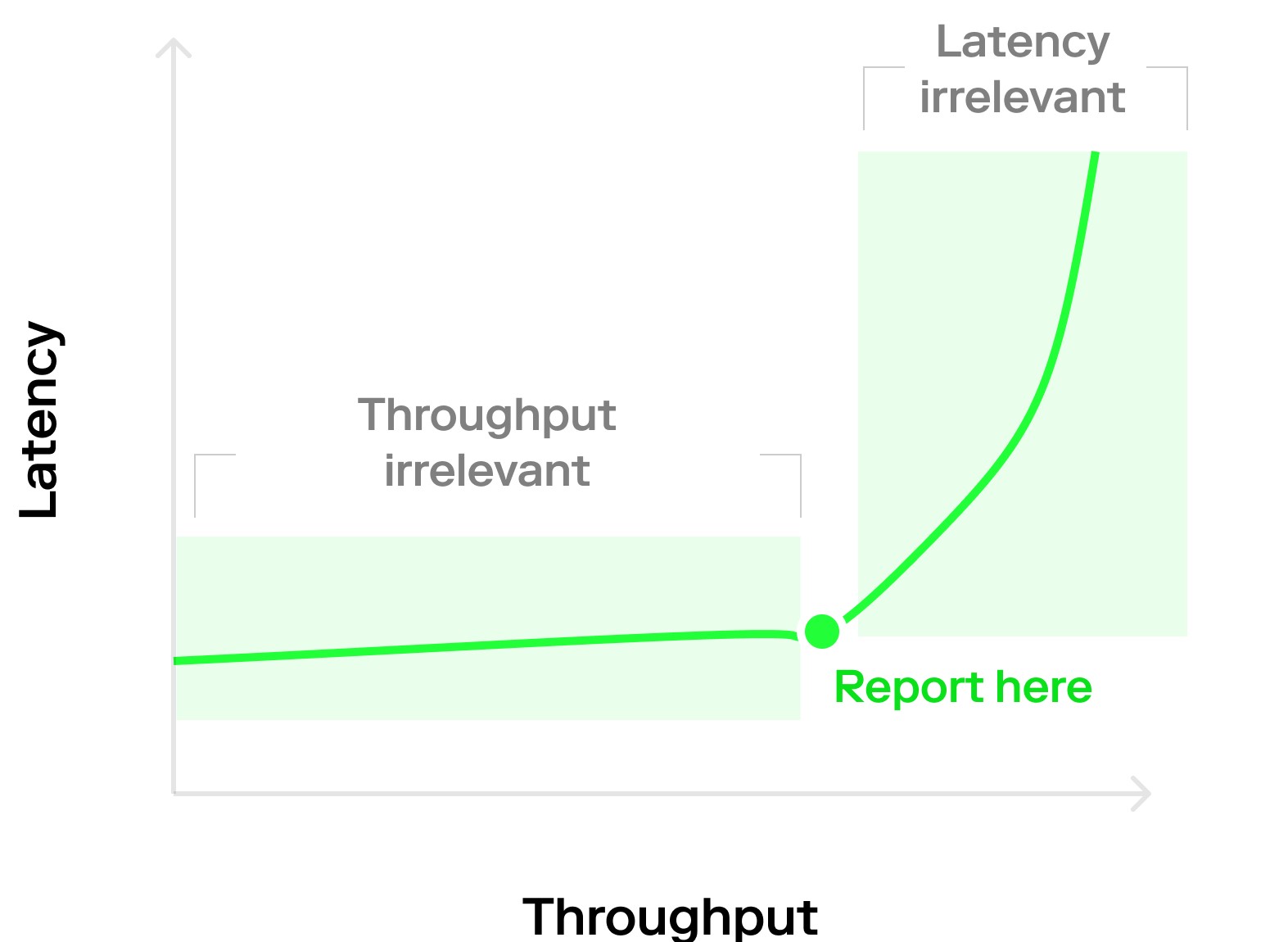
在网络交易数较多时,吞吐量是恒定的,但延迟可能会因为负载的变化而变化。如果系统已经超载,再增加更多负载会导致交易等待时间无限延长,延迟时间还会随着等待时间而变化。因此本文关键要点是应该选择在合适区域进行测量。考虑到吞吐量和延迟对基准测试的影响,测试不能在曲线边缘位置进行。
测量方法
在进行实验时,有三个主要的设计选项。
开环控制系统和闭环控制系统
有两种主要方法可以控制对目标的请求。开环系统由 n= ∞个客户端建模,客户端根据速率 λ 和到达间隔分布(例如,泊松)向目标发送请求。闭环系统可以在任何给定时间内限制未完成请求的数量。开环环境和闭环环境的区别是统一规格系统可以部署在不同的场景中,例如一个键值储存可以在开环环境中为数千个应用程序服务器提供服务,或者在一个闭环环境中只为几个阻塞客户端提供服务。
选择正确的场景进行测试是必不可少的。闭环系统的延迟通常收到潜在未完成请求数量的限制,而开环系统可能等待着大量交易请求指令,从而导致更长的延迟。一般来说,区块链协议可以被任意数量的客户使用,并在开环环境中得到更准确的评估。
综合基础的到达间隔分布
创建合成工作负载时需要主要的是如何提交交易请求。许多系统在测量开始之前会预加载事务,导致实际测量产生偏差。更好的方式是以确定的速率(如 1000TPS)发送请求,将会呈现 L 形图(橙色标记),此时为系统容量最佳使用状态。
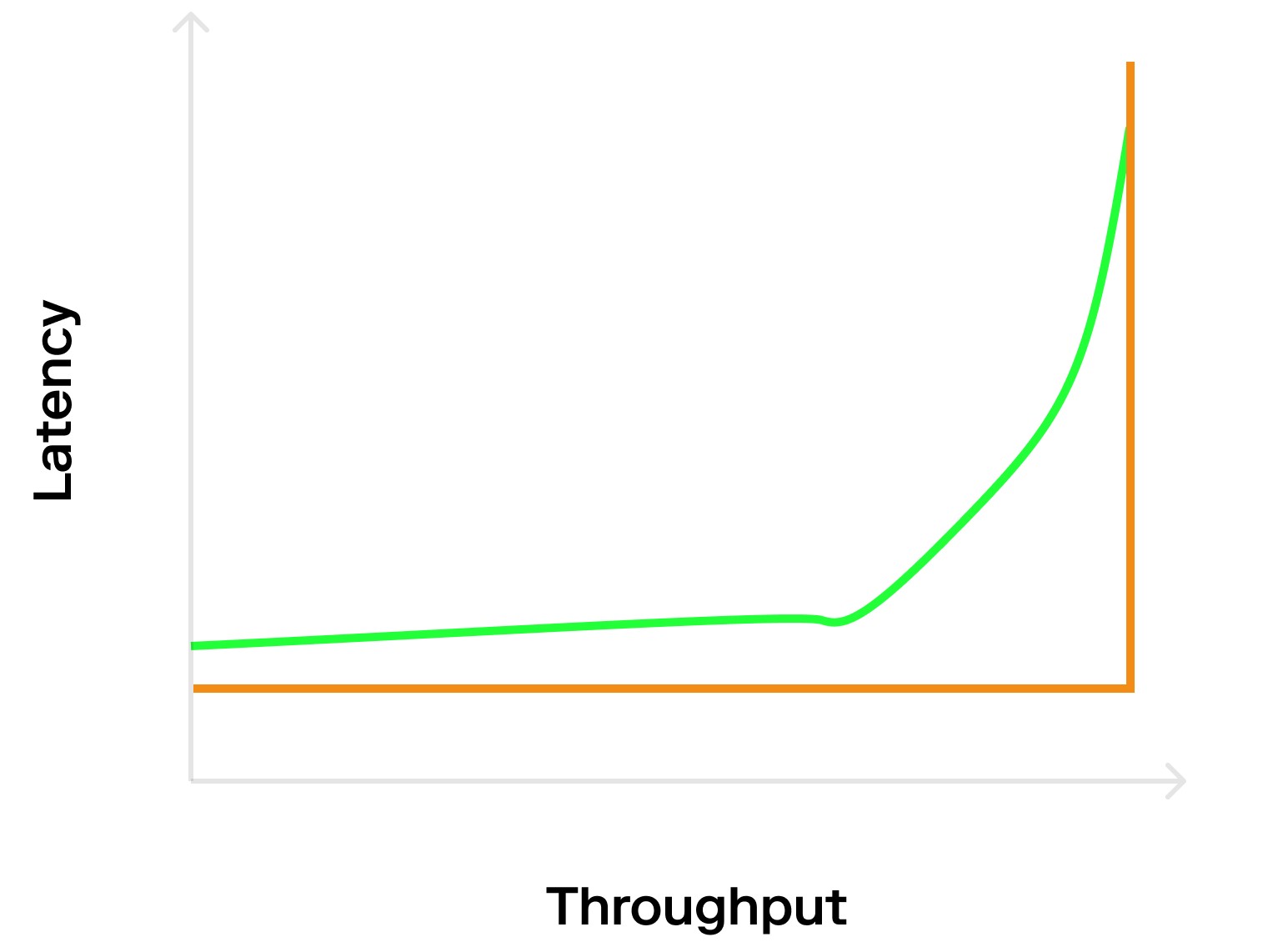
但是开放系统通常不会以这种可预测的方式运行。它具有高负载和低负载时期,我们可以以概率达到间隔分布地方式进行预测,该分布通常基于泊松分布。这将呈现「曲棍球棒」图(蓝线标志)因为即使平均速率低于最佳值,泊松分布到达间隔也会导致一些交易等待延迟。这样我们就可以观察到系统是如何处理高负载以及恢复到正常时的速度。
准备阶段
在选择开始时间时,最好保证通道中的交易处在满载状态,否则将会导致测量预热延迟。理想情况下,在准备阶段应该完成交易请求指令发出的延迟。这样有助于帮助测量结果遵循预期分布。
如何比较系统的各种部署
如果比较系统的各种部署是最后一个困难。困难在于延迟和吞吐量是相互依赖的,导致难以生成具有具有可比性的吞吐量 / 节点数图表。解决这个问题的最好方法是定义服务级别目标(SLO)并测量此时的吞吐量,而不是简单地将每个系统以最大吞吐量的方式运行,因为此时的延迟毫无意义。在吞吐量 / 延迟图上绘制一条与 SLO 延迟轴相交的平行线,并对线上的点进行采样标记,这是一种可视化的方法。
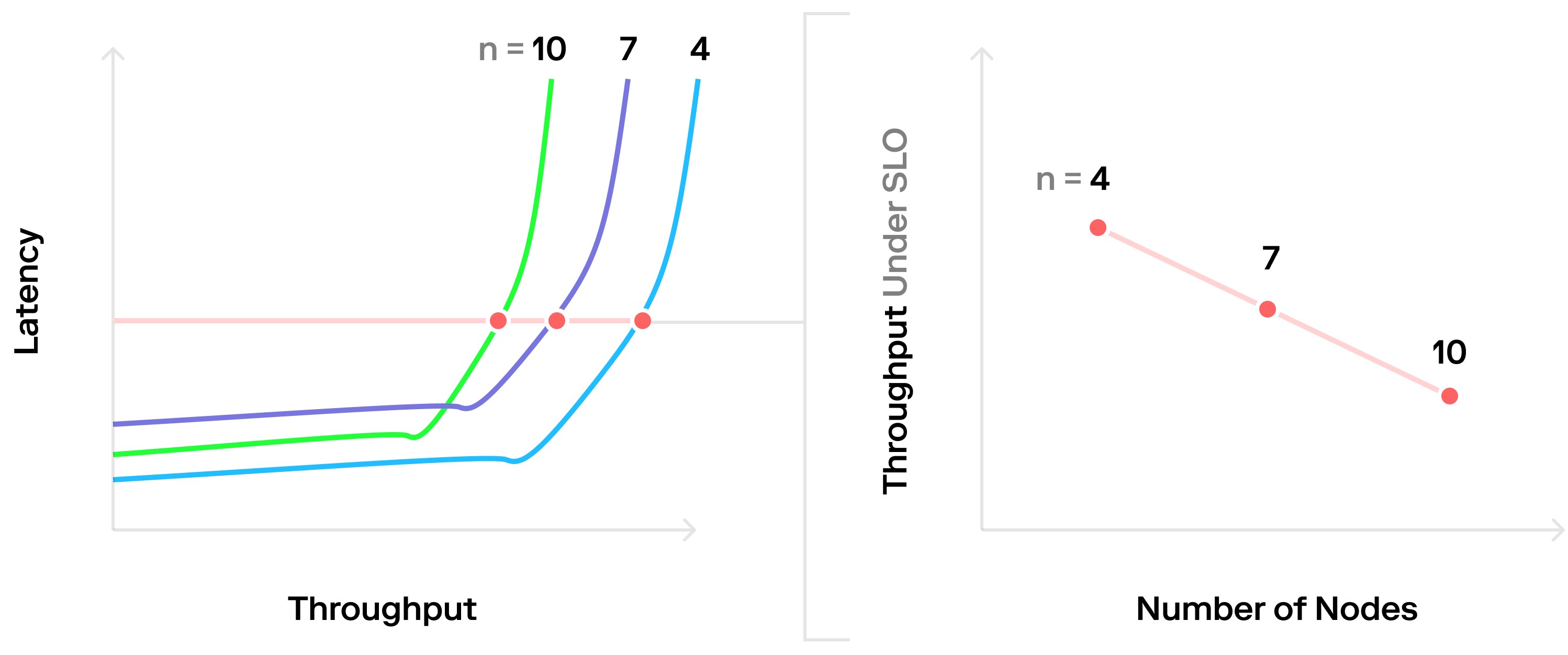
如果负载超过 SLO 会发生什么?
如果负载超过饱和点会很危险。如果系统操作配置不足,意外的交易请求将导致系统达到完全饱和,造成巨大延迟。在饱和点之后运行网络会处于一种不稳定的平衡,此时需要考虑两点:
- 升级系统配置:系统应该在饱和点一下运行,以便出现突发过量交易请求而导致延迟增加。
- 如果 SLO 下方还有空间,可以增加交易数量。这将增加系统关键路径上的负载,并提供更高的吞吐量和更优化的延迟。
当负载很高时,应该如何测量延迟?
当负载很高时,尝试访问本地并为系统中的交易请求添加时间戳可能会导致结果出现偏差。还有两个更合适的选择,第一种是也是最简单的方法,对交易进行抽样。例如在某些交易请求中可能存在一个幻数,而这些是客户端为其保留计时器的唯一交易请求。在交易发出后,任何人都可以在链上查看交易的提交时间,从而计算他们的延迟。这种做法的主要优点是它不会干扰导到间隔分布。但是由于必须修改某些交易请求,它可能被认为是「hacky」
更加系统的方式是拥有两个负载生成器,一个是主负载生成器,遵循泊松分布;一个是请求生成器,负载较低并用于测量延迟。通过这种设定,我们可以只测量来自请求生成器的延迟。这种方法麻烦之处在于实际到达间隔分布式两个随机变量的总和,不过两个泊松分布的总和仍是泊松分布,在数学上并不难。
结论
测量大规模分布式系统至关重要的是识别交易请求数量瓶颈和当网络处于超载下的预期行为。希望上述方法可以对区块链的网络完善做出贡献,最终优化用户体验。
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。



24H热门新闻
暂无内容