




Aptos 的 100k TPS 之路:状态同步
Joshua Lind热度: 21171
状态同步( state sync )是区块链设计中一个重要但经常被忽视的方面。在这篇博文中,我们讨论了 Aptos 状态同步的演变,并展示了最新状态同步协议设计背后的几个关键要点。
原文标题:The Evolution of State Sync: The path to 100k+ transactions per second with sub-second latency at Aptos
原文作者:Joshua Lind
原文来源:medium
状态同步( state sync )是区块链设计中一个重要但经常被忽视的方面。在这篇博文中,我们讨论了 Aptos 状态同步的演变,并展示了最新状态同步协议设计背后的几个关键要点。我们进一步探索了我们最近如何将状态同步吞吐量提高了 10 倍,将延迟降低了 3 倍,并继续为更快、更高效的区块链同步铺平道路。
今天的大多数区块链都是分层结构的,在网络的核心有一组活跃的验证器。验证者通过执行交易、产生区块和达成共识来发展区块链。网络中的其他对等点(例如,全节点和客户端)复制由验证器生成的区块链数据(例如,块和交易)。状态同步是允许非验证节点分发、验证和持久化区块链数据并确保生态系统中所有节点同步的协议。下面这张图向你展示了这在 aptos 上是如何工作的。
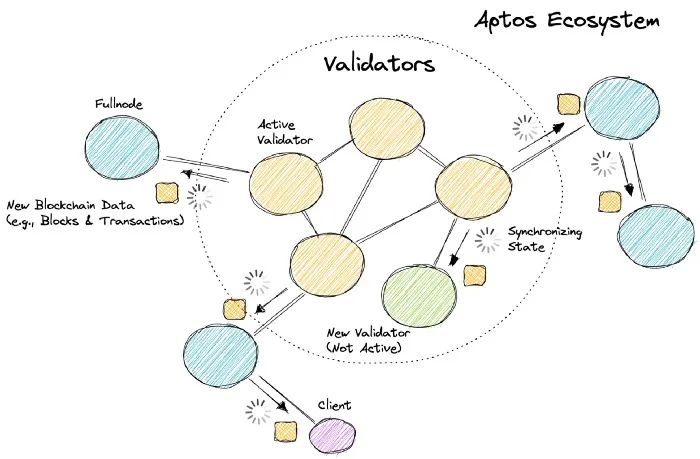 状态同步的重要性
状态同步的重要性
在评估区块链时很少提及状态同步:它通常只是白皮书中的一个脚注。然而,状态同步对区块链性能、安全性和用户体验有重大影响。考虑以下:
完成时间和用户体验:当验证者执行新事务时,状态同步负责将数据传播给对等方和客户端。如果状态同步缓慢或不可靠,对等方将感知到较长的事务处理延迟,人为地延迟了最终确定的时间。这对用户体验产生了巨大影响,例如去中心化应用程序(dApps)、去中心化交易所(DEXs)和支付处理都会慢得多。
与共识的关系:崩溃或落后于其他验证器集的验证器依靠状态同步来使它们恢复速度(即同步最新的区块链状态)。如果状态同步无法像共识执行的那样快速处理事务,则崩溃的验证器将永远无法恢复。此外,新的验证者将永远无法开始参与共识(因为他们永远赶不上!),全节点将永远无法同步到最新状态(他们将继续落后!)。
对去中心化的影响:拥有快速、高效和可扩展的状态同步协议允许:(i) 活跃验证者集的更快轮换,因为验证者可以更自由地进出共识;(ii) 网络中有更多潜在的验证者可供选择;(iii) 更多全节点快速上线,无需等待很长时间;(iv) 降低资源需求,增加异质性。所有这些因素都增加了网络的去中心化,并有助于在规模和地理上扩展区块链。
数据正确性:状态同步负责在同步过程中验证所有区块链数据的正确性。这可以防止网络中的恶意对等方和对手修改、审查或伪造交易数据并将其显示为有效。如果状态同步未能做到这一点(或做得不正确),全节点和客户端可能会被欺骗接受无效数据,这将对网络造成毁灭性后果。
状态同步的通俗解释
为了更好地解释状态同步,我们首先介绍了区块链执行的通用模型。虽然该模型专门针对 Aptos 区块链,但它可以推广到其他模型。
我们将 Aptos 区块链建模为一个简单的版本化数据库,其中每个版本V都有一个独特的区块链状态Sⱽ,其中包含所有链上帐户和资源。事务T可以由 Aptos 虚拟机 (VM) 在状态Sⱽ上执行,以生成状态增量Dᵀᵥ,表示Sⱽ上应提交的所有状态修改。当Dᵀᵥ应用于Sⱽ(即我们认为T已提交)时,它会产生新版本V+1和新的区块链状态Sⱽ⁺¹. 我们将第一个区块链状态称为创世状态S⁰。下图显示了事务执行和状态增量应用程序。
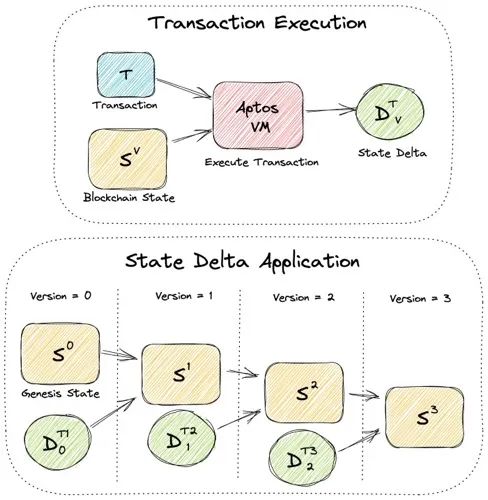 状态同步的目标
状态同步的目标
有了通用模型,我们现在可以为状态同步定义几个基本目标:
高吞吐量:状态同步应该使每个对等方每秒可以同步的事务量最大化。也就是说,对于验证者提交的每个T ,最大化从Sⱽ到Sⱽ⁺¹的状态转换率。如果吞吐量低,它会增加同步时间并成为网络的瓶颈。
低延迟:状态同步应该最大限度地减少更新节点同步验证器提交的新事务所需的时间。也就是说,对于验证者新提交的每个T ,最小化Sⱽ的对等方同步到Sⱽ⁺¹的时间。这会影响客户感知到的总时间。
快速引导时间:状态同步应该尽量减少新的(或崩溃的)节点同步到区块链最新状态的时间。也就是说,无论对等方的当前版本P和状态Sᴾ如何,最小化同步到Sⱽ(其中V是验证者同意的最高数据库版本)所需的时间。这允许对等方更快地执行有用的工作(例如,响应余额查询或验证交易)。
抵抗故障和恶意行为者:状态同步应该抵抗故障(例如,机器和网络故障)并有能力抵御网络中的恶意行为者,包括其他对等方。这意味着要克服各种各样的攻击,例如伪造交易数据、修改或重放网络消息以及日蚀攻击。
容忍资源约束和异构性:状态同步应该容忍资源约束(例如,CPU、内存和存储)并包含异构性。鉴于去中心化网络的性质,对等点将可以访问不同类型的硬件并针对不同的目标进行优化。状态同步应该考虑到这一点。
所需的构建块
我们接下来介绍一组构建状态同步协议所需的基本构建块。为简洁起见,我们在下面提供每个构建块的摘要,并将技术细节推迟到未来的工作中:
持久存储:为了在机器崩溃和故障中持久保存数据(并使数据能够分发到其他对等点!),我们要求每个对等点都可以访问受信任的持久存储。在 Aptos,我们目前正在使用RocksDB,但正在积极探索其他选项。
可验证的区块链数据:为防止恶意行为者修改区块链数据,我们要求数据经过身份验证。具体来说,我们需要能够证明:(i)验证者已执行并提交的每一笔交易T ;(ii)验证者执行和提交的每笔交易T的顺序;(iii)提交每笔交易T后得到的区块链状态Sⱽ。在 Aptos,我们通过以下方式实现这一目标:(i)在已提交的交易和由此产生的区块链状态上构建默克尔树;(ii) 让验证者对这些树的 merkle 根进行签名以验证它们。
信任根:鉴于 Aptos 支持动态验证器集(即在每个时期更改验证器),对等方需要能够从 Aptos 区块链的已验证历史中识别当前验证器集。我们通过以下方式实现这一点:(i)由 Aptos 认证的genesis blob,它识别第一个验证器集和初始区块链状态S⁰;(ii)最近的 可信航路点(例如,当前验证者集和区块链状态Sⱽ的散列)。起源 blob 和航路点一起形成信任根,允许对等方同步真正的 Aptos 区块链并防止攻击(例如,远程攻击)。
实现 1k TPS :简单版本
使用上面介绍的模型和构建块,我们现在可以说明一个简单的状态同步协议。该协议是 Aptos 使用的原始协议的简化版(即state sync v1)。
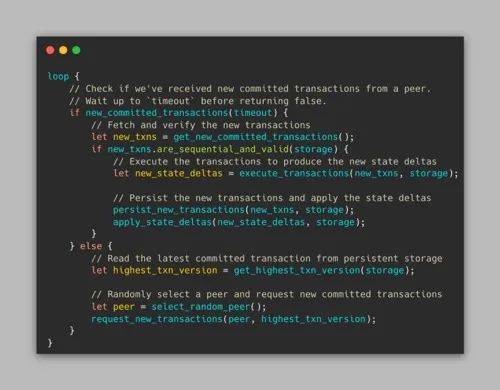
该协议的工作原理如下:
1)Alice(同步对等方)识别最高的本地持久区块链版本V和状态Sⱽ。如果不存在,则Alice使用 genesis,即S⁰;
2) Alice 然后随机选择一个节点—— Bob ——并请求验证者提交的任何新的顺序事务;
3) 如果 Alice 收到来自Bob 的响应,Alice将验证新事务(T⁰到Tᴺ)并执行它们以产生状态增量(D⁰ᵥ到Dᵀᵥ ₊ₙ);
4) Alice 然后将新状态增量与新交易一起应用到存储中,将区块链的本地状态从Sⱽ 更新为Sⱽ⁺¹⁺ᴺ。Alice 无限期地重复这个循环。该协议的代码如下所示:
 我们在 Aptos 实现了这个协议,在devnet上对其进行了基准测试,并对其进行了分析。我们所做的一些关键观察是:
我们在 Aptos 实现了这个协议,在devnet上对其进行了基准测试,并对其进行了分析。我们所做的一些关键观察是:
吞吐量受网络延迟限制:此协议最大可达到~1.2k TPS. 但是,吞吐量受到网络延迟的严重影响,因为Alice请求数据是按顺序请求的,并且必须等待对等方响应。鉴于我们在devnet中看到平均网络往返时间 (RTT) 为 150ms,这是次优的。
CPU 由执行主导:当Alice接收到一组新的要同步的事务时,我们看到55%CPU 的时间花在执行事务和40%的验证数据、将状态增量应用于存储和持久化新事务上。另一个5%归属于消息处理、序列化和其他任务。
延迟很高:在最大负载下运行网络时,Alice接收新事务的平均延迟是~900 ms在它们被提交之后。这主要是由于Alice在请求数据时随机选择对等节点而不考虑网络拓扑:离验证者较近的对等节点将更快地收到新交易。
引导很慢:上面的协议需要Alice重放和同步自创世以来的所有交易。如果Alice远远落后于最新状态,她必须等待很长一段时间才能做任何有用的事情(这可能需要几个小时甚至几天!)。
性能很容易被操纵:该协议的性能受到恶意对等方的严重影响。如上面 1 中所述,故意缓慢(或无响应)的对等方将迫使Alice花费很长时间等待数据而不做任何事情。因此,显着增加了同步时间。
资源使用率高:该协议对所有资源类型都很昂贵:CPU 使用率高,因为Alice必须重新执行所有事务;存储量很大,因为Alice必须存储自创世以来的所有交易和区块链状态;网络使用率很高,因为Alice必须通过网络接收自创世以来的所有交易。这会自动带来高成本和资源需求,从而减少异质性。
资源被浪费:在Alice同步新数据的同时,网络中的对等点也在从她那里同步。随着请求数据的对等方数量的Alice增加,处理这些请求所需的存储和 CPU 上会增加额外的读取负载。但是,为处理这些请求而执行的大部分计算Alice都是浪费的,因为对等方通常请求相同的数据。
实现 10k TPS :优化版本
看看上面的朴素协议,我们可以做一些修改来帮助解决这些限制。首先,我们扩展协议以支持 2 种额外的同步模式:
状态增量同步:鉴于验证者已经执行交易并通过 merkle 证明证明生成的区块链状态,节点可以依赖验证者产生的状态增量来跳过交易执行。这避免了:高昂的执行成本,将 CPU 时间减少了大约55%;对 Aptos VM 的需求,极大地简化了增量同步实现。因此,对等点现在可以通过下载每个事务T和状态增量Dᵀᵥ并将它们应用到存储以生成新状态Sⱽ⁺¹来进行同步。我们注意到,这是以增加网络使用量为代价的(大约2.5x)。
区块链快照同步:鉴于验证者证明了每个区块链状态Sⱽ,我们可以通过允许对等方直接下载最新的区块链状态(而不必使用交易或状态增量生成它)来进一步减少引导时间。这显着减少了引导时间,并且与以太坊中的snap-sync方法类似。权衡是节点不会在Sⱽ之前存储任何交易或区块链状态。
接下来,我们实施了一些常规优化和附加功能,以帮助提高性能和可扩展性:
数据预取:为了防止网络延迟影响吞吐量,我们可以执行数据预取。对等点可以在处理其他对等点之前从其他对等点预取交易数据(例如,交易和状态增量),从而分摊网络延迟。
流水线执行和存储:为了进一步提高同步吞吐量,我们可以将事务执行与存储持久性分开并使用流水线:处理器设计中常用的优化。这允许在事务T¹和状态增量Dᵀ¹ᵥ同时持久化到存储时执行事务T² 。
对等点监控和声誉:为了提高可观察性并更好地容忍恶意对等点,我们可以实施对等点监控服务来:监控对等点的恶意行为(例如,传输无效数据);识别关于每个对等点的元数据,例如对等点拥有的所有交易数据的摘要以及它们与验证者集的感知距离;为每个对等方维护一个本地分数。然后,此信息可用于在请求新的区块链数据时优化对等点选择。
数据缓存:为了减少存储上的读取负载并防止状态同步在越来越多的对等点同步时执行冗余计算,我们可以实现一个数据缓存,将通常请求的数据项和响应存储在内存中。
存储修剪:为了防止存储随着时间的推移而持续增长(例如,随着更多事务的提交),我们还可以实施动态修剪器以从存储中删除不必要的事务和区块链数据,例如任何超过几天、几周或几个月的数据,取决于对等配置。
我们实现了这些修改并产生了一个新的状态同步协议(即state sync v2)。我们在devnet上对其进行了基准测试并观察到:
吞吐量提高了5倍到10倍:在执行事务时(没有并行执行),协议现在达到了最大值~4.5k TPS,这主要是由于流水线和数据预取(即,协议现在能够使 CPU 完全饱和)。当同步状态增量时,协议可以很好地10K TPS完成,避免事务执行的进一步结果。在这两种情况下,吞吐量都不再受网络延迟的影响。
延迟减少了3倍:在以最大负载运行网络时,我们现在看到Alice接收新事务的平均延迟是~300 ms在它们被提交之后。这是由于数据预取和更有效的对等点选择:响应速度更快且离验证者更近的对等点会被更频繁地联系。
引导速度明显更快:使用区块链快照同步的节点能够更快地引导。此外,引导时间不再受区块链长度(即交易数量)的影响,而是要同步的链上资源数量。目前在devnet中,对等点可以在几分钟内启动。
减少资源需求:通过多种同步模式和存储修剪,减少了资源需求。此外,现在支持异质性,因为对等方可以灵活地选择同步策略。例如:CPU 受限的节点可以跳过事务执行;存储有限的对等点可以将修剪器配置为激进;希望快速更新的节点可以执行区块链快照同步。
资源使用效率更高:在处理来自对等点的同步请求时,我们发现存储上的读取负载显着降低,CPU 浪费更少。这是由于新的数据缓存将通常请求的数据项和响应存储在内存中。我们还看到,随着devnet中同步对等点数量的增加,数据缓存变得更加高效,例如,对于同步对等点,我们看到每个请求20的缓存命中率。70%-80%但是,对于对等点,60我们看到缓存命中率为93%-98%. 这是以额外的 RAM 为代价~150 MB来维护缓存的。
100k TPS 及以上?
虽然我们已经将吞吐量提高了 10 倍,延迟提高了 3 倍,但我们意识到还有更多工作要做。特别是如果我们想匹配Block-STM并使Aptos 成为每个人的 Layer 1!
那么,我们将如何到达那里?好吧,我们已经开始了我们的下一个状态同步目标:100k+ TPS!虽然,我们计划在未来的文章中再详细解释这些信息,但我们想为热心的读者提供一些提示:
交易批量处理:目前,Aptos 将每笔交易视为可验证的,即用于验证和验证数据的默克尔证明在交易粒度上运行。这使得验证和存储变得异常昂贵。避免这种情况的一种方法是执行交易批量处理,即对交易的批次(或块!)进行证明。
网络压缩:网络带宽经常成为点对点网络的瓶颈,Aptos 也不例外。目前,状态同步预取器可以在带宽饱和之前~45K TPS在devnet中取回。如果我们想扩大规模,这是一个问题。值得庆幸的是,我们已经认识到对等点正在使用低效的序列化格式分发数据,并且通过使用现成的压缩,我们可以将传输的数据量减少超过10x.
更快的存储写入:目前,将区块链数据保存到存储所需的时间成为状态同步吞吐量的瓶颈。我们正在积极寻找不同的优化和改进来消除这个瓶颈,包括:(i) 更高效的数据结构;(ii) 更优化的存储配置;(iii) 备用存储引擎。
并行数据处理:到目前为止,我们要求状态同步处理数据顺序(例如,处理顺序增加版本的事务)。然而,有许多现有的方法可以让我们避免这种要求并利用并行数据处理来显着提高吞吐量,例如区块链分片!
责任编辑:Kate
本内容旨在传递行业动态,不构成投资建议或承诺。


