



Celestia数据可用性
atom_crypto热度: 13107
Celestia遵从了Cosmos的理念,开放,独立主权,是专注于数据可用性的模块化公链,也做了共识(Tendermint)
原文作者:atom_crypto
原文来源:mirror
数据可用性

DA的提出,也是比较火热的话题。我们可以看到以太坊发展中的性能瓶颈,不仅是交易确认速度(十几秒),高手续费等。所以我们要拓展区块链的性能。以太坊社区里面的讨论方向包括,1)一个是L2,用Rollups做执行和计算,Rollups(执行层)的并行,加速链的效率;2) 第二个是链的扩容问题,目前链都认为区块扩容是最有效的处理整个网络效率的方案(State Bloat)。为了能够使得网络更好地被利用,Vitalik 在end game 中也提到过扩容(降低费用)和Rollups的方案的提出。但是随着扩容方案的提出,性能上升无疑也会给共识节点提出额外的要求,为了保证网络的安全性,验证节点通过(区中心化)验证的方式实现去中心化。共识节点,为了实现1)高性能 2)支持更多的rollups加入,需要通过验证的去中心化方式去实现(全节点 vs 轻节点)。数据可用性(Celestia)是非常契合这些要求的。以太坊合并之后第一步是推广的EIP-4844也就是Proto- Danksharding,以及danksharding 也是强调数据可用性这块,足可见社区对DA的重视。

DA 官方的解释就是通过数据抽样,保证数据在网络上的可用性。数据可用性如何理解呢?回到之前的点,可以理解下之前提到过的去中心化验证。本质上就是轻节点在不参与共识的情况下,不需要存储全部数据,也不需要及时的维护全网的状态。对于这种节点,需要高效的方式确保数据可用性和准确。接下来介绍下DA与共识在数据安全上的差异。因为区块链的核心在于数据的不可更改。区块链能够保证数据在全网的数据是一致的。共识节点为了保证性能,会有更为中心化的趋势。其他节点需要通过DA获得经过共识确认的可用数据。这里的共识(交易内容以及交易顺序的一致性)与其他网络的共识(交易的排序,验证等)并不完全一致。
Celestia 介绍

Celestia遵从了Cosmos的理念,开放,独立主权,是专注于数据可用性的模块化公链,也做了共识(Tendermint)(没有提供执行环境)。主要有以下几个特点:
1)为Rollup提供数据可用性
2)提供结算,共识层分离,需要打造第三层的结算,如果有些应用自己做结算,也是可行的。3)数据可用性的解决方案。二维纠删码+欺诈证明
4)对于轻节点提供高安全性的服务,可以通过欺诈证明,得到相对准确的,被验证,被网络认可的有效数据。
下文介绍包括 Celestia 工作流程、与Danksharding对比、近期大家关心的话题、Mamaki测试网的现状、Optimint、Celestia应用方式、系统的验证、Celestia的费用、社区解答等环节。
Celestia工作流程
Celestia的实现思路主要分为三个部分讲解,与其他链相似的共识,P2P的交互就不介绍了,这里主要着重讲下差异点:
1)区块构建上的一些差异。首先定义一个个shares。shares中包括交易以及这批交易相关的证明的数据。Cosmos SDK (质押,治理,账户体系),Tendermint里面的共识和执行是分开的。 Celestia本身是没有执行层,也没有结算层。所以交易和状态的关系在Celestia中和以太坊是不一样的,以太坊的状态是交易执行完成之后对整个状态树的变更。而Celestia设想的状态不是交易执行,而是交易整个存储在链上的状态。(share)之前的实现他们已经推翻了,在找新的方案。这个shares 很关键,欺诈证明,抽样都需要。所以Shares可以理解为交易及交易相关的证明数据,构建成了一个固定长度的,固定格式的数据块。

Shares 介绍完以后,就是他的区块和其他链的区块的区别,就是他的data root是什么呢。Data Root我们这里也是按照白皮书来说明(可能跟实际实现不同,只是讲概念)。这个图是2K2K的矩阵。首先看下这个矩阵如何来的。首先是KK的矩阵,K是设定的参数,随时可以修改。我准备好了KK的矩阵之后,我会把之前的shares,包含交易相关的数据,每个shares 放在矩阵的格子里面。这样我会把kk矩阵的格子填充起来。不够的话就补足,补一些无效数据。如果够了的呢,就等下一个区块。这个K的大小意味着Celesita, 单个区块可以容忍的最多的交易容量,即区块容量。Shares里面这个交易可以是一笔,也可以多笔,同一个批次。固定长度意味着交易是有上限的。KK确定了Celestia的单个区块的容量。具体多大需要关注其发展。把这个shares放在KK矩阵之后,首先通过横向的reed solomon的方式进行拓展,从KK变成2KK的矩阵。KK是原始数据,扩展数据是2KK减原来的K*K=K’K’。然后再把原来的KK做纵向扩展,得到K”K”,再把K”K”做横向扩展。通过这种编码方式,最终得到2K2K个行列的方阵,就把shares 编码到了data里面。这个data的构成就是这样进行的。DataRoot是什么呢。我们看到2K2K的矩阵,我们可以把每个行每个列都构建成默克尔树。默克尔树就会有默克尔根。我们就会得到2k+2K的默克尔根。然后把24K的默克尔根再构建成默克尔树,最后得到默克尔树的根。我们就看到dataroot, 就是data的根。Data root放在状态头(区块头)中。Celesita的DA都是围绕DATA root来的,区块的比较关键的数据是Data Root。怎么确认数据和数据相关的交易,怎么生成这些shares,目前在重构。
2)既然我们已经在区块头中准备了这些root,接下来我们看看DA是如何工作的。
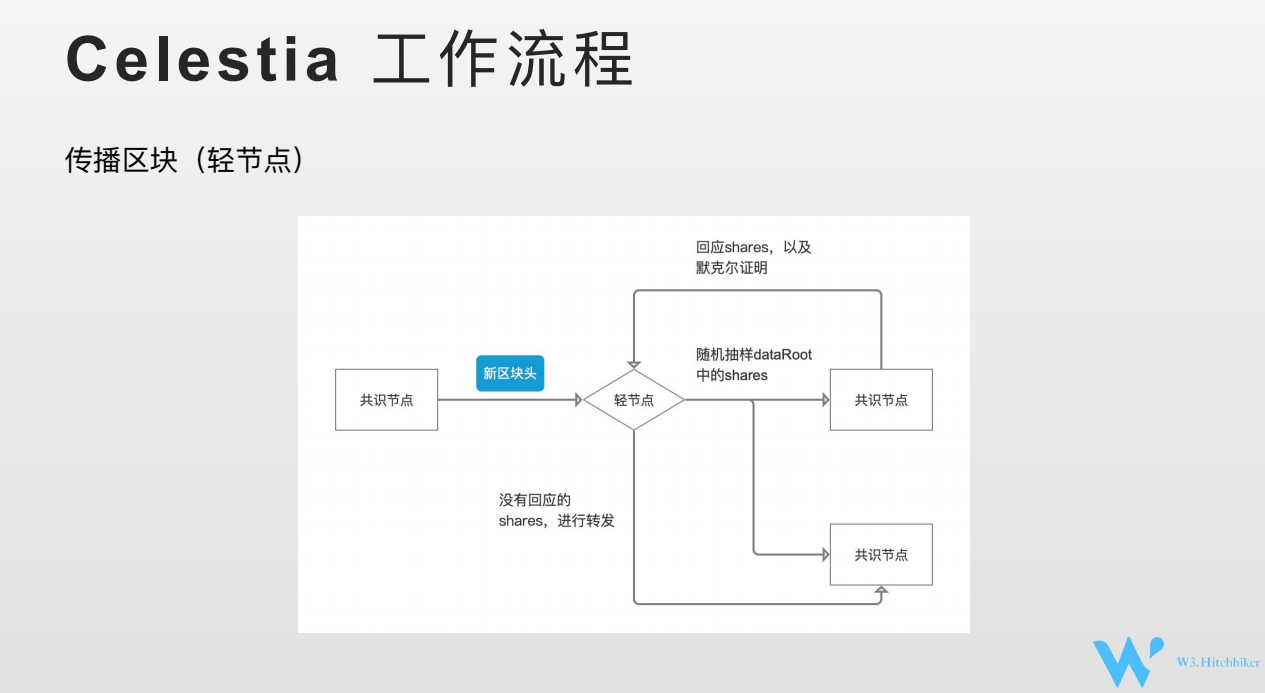
共识节点和共识节点的交互这里就不具体阐明了,P2P的方式。DA涉及到的是共识节点和轻节点的交互问题。不能参与共识的节点统一称为轻节点。传播主要看DA 和轻节点之间的流程。我们看是如何交互的。共识节点经历过一段共识 (数据确认)之后,会产生新的区块,会把区块头,包括data root 发送给轻节点。轻节点收到data root之后。就需要进行随机采样,我们看到2K2K矩阵,在2K2K矩阵中其中挑选一组坐标,打包成一组集合。这个集合就是本次抽样的一个集合。将抽样的集合发送给他们相连的共识节点。请求共识节点将坐标对应shares发送给轻节点。共识节点就有两种回复。一种我有你请求的,那么1)shares,以及2)shares在data root中的默克尔证明一起回复给轻节点,轻节点收到回复之后,会去做默克尔证明,证明这个shares 在这个data root里面的,之后就会接受shares。当他把他的抽样都收到回应之后。这个时候就基本上认可了这个区块,认可了这个数据是可用的。Dataroot都是链的交易,能够回应就说明了这些Data 在网络上都是被共识节点认可的。如果某个共识节点没有回应,轻节点会把我收到的相关shares 转发给对应的共识节点,帮助整个网络快速的收敛。P2P网络,网络的扩大,共识节点确实收不到/收到比较慢共识结果。我轻节点可以通过这个机制,快速帮助对网络的传播。
有个问题,轻节点抽样一组坐标,没有说抽样多少个,2K*2K, 二维纠删码,只要抽样K*K, 是可以完全恢复过来的。为什么没有明确的要求轻节点抽样这么多个。为什么没有明确给出呢。如果我们整个网络只有1个轻节点,确保数据一定被恢复过来,那么需要抽样KK,才能保证恢复原始数据。而实际上对于一条网络,肯定会有N个轻节点,可以将任务分摊给N个节点。官方官方文档也给到了计算公式。你抽样多少次,抽样多少个,和你得到数据可用的概率的计算公式。轻节点可以需要根据安全等级需求,选择自己去做一个数据采样的决定。同时在Celestia中,轻节点越多,块越大,网络执行效率就越高。如果只有1个轻节点,采样数据至少KK个。 如果有K*K的轻节点,理想情况下采样不重复,每个节点只需要抽样1次就可以了。整个网络的性能,每个节点的带宽,性能是一致的。节点越多,意味着抽样的总数越大的。这也可以解释节点越多,网络效率越高。
欺诈证明,为什么需要有欺诈证明,我们有了纠删码,抽样,理论上获得的数据。比如说我从十个共识节点抽样获得的数据,通过纠删码可以确定这些数据是十个节点给的。但是这个地方会有些问题,就是这十个节点都有没有给我们正确的数据,我们怎么来做呢。纠删码只能证明这些数据是他们想给我们的。但是需要验证他们想给我们的数据是否是正确,那么欺诈证明确保共识节点是按照设想规则给我们编码的。这就是为什么我们需要欺诈证明。欺诈证明就是来解决这些问题。证明节点通过抽样获得shares,恢复的数据到底是对的,还是无效的。
欺诈证明的组成有三个点。
1)我这次欺诈证明是挑战哪个区块的数据,欺诈证明是乐观的,有一定滞后性的,不一定是对当前块发起的。有可能是对前面几个块。
2)我这个欺诈证明,我要指明你的哪个shares出错了,我要把你出错的shares指出来。以及shares所在行/列的的根以及默克尔证明告诉我,共识节点按照我们设想的规则。
3)我告诉你他的默克尔证明,还需要(有错的share所在的)行/列至少K个share,有了K个以后就能够把行恢复出来的。从而可以进行验证。
接下来我们介绍下欺诈证明是如何交互的?
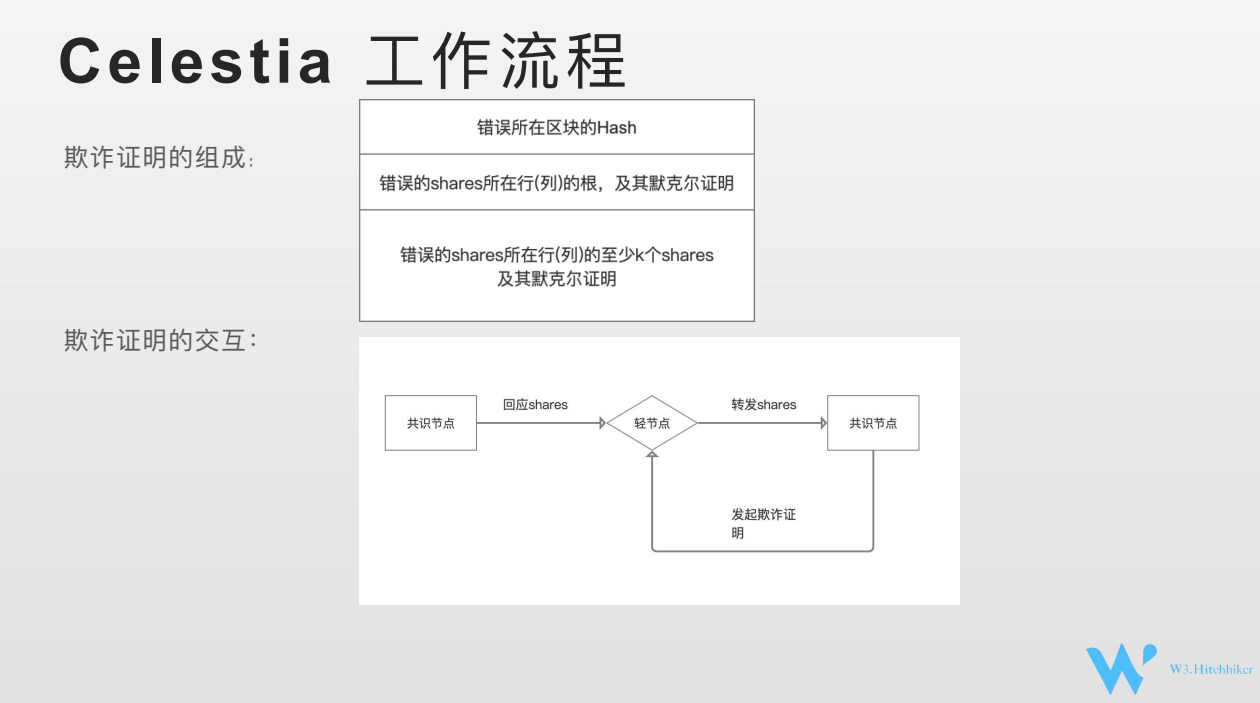
共识节点给轻节点回应请求的shares数据,轻节点会把shares发送给其他共识节点 (请求其他共识节点帮助验证)。其他共识节点,会判断shares和本地数据是否一致,如果不一致,会发起这个欺诈证明。如何判断欺诈证明的有效性呢?需要进行验证。
1)指定的区块哈希(data root)是我本地有的。你错误的shares,你要把你的shares 的根和默克尔证明告诉我,我做一个验证。
2)你这个shares 的行和列的根确实在我这个data root里面。
3)我会把你给我的shares通过纠删码的方式把整个行恢复过来。跟我本地数据做一次对比,发现数据和我的数据确实不一样。
通过这三种方式,能最终确认欺诈证明是有效的。之前给我shares的共识节点是有问题的。我需要将其列入黑名单,不再接受其发送的任何shares。
这就是欺诈证明交互的流程。到这里,对于DA,数据可用性流程就差不多了。
我们总结下。DA 通过二维的 RS 纠缠码,对于交易数据,shares 进行一次编码,编码之后生成了data, 这个data在共识节点 非共识节点之间通过采样的方式来获取data 数据。获取data数据之后,就可以恢复,可以确认这个data 数据是可用的。比如Rollups恢复自己的交易,去做计算。同时,纠删码,只能保证数据是对方想给的数据,引入欺诈证明,保证对方给的数据是按照预想的规则进行编码。有效的数据,通过这两个部分,一起才能对轻节点,提供快速验证并获取数据有效性的方案。
和Danksharding的对比:

Danksharding 和Celestia的对比。都是通过二维RS纠删码进行编码。但是采用了不同的路径。Danksharding, 用的是KZG 多项式承诺。KZG多项式承诺对于一个多项式他能够提供承诺,证明某个X Y 的 f(x)=y 证明某一组 x y 恰好就是多项式的根,根意味着这个点是经过多项式曲线的。同时,验证者不需要知道多项式的具体内容,也不需要具体去执行这个多项式,能够通过一个简便的方法, 交易证明就能得到,XY就是多项式的一组解的事实。KZG多项式承诺,比较契合RS编码,这里面涉及RS纠删码的实现。RS纠删码的实现把K份数据扩展到2K。怎么把K份数据扩展到2K呢。我们有K份数据,进行排序之后,简单理解为他的索引,对应就是XY。K个点,通过数据计算,傅里叶变换等,可以得到K-1的多项式。可以把这个多项式的图在坐标轴画出来。前面0到K-1是原始数据,我们可以扩展后面K个数据。这2K个数据 任意拿K个,都可以恢复整个多项式,那么意味着可以恢复2K个数据,那么我们可以恢复前面K个原始数据。多项式承诺恰好是对一个多项式以及多项式的证明。他的优势1)比较契合二次编码。2)大小证明是48字节(固定)。3)因为采用了及时证明,轻节点拿到证明,可以立马进行验证,交易的确认是及时的,不像乐观证明,需要等一段时间,如果没有人发起挑战,我才能确认这个交易是OK的。这是KZG承诺的一个优点。
Celestia的欺诈证明是乐观证明,最大优点是我是乐观的,只要这个网络没有人出错,效率是非常高的。没有出错的话,我不会有欺诈证明。轻节点不需要做任何事情,只要收到数据,按照编码进行恢复,整个流程不出问题的情况下,非常高效的。数据可用性上面的一个加分顶。
Danksharding 除了数据可用性以外,PBS。PBS是解决MEV问题。把出块和共识矿工角色分开。PBS这个方案限制了区块打包者审查交易的权利,Crlist也参与了这个工作。这部分和DA相关性不大。Celestia目前没有考虑结算层,MEV 还没有考虑。总结下,Celesita是围绕数据可用性的公链,没有执行性,结算层,所以整个网络的容量用在在数据可用性上。以太坊danksharding 不仅仅是数据可用性,还有结算层。
近期热点话题讨论:

刚才必成将的问题需要纠正下, data root 不是2K*2K根,是2K+2k个根。欺诈证明这块,Celestia 还有个最小诚实节点假设,这意味着当轻节点连接到一个诚实验证者的时候,就能保证安全。这种情况下拜占庭是不能工作的(⅔)。最新的情况更新下:以前认为多个交易放在一个share里面,现在是一个交易分成多个shares。
最近团队第三次电话沟通会议也解释了danksharding的差异。技术上,上文我们已经做了介绍。而从用户角度来讲,有以下差别:
1)区块大小。相较于以太坊的blob, 每个区块16M。Celestia 承诺会达到100兆的大区块;
2)Celesita专注于DA, 块的元数据 (辅助数据)较少,和执行有关的数据比较少。门槛费理论上略低于ETH;
3)Rollups的主权的问题,Celestia偏向于自由,Rollups需要确保自主安全性。ETH有合约检查Rollups提交的数据的有效性;
- Celestia 通过命名空间的方式,确保你不用获取主链上全部的数据,你只需要获取跟你rollups有关的数据就可以了。
Mamaki 测试网

目前没有激励,年底或者明年初可能会有,下一次测试网的升级大概在十月,计划中更多的是服务开发者,现在的测试网主要是给大家体验Clestia的工作方式。测试网现在节点工作都是正常的。崩溃之类的bug现在已经比较少了。节点能正常运行。轻节点工作情况还不错,符合预期。比如减少下载数据量,执行效率高等。网络方面可能需求稍微高些。主链的运行不太稳定,经常出现卡顿的情况,出一个块需要五分钟,十分钟。出块的顺序, 本来在Tendermint机制中,根据质押数决定出块概率,在抵押额差不多的情况下,应该轮流出,但目前经常会有验证者连续出3–4个块。
目前看到的问题:
1)验证者节点的进入和退出,不管抵押多少,哪怕小的验证节点退出都会造成网络不稳定。
2)不能连接太多的对等节点,只能连接少量的节点,相对比较稳定的节点;
3)交易量不大的情况下,出块时间为五十秒/块,让人担忧之后的吞吐量。目前还比较早期,优化空间还比较大。
4)桥接节点问题比较大。中秋期间,我们节点重启后,发现内存和网络都发生了暴涨的情况。我们也尝试联系了其他验证者节点服务商。有的桥接节点内存已经跑到了个20个G,非常不正常。Celestia落盘的数据量是14个G,桥接节点理应是不存储数据,内存用到20个G,是比较明显的问题(原因还在研究)。

Tendermint是做一个共识。Optimint是Celestia rollup用的。目前市面上的rollups只有一个排序者。不需要做共识,只是比较简单地把排序者打包的数据上传至主网。如果以后rollups也需要做共识的话,还是应该在Tendermint上改吧。做共识的难度还是比做一个数据上传难度大很多的。所以这两个是没有竞争关系的。
合约方面,Celestia目前考虑执行比较少,它也是借用现成的CosmWasm这个技术(和Cosmos结合比较好,现在也是属于一个可用的状态)(将来还可能有Move VM EVM等)。目前做了两个示例, 受到主网不稳定的影响比较大。提交交易有时候需要10分钟,用户体验不太好。
Optimint 和App (Cosmos App是应用链的形式实现) 目前连接通过ABCI,链自己的交易要用共识引擎,上传功能是通过ABCI,以后还会添加其他方式。
现在节点之间的硬连接(tcp连接)是GRPC,技术比较先进。但用的比较多,兼容性更好的是Rest等方式。还有一点点不完善,在补全的过程中。

讲下系统的验证。轻节点不用下载所有数据,就可以验证数据有效性。因为做了4倍纠删码的扩展,它可以保证很高的可靠性。
1)那么如何保障抽样的可靠性如何呢,比如100行*100列,那就是100,00个shares。但每抽样一次,不是万分之一的保证。扩展四倍意味着在整个share至少要有1/4的share不可用,你才可能抽到一个不可用的share, 才表示真正不可用,因为恢复不出来。只有在1/4不可用的情况下才恢复不出来,才是真正有效的发现错误,所以抽一次的概率大概是1/4。抽十多次,十五次,可以达到99%的可靠性保证。现在在15–20次的范围之内做选择。
2)Celesita有没有正确在做DA 验证。比如你一个rollups,你把数据传到Celesita,ETH有合约验证交易的有效性,而Celestia 返还给rollups节点以后,再去验证数据。
这里讲下节点的角色。比如节点在rollups 是什么角色,在Celestia上可能是另外的角色。比如他可能是rollups上的轻节点,全节点,但是可能都是Celestia上的轻节点。只需要作为轻节点,就能够获取数据,没必要像在以太坊中一样重新做一个全节点,可能相对于ETH现在的方案,更为优势些。ETH如果要验证数据发送到主网,你需要启一个主网的全节点。Celesita只需要轻节点。轻节点的话,那么就是说抽样保证可靠性。
刚才提到的最小诚实假设意味着你作为轻节点,只需要连接一个诚实节点,就能保证安全性,如果你连这个都不信呢,万一一个诚实节点都没连上呢?那么你可以启动一个rollups的全节点,你把你rollups的数据全部拿来,跟你的排序者发布的root做一个校验。关于Rollups自己状态的验证,Celesita没有执行能力。比如你账户余额,需要自己验证。如果你的排序者作恶,发两个块高一样的块至Celestia,Celestia只是保证把他发来的这两份数据都发给你Rollups的节点, Rollup节点收到两个块高一样的数据,现在ETH遇到这种情况,那就是分叉了,怎么处理,Rollups自己负责了。
Celestia的费用有两部分

1)Rollups自己的字节费用和执行gas。如果以太坊作为执行层,用ETH结算。
2)Celesita保存交易数据的费用(排序者,自己打包支付,你如何从其他节点,或者说Rollups用户怎么把钱收回来,需要Rollups自己设计。)(可能还有状态根数据等等)。存储费用是celestia本币支付,架构上也支持其他币种。目前也做了更改。你上传的数据与支付的逻辑分开了。
3)目标是做到两部分的数据综合起来也要比单独把数据放在以太坊便宜。ETH是call data 比较贵。ETH做了danksharding之后,KZG 之后成本会更低。但是Celesita承诺费用更低。
4)存储方式 的选择更为灵活,Celestia, ETH,或者线下存储。

Celestia 应用的方式
1)直接上主网或者执行Rollups, 不太关心交易的顺序。让Celestia的验证者做交易排序,你没有主权。
2)主权rollups 排序者和Celesita打交道,其他节点从Celesita获取数据,执行,维护安全交给Rollups 自己
3)ER 直接构建在 L1 规范中,而不是作为智能合约部署。和ETH结合,ETH 作为Celestia结算层,其他rollups连接到结算层。可能不是直接到Celesita,通过结算层和Celesita打交道
4)量子引力桥,完全把Celesita作为ETH的外挂。
理论上都可以实现,ETH作为Celestia的结算层,或者Celestia作为ETH的DA层。可组合型,都是可实现的。
社区问答
1)Celestia有几种节点?
Q&A:Member A
Celestia上的全节点:存储节点,不是ETH 那种全功能节点。存储所有数据的节点。共识节点也好理解。轻节点也好理解。桥接节点,为了做DA, 要提供RPC服务,要给轻节点连接的服务,提供给轻节点做数据采样专门用的功能。这个专门做了节点叫做桥接节点:共识节点,全节点和轻节点间的二传手。类似于网关
2)Q&A: 命名空间是什么?
Rollup上传给Celesia, 存储在Celestia,而每个Rollups只想取自己的数据。命名空间是每个Rollups之间区分标志。Rollups取数据的时候带上这个标志,就可以仅取出自己的数据了。工作方式的不同:主权rollups 就是你把数据传送给我,我只需要验证交易数据签名是排序者的签名,认可你这个数据。我给你Rollups的服务,保证数据原封不动的传送给其他Rollups的节点。就完成了DA的工作。这是rollup的一种工作方式。还有另一种工作方式,ETH的Smart Contract Rollups由一系列合约来定义的。为了区分,给了不同的名称。
3)分片,扩展性如何解决?
区块就是纯数据,不做执行,处理能力比较高,没有很多验证。一个块100兆,现在看来还是有一定把握。纯二进制数据,不关心里面是什么,只要排序者签名,不管里面的内容。
4)Rollups 数据存了一份在Celestia上,数据可用,但是验证有效性,效率如何?抽样验证,会随着你的存的数据越大,成本变化越来越高吗,以太坊全节点几百个G, 将近1T (1T=1000G). 一个Rollups 未来数据量越来越大,所需要花的成本越来越多。其中关系有没有相关研究?
W3回答:Celestia 区块是有容量的,交易越多,成本越大,那么Celestia如何处理的呢? 首先其没有执行层,所有Rollups交易对于Celesita来说都是一段二进制,纯粹是一段数据,没有实际意义的。对于任何一个链,都是有一个容量大小的。 data root,K*K就是区块容量。怎么扩展区块容量呢,轻节点是可以帮助整个网络来收敛的。Celestia比较钟情于这种大区块。那么我怎么帮助整个网络大区块的传播。我会加速网络的收敛速度,轻节点越多。轻节点抽样的时候会进行二次转发。这个二次转发的过程加速整个网络收敛的过程,提高网络的效率。我的轻节点的带宽也是能够贡献出来的,帮助共识节点之间进行区块的传播。增加轻节点的数量,而不是单个节点的负载。
CFG Labs: DA区块大小就像互联网的带宽,是核心指标。每秒DA区块能容纳的bytes 越多,rollups执行层的交易就越多,区块链速度越快。每秒的bytes,从流量的角度来看就是bandwidth。
5)问:区块存储的数据变大,花费是否成线性关系?轻节点还要参与共识,成本增高,共识的时间也会增多?(时间,成本,实验结果)
回答:Celestia 是没有执行层的。我的共识是什么?我的共识只需要把数据搜集过来。数据确认好,顺序确认好,我的共识就完了。我的共识并不需要执行。那么随着数据量的增加,那么我的开销主要增加在哪里呢?一个是存储,一个是带宽。我的计算是没有的。我们有全节点,专门做存储的节点。还有轻节点是通过抽样部分数据帮助大区块P2P 传播。轻节点带宽帮助共识节点的交互。
问题:Celestia 采样,采样速度是否和数据区块数据区块大小无直接关联。100个区块中,采样 不同位置的10个点,100兆,1000兆,时间一样。消耗的费用更多?
回答:你提到数据量变大了,整体费用上升,而官方解释节点越多,处理量越大。我不知道你对这句话的理解是什么样的?我如果节点数量固定,我能处理的量就那么多了,但可以增加节点增加节点。所以这个轻节点网络扩展了处理能力,Celesita是用了另外一种方式缓解这个容量冲突的问题。Celestia 区块大小,随着轻节点数量扩展,这里的轻节点并不限于某一个rollups 的轻节点,而是指所有Rollups的轻节点共同参与这个事情(不管是哪个Rollups参与)。对于全网来说,成本越多, 但是轻节点分摊下来,每个采样的数据量不会有太多变化。比如说数据现在100兆,之后变为200兆。可能需要的轻节点数量也翻倍了。对于单个轻节点来说,成本不会太大。也是通过数量的扩展,对于单个轻节点,感知不到扩容问题的。对于轻节点的影响是有限的。100兆这样的块,还没达到极限。
没有这个东西,平方根是一个老早就有的,以讹传讹的东西,来源于最早的翻译者没有完全理解,不管区块多大,区块头里面,data root的大小根本不会变化。但以后可能会加上消息索引,那个会随消息数量变化,但是索引嘛,本来就很小,只有数据本身的几百分之一。
问题:存储节点,轻节点,出块节点,这几个节点的激励分配是如何?
W3: 费用考虑的不是特别多。轻节点主要是用户, Celestia存储费用可能分不到,其他与共识节点,存储节点,桥接节点,之间的分配。像我们目前搭节点是搭一套,我们目前也没有想过怎么给自己分钱这个问题。按照POS的机制,是根据抵押数量来决定。涉及安全和攻击,一定要平衡。
问题:执行层,DA层,Celestia和我们现有的方案,比如以太坊,zkrollups, OProllups, 还有Cosmos 其他生态项目,我自己比如想做rollups,应该如何部署?
回答: Celesita的应用方式有三种,如果直接上Celestia主网或者简单Rollups, 那么直接搭Celesia的全节点就好了。如果主权Rollups,就要考虑如何设计你的排序器,考虑如何设计自己网络的安全机制。排序器负责把数据传给Celestia,付存储数据的费用,你Rollups上的其他节点可以作为Celestia上的轻节点, 把数据从Celestia上取下来。你自己的链,做自己的业务,和逻辑。如果是量子引力桥,那是部署在ETH的合约,如果你是ETH的rollups,是不会和Celesitia打交道。
8)问题Cevmos 以太坊智能合约可以部署在Cevmos,Celesita + Cevmos +Rollups
Cevmos可以理解用来做执行层,结算。那么整个工作机制是怎样。
回答:Rollups上其他的节点从Celestia 取得数据之后,传给Cevmos上去执行,执行更新自己的状态。根据你的设计,因为你的排序者可能会执行,也可能不执行。如果要验证你的交易,打包,也需要将你的交易到cevmos中跑一下,确认你的交易是有效的,然后再打包,上传。这取决于你自己的rollups怎么去设计这个机制。Rollups将交易发给排序者,排序者将交易上传至Celestia,你的其他节点再从Celestia上把数据取下来,你再通过一个执行的虚拟机去执行。这是整个循环过程。结算层主要解决不同资产之间的交换问题,并且提供了安全保障(比如以太坊)。不同链间的资产交换需要搭桥(可信任桥和最小信任桥),需要共同结算层。目前典型的Rollups 只有一个排序者,未来会引入共识机制,比如Tendermint,Avalanche等方式,可以实现自主设计。
责任编辑:MK
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。


