



模块化结构下 EIP-4844 的设计逻辑
Protolambda热度: 13054
L1 作为一个为 Rollup 保驾护航的基础层,它不仅可以为 rollup 提供安全保障,还可以充当 rollup 的数据层,让可扩展性实现指数级的提升。
注:本文基于 Optimism 团队研究员、前以太坊基金会研究员 Protolambda 于今年 7 月在 EthCC Paris 所做的演讲进行编译,并参考了其他优秀的文章进行整理 (在文末列出)。
引入
合并 (The Merge) 的关键里程碑已于 9 月 15 日完成,根据 Vitalik 在 2021 年底发布的以太坊协议开发路线图,下一个重要阶段是 The Surge —— 解决以太坊可扩展性问题,降低交易费并提高吞吐量。The Surge 围绕以 rollup 为中心的路线图开发,在继承以太坊网络安全性的同时,进一步提高 L2 rollup 的可扩展性。
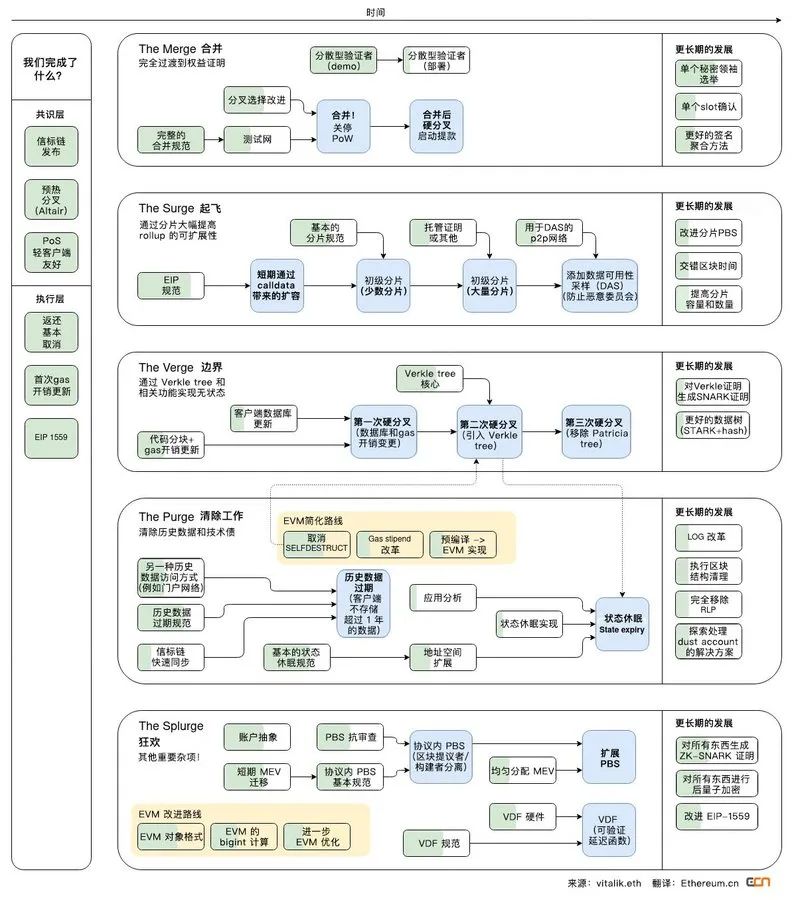 cr:https://twitter.com/ethereumcn/status/1466731320537612296?s=46&t=9yOAkX-0nd_xvSJIJ8_Pmw
cr:https://twitter.com/ethereumcn/status/1466731320537612296?s=46&t=9yOAkX-0nd_xvSJIJ8_Pmw
本文主要介绍这一技术路线图中的一个关键工作:EIP-4844 Proto-danksharding,它如何使得 rollup 所需要使用的数据变得更加便宜以及获得更多存储数据的容量 (capacity)。EIP-4844 是对以太坊网络的一次升级,它将使得 rollup 的开销降低 10-100 倍。它通过向以太坊引入一种新的交易类型来实现,这种交易类型携带短暂存在的 blob 数据。这种新的数据存储方式是为了存放 rollup 的一些数据,它会比目前 calldata 的方式便宜得多。此外,4844 是完整版 Danksharding (在前面的基础上再扩容 10-100 倍!) 的前提条件。
以太坊分片技术路线图
对于以太坊分片设计的现状,前以太坊基金会开发者 Protolambda 做了一个简洁的描述:
带有 “crosslink” 的可执行的 “分片链” 已被淘汰,而是更新为:在信标链中实现 EVM;使用 “数据可用性采样” 的以 rollup 为中心的以太坊路线图,扩容以太坊基础层而无需增加应用环境的复杂性。
之所以做这样的简化,主要有两个原因:
- 避免添加更多的 L1 复杂性。分片的规范已重写多次,许多研究都过于抽象乃至实现的日子遥遥无期,并且让 L1 变得僵化。
- 而如果能够巧用封装复杂性和应用区块链模块化结构,以太坊基础层作为 rollup 的数据可用性层,将计算的重任交给作为执行层的 L2。这样 L1 只专注于解决数据问题,不同的 rollup 团队解决各自的开发问题,从而大大地提升扩容的效率。
封装复杂性和模块化在以太坊上的应用
模块化区块链是扩容中一个非常重要的概念。模块化意味着“封装复杂性”,这允许我们在不同的模块中添加可扩展性。根据 Vitalik 的文章《协议设计中的封装复杂性和系统复杂性权衡》中的解释,当一个系统包含着一些复杂的子系统,但对外提供一个简单的“接口”时,就会出现“封装复杂性”;当系统的不同部分甚至不能完全分离,并且相互之间具有复杂作用时,就会出现“系统复杂性”。
2020 年 10 月,Vitalik 发布了文章《以 Rollup 为中心的以太坊路线图》,确定了为 L2 rollup 扩容协议保驾护航的基本思路:将执行层 (L2) 和数据层 (L1) 分离,以太坊共识层 (L1) 为其提供安全保障。
分离执行层和数据层的好处是,数据层的发展可以保持相对稳定,而执行层 (即 rollup) 则可以更加多自主性、更加创新地快速迭代,无需获得 L1 核心开发者社区的的许可进行升级。
上面简单介绍了以 rollup 为中心的以太坊路线图中的区块链分层情况,那在 PoW 与 PoS、L1 与 L2 之间的模块化架构是怎样的呢?
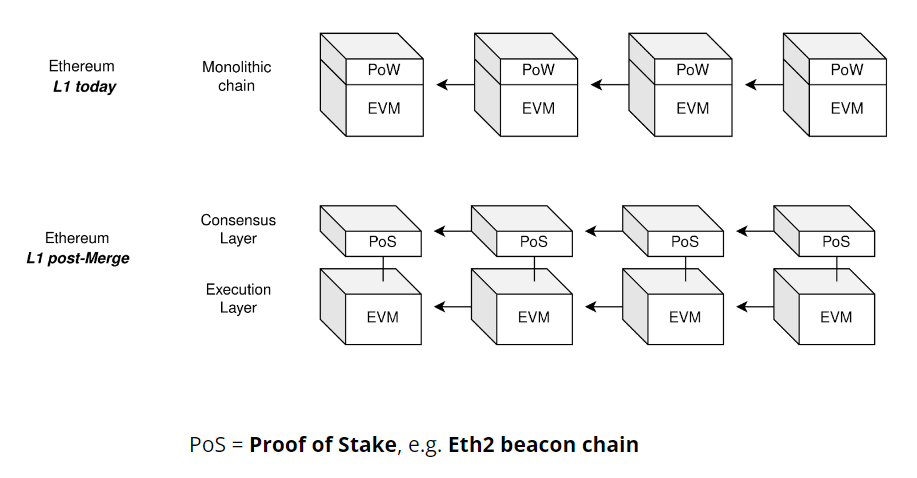 cr: Protolambda
cr: Protolambda
图中展示了合并前的单一型 PoW 链 vs. 合并后的 L1 共识层 (PoS) 和 L1 执行层 (EVM) 之间的模块化关系。而 PoS 和 EVM 之间的合并技术是通过一个叫做 ”Engine API“ 的东西实现的。下图是合并后完整客户端的样子,中间的 API 使得以太坊共识层 (PoS) 和执行层 (PoW) 之间可以实现通信。这是以太坊主网上的首个模块化设计。
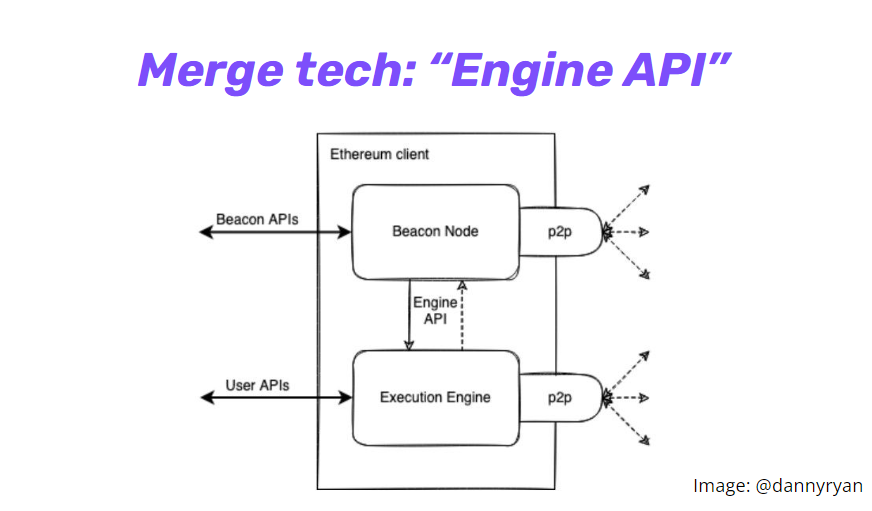 cr: Danny Ryan
cr: Danny Ryan
那么 L1 和 L2 之间是如何连接的呢?
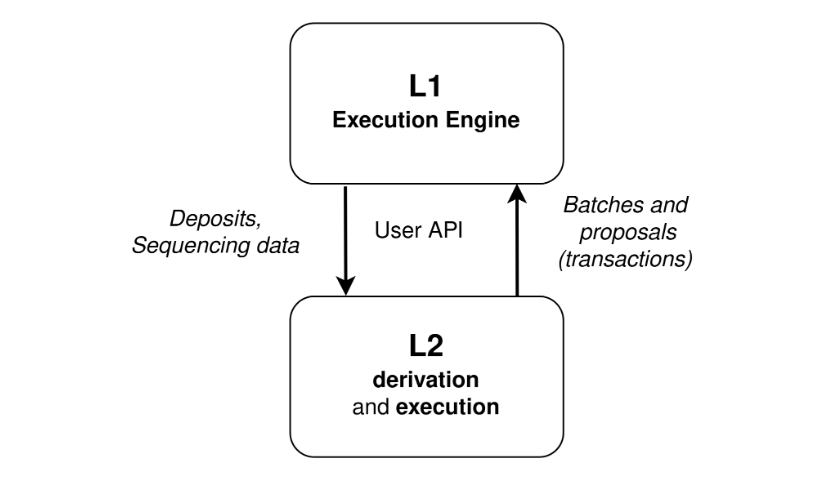 cr: Protolambda
cr: Protolambda
可以看到上图中,L1 和 L2 之间会有一个 API,它们分别是两套软件。
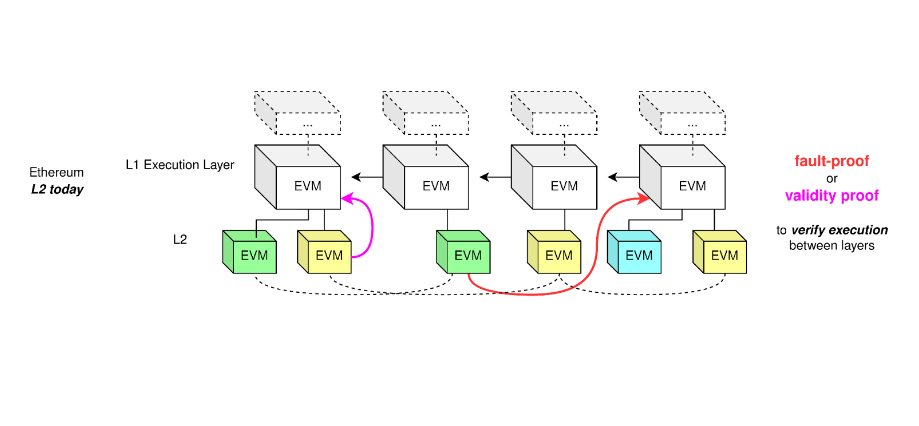 cr: Protolambda
cr: Protolambda
这是以太坊加上欺诈证明和有效性证明之后的示意图,相当于将 L2 作为一个执行层连接以太坊 EVM,然后你维持当前的 L2 执行层。但这也会有一个问题,因为就算可以堆叠执行层,但是这样效率不高,所以我们需要一个数据层。
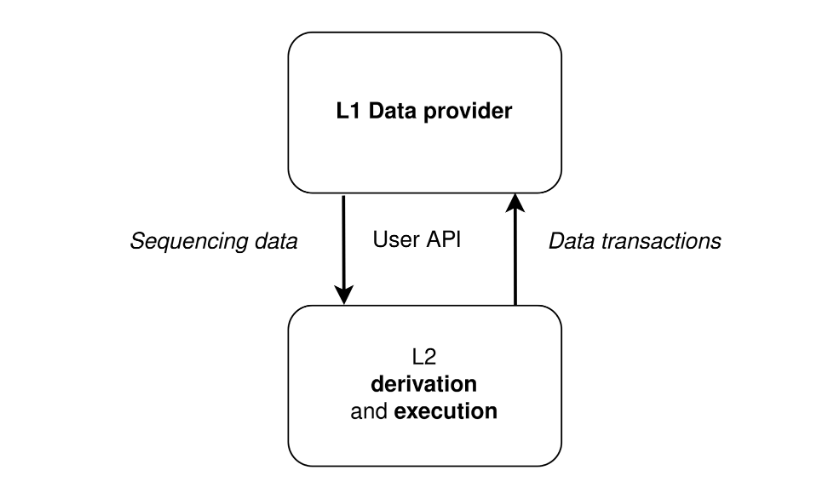 cr: Protolambda
cr: Protolambda
如上示意图,L1 作为数据层,L2 负责执行计算。
数据可用性是扩容的关键瓶颈
以太坊目前面临的一大瓶颈就是数据可用性,这是我们接下来一年里增加可扩展性所需要提高的范畴。
首先我们看一笔 rollup 交易包含哪些开销:
- 执行开销 (网络中所有节点执行交易并且验证其有效性的开销)
- 存储/状态开销 (使用新的值更新区块链 “数据库” 的开销)
- 数据可用性开销 (将数据发布至 L1 的开销)
其中,前两笔开销都是 Rollup 网络上的花费,占总开销的比例非常低。而数据可用性开销才是扩容的关键瓶颈。
我们为什么需要这种数据呢?
保证数据的可用性可以让任何人都可以无需许可地重构状态。
L2 提供的可扩展性是通过将执行检查和保证数据安全这两项工作分离而获得的。这让我们有机会同步以及获取验证状态的数据,而这个过程中定序器不会对其有直接影响。
目前,rollup 上传数据到 L1 都是以 calldata 的形式。这种方式非常贵,calldata 是一种没有修剪过的非常没有效率的数据形式,需要以一种迂回的方式将数据存放在以太坊,一个非 0 字节就需要花费 16 gas。所以出现了两种粗暴的降低这种开销的方法:
- calldata 压缩,不少 rollup 项目都已经开始研究压缩 calldata 的算法并集成到他们的系统中。
- EIP-4488,将每个非 0 字节的 calldata 开销从 16 gas 降低到 3 gas。
但是使用 calldata 的方式始终是不可持续的,因为这会带来 L2 不需要的遗留开销。那么有没有更优雅的方法呢?
数据可用性、数据可恢复性、长期数据可用性等等这些不同类型的名词,它们之间的差异就是可用性的时长各不同。譬如说,你希望这些数据的可用时间足够长来挑战定序者、重构状态。事实上,你不需要数据是永远可用的。在以太坊的假设中,存储超过一年的数据,用户可能在某个地方找到它,可能会将它同步到某个点,而不需要一直追溯到创世区块。
而 EIP-4844 这个提案则是让我们能够对数据做一些修剪,因为在这个提案下,数据只需要保留其可用性足够长的时间,让诚实的网络参与者重构完整状态并且挑战定序器。
EIP-4844 Proto-danksharding
EIP-4844 提议什么呢?
将数据可用性添加至以太坊且不会破坏可组合性,也就是说我们可以在 L1 有一个执行层,同时可以在上面添加数据可用性。
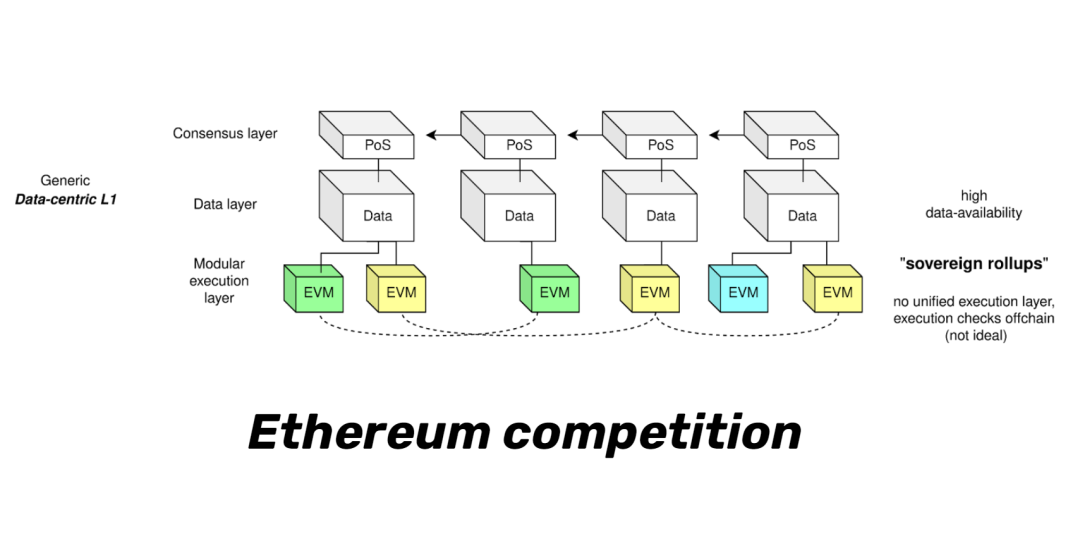 cr: Protolambda
cr: Protolambda
如图所示,我们现在有 L1 共识层、L1 执行层、L1 数据层、L2 执行层。在这样的分层架构下,我们获得了封装性,然后我们不同的团队可以针对不同的问题,并单独地提高某一层的可扩展性。
引入新的交易类型 Blob-carrying Transaction
EIP-4844 引入一种新的交易类型,这种交易类型与普通以太坊交易相比多了一个 blob 的位置用来存放 L2 的数据。比较独特的是,Blob 数据在一个月之后就会被节点删除,从而很大地节省了存储空间。
那么我们如何添加这种数据呢?
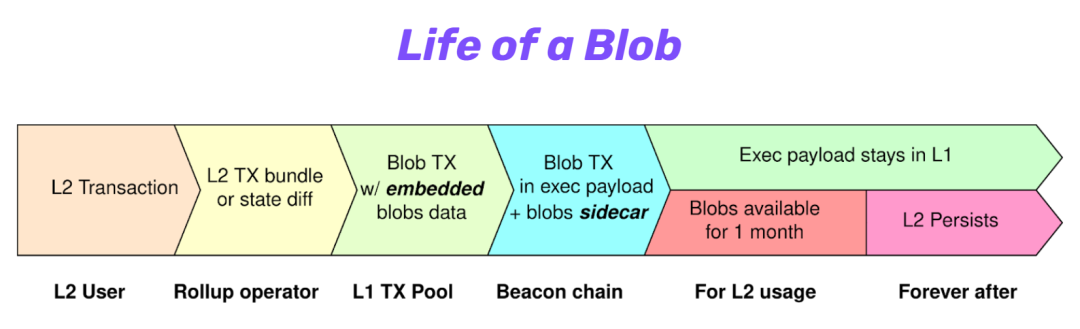 图:一个 “Blob” 的生命周期,cr: Protolambda
图:一个 “Blob” 的生命周期,cr: Protolambda
我们称这种数据为 “blob”,这是一种非常模糊的数据形式,类似于一种字符串。“Blob” 会被附加到一笔交易中,这笔交易就像其他交易一样在以太坊系统中运行。
但附加的内容具有自己的生命周期。请看上图图示:首先,rollup 运营者会纳入普通的交易,生成 L2 交易捆,目前是通过 calldata 的方式将交易 batch 直接发送至 L1。而有了 4844 之后,新增了一种携带 “blob” 数据的交易类型 “blob 交易”。这个 “blob 交易” 负责支付交易费,将承诺 (commitment) 包含进交易中以有效地证明该 blob 中存在的任意数据。但是附加的内容 (即 blob 数据) 本身是与 “blob 交易” 分离的,可以把这种数据看作是一个挎斗 (sidecar)。
(Sidecar 在不改变主应用的情况下,会起来一个辅助应用,来辅助主应用做一些基础性的甚至是额外的工作。这个 sidecar 通常是和主应用部署在一起,所以在同样环境下运行。这其中还有一些性能上的考虑,sidecar 如果和主程序网络通信上有延迟就会造成性能问题。这个辅助应用不一定属于应用程序的一部分,而只是与应用相连接。这就像是挎斗摩托车,每个摩托车都有自己独立的辅助部分,它随着主应用启动或停止。因为 sidecar 其实是一个独立的服务,我们可以在上面做很多东西,例如 sidecar 之间相互通信、或者通过统一的节点控制 sidecar ,形成网络服务 Service Mesh。来源:https://blog.csdn.net/lxlmycsdnfree/article/details/126286243)
blob data vs. calldata
要想知道两者的区别,我们首先要了解以太坊合并前以及合并后的区块组成。
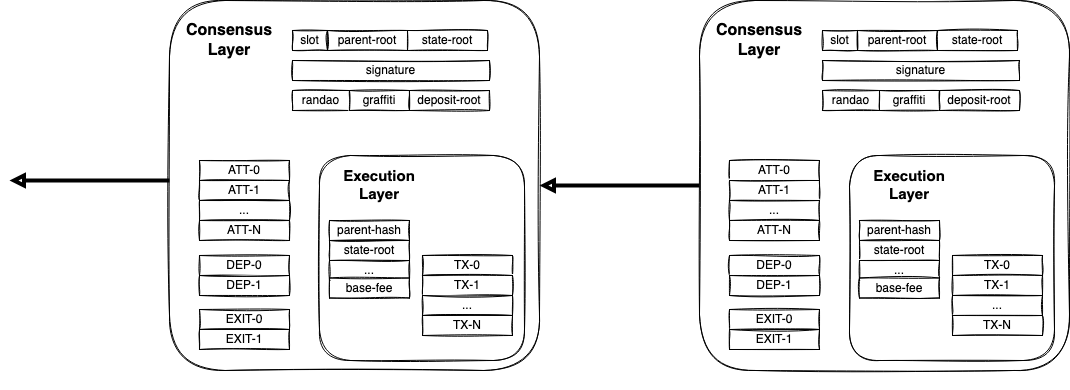 cr: Danny Ryan
cr: Danny Ryan
上图为合并后的信标区块,执行层被包裹在共识层里,而 EL 最核心的部分就是 ExecutionPayload (执行负载)。
EL 和 CL 分别负责两个主要功能,前者执行 EVM,后者负责 PoS 共识。信标区块中包含 EL 的ExecutionPayload,外层的状态根为信标链状态的更新,EL 内的状态根则是 EVM 账户状态更新。
现在我们重新来看 Calldata 和 blob data 之间的区别。
首先,这两种数据类型有不同的生命周期。Calldata 存在于 “execution payload” 中 (普通的 L1 交易),而 blob 数据存储于共识层中。也就是说 “blob” 存储在一个 Prysm 节点或者 Lighthouse 节点中,而不是在 Geth 中。然后这些共识层节点会在特定一段时间之后对 blob 数据进行修剪。
“Blob” 在网络的运作流程如下图所示:
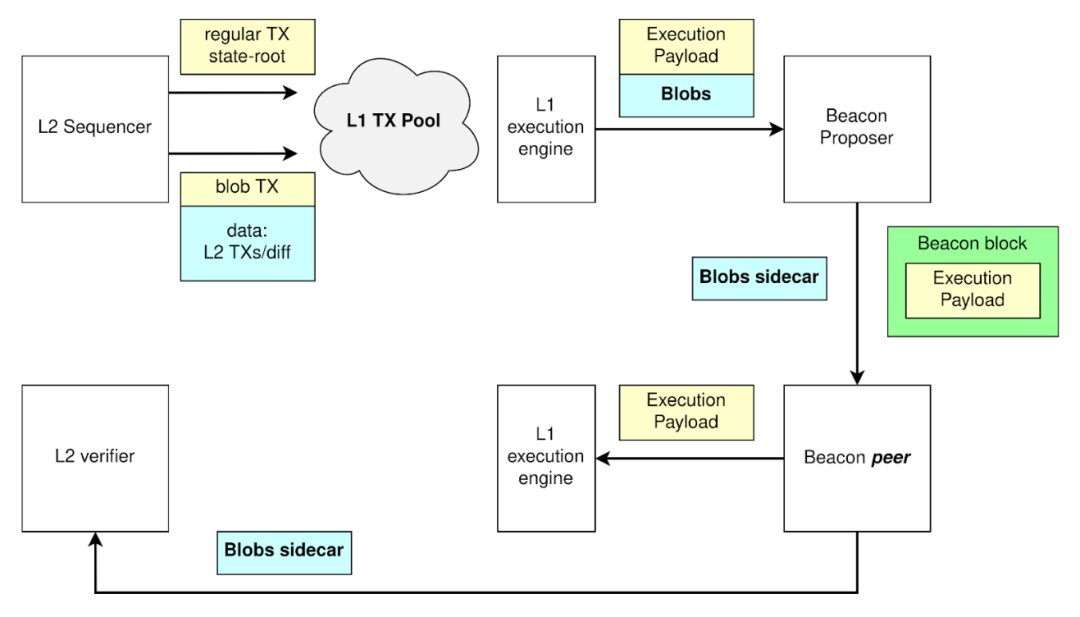 cr: Protolambda
cr: Protolambda
- 定序器提供数据 ->
- L1 敲定数据 ->
- 将 Blob sidecar 从 Blob 交易中分离出来 ->
- Blob 交易中的执行发生在 Execution Payload 中 ->
- rollup 验证状态所需要的数据则去到另一侧的数据库中,L2 验证者可以下载这些 sidecar 并同步 L2。
Blob 有两个显著的特点:
第一就是不被合约读取,下图是一笔 blob 交易的样子,可以看到 EVM 不会读取 blob。
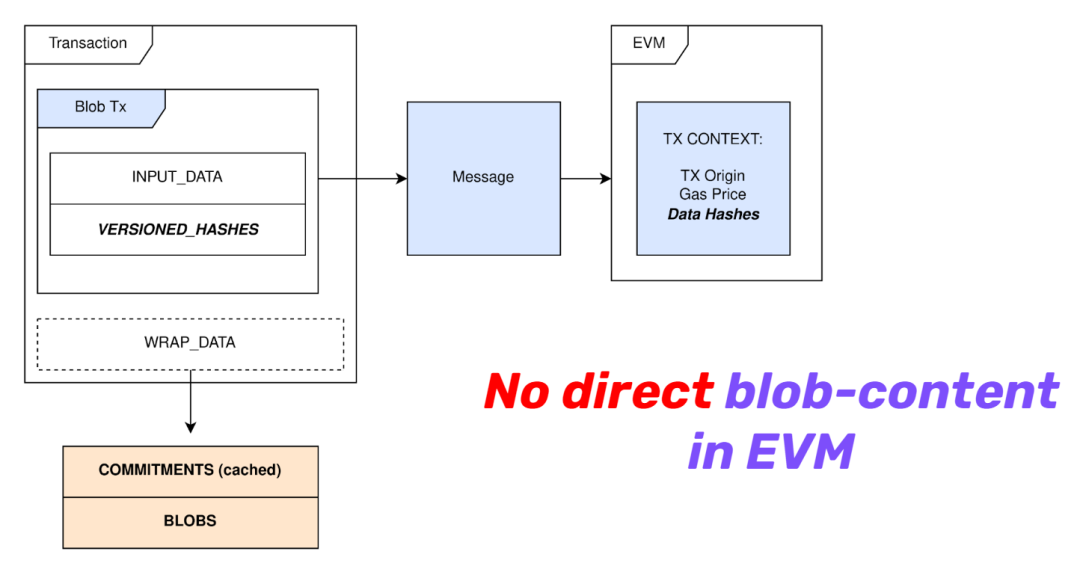
cr: Protolambda
就像前面所介绍那样,blob data 存储在共识层节点中,和 calldata 需要被合约读取所消耗的资源相比要便宜得多。
第二就是,一个月后,共识层节点会对 blob 内的值进行删除。区块空间一直以来主要都由交易占用着,而随着 L2 的发展,L1 基础层转而成为 L2 的数据层,calldat 就会占用更多的区块空间。能够定期删除 blob 数据的话,可以很好地解决 L1 状态膨胀的问题。
总结
随着 Rollup 技术的逐渐完善,数据可用性成为各个解决方案更进一步扩容的瓶颈。而 L1 作为一个为 Rollup 保驾护航的基础层,它不仅可以为 rollup 提供安全保障,还可以充当 rollup 的数据层,让可扩展性实现指数级的提升。Proto-danksharding 作为完整版 Danksharding 的前提条件,通过引入 携带 “blob data” 的交易类型这样的一个新设计,让基础层更无压力地存放 L2 数据,同时不影响数据可用性的安全性。
OP in Paris: Protolambda 介绍 EIP-4844
https://www.youtube.com/watch?v=KQ_kIlxg3QA
《以太坊分片设计的历史回顾和未来路线图》
https://www.ethereum.cn/Eth2/sharding-design-history
《Rollup 的大補帖:Proto-Danksharding(一)》
https://medium.com/taipei-ethereum-meetup/rollup-and-the-boost-from-proto-danksharding-85d2fe0566b6
EIP-4844 提案规范
https://eips.ethereum.org/EIPS/eip-4844
以 Rollup 为中心的以太坊路线图
https://www.ethereum.cn/a-rollup-centric-ethereum-roadmap
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。


