



Sismo解读系列:Sismo Badge
Exermon热度: 16025
本篇为Sismo源码解读的第一篇,我们来解读一下Sismo Badge,这也是我认为Sismo最基础的部分。
原文作者:Exermon
原文来源:a16zcrypto
0x00 前言
本篇为Sismo源码解读的第一篇,我们来解读一下Sismo Badge,这也是我认为Sismo最基础的部分。
0x01 Sismo介绍
什么是Sismo
Sismo 是一个去中心化身份和信任协议,旨在构建可验证的身份和可信任的数据生态系统。它基于以太坊区块链技术,并使用零知识证明(Zero-Knowledge Proofs)来实现个人数据的隐私保护和认证。
Sismo 的目标是使个人能够拥有和控制自己的数字身份,并能够选择与其他应用和服务共享特定的身份信息,而无需泄露其他敏感数据。通过使用零知识证明,Sismo 可以提供可验证性,从而允许用户证明自己的身份、属性或行为,而无需直接披露与之相关的详细信息。
Sismo 的主要组件包括:
- Sismo Vault:一个加密存储空间,用于安全地存储用户的个人数据和身份凭证。
- Sismo Connect:一个身份验证和数据共享协议,允许用户与应用程序进行身份验证和数据交换,同时保护隐私。
- ZK Badges:通过零知识证明生成的可验证凭证,用于证明用户的身份、属性或资格。
- Sismo Hub:一个集成存储库,用于创建和管理 Sismo 的群组、数据提供者和其他集成组件。
Sismo 的目标是为用户提供更大的数字权力和控制,同时保护其个人隐私。它可以应用于各种场景,包括去中心化身份认证、数字资产管理、数据共享和社交网络等。
(以上来自ChatGPT)
上面的介绍我觉得不太直观,其实一句话概括,我们可以简单粗暴地理解为Sismo就是一个ZK勋章的协议。
举一个具体例子,假设一个勋章的条件是持有某个NFT,我有A, B两个钱包,其中A钱包持有该NFT,B钱包是我临时生成的新钱包。我登陆Sismo平台,连接我的A钱包,我就可以领取这个勋章。这个勋章领取到哪里呢?我可以新建一个钱包(比如B钱包),把这个勋章Mint到B钱包,那么这个勋章就和A完全没有关系,对外展示勋章时候就不会暴露A地址,而由于他是通过ZK(零知识证明)生成的,我们又能验证勋章的真实性。
为什么我们不想暴露这里的A地址呢?因为一旦A地址被暴露,任何人都可以知道我(A地址)在链上做过的和未来要做的所有事情,便没有隐私可言。所以才会需要通过这种方式隐藏自己地址,但同时又能证明我真的做过某事。
另外,这里的勋章是一个不可转移的ERC1155,可以理解为是一个SBT。
这里涉及到一些概念,比如ZK、ERC1155等,如有不了解的请自行搜索学习。
ZK Badge Protocol
零知识勋章协议是Sismo的重要组成部分,其包含了四个部分:Group、Attester、Attestation Registry、Badge,他们的关系如下图(该图出自Sismo官方文档):
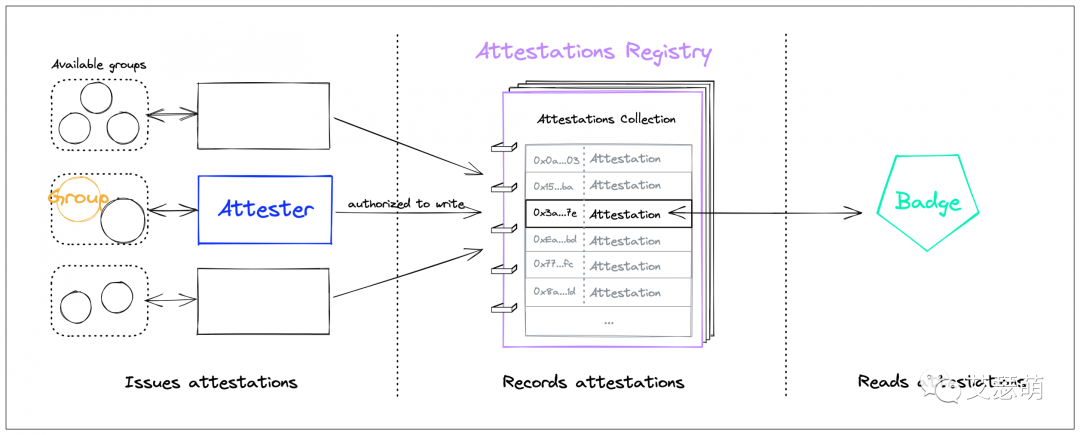 Group
Group
太长不看版:Group就是满足特定条件的用户标识符(比如地址、推特ID等)和值的集合,该集合可以被任何人构建和使用。目前,Group的创建需要Sismo团队的审核。
Sismo Group(Sismo 群组)是 Sismo 协议中的一个重要概念,用于将具有共享特征的数据源进行打包和分类。它是 Sismo 构建的基本数据单元,用于实现身份验证、数据共享和信任建立。
在 Sismo 中,数据源(Data Sources)是用户个人数据的集合,包括来自不同的 Web2 和 Web3 账户、凭证和证明。这些数据源中的数据被视为有价值的数字身份元素,可以用于验证用户的特定属性或身份。
Sismo Group 将数据源进行分类和打包,形成一个特定的群组。群组使用 Merkle Tree进行存储,其根节点将发送到区块链上,以供验证者进行验证。通过证明自己是群组的成员,用户可以获得 ZK Badge 或使用 Sismo Connect 应用程序等功能。
Sismo Group 的创建和管理可以通过 Sismo Hub 进行。Sismo Hub 提供了群组生成器(Group Generator)工具,允许开发者创建不同类型的群组。群组生成器可以根据特定的规则和条件将数据源进行组合,形成符合特定要求的群组。群组生成器使用数据提供者(Data Provider)来获取特定数据,以满足群组的需求。
通过 Sismo Group,用户可以根据其拥有的数据源证明自己的成员资格,并将其身份元素安全地共享给应用程序。Sismo Group 的使用有助于建立可信的数字身份和信任生态系统,保护个人隐私,并提供更加灵活和安全的数据共享机制。
关于Merkle Tree,如果有不了解的同学,可以看这篇:Merkle Tree - 通过hash来确保系统完整性的解决方案 - 掘金 (juejin.cn)
Attester
太长不看版:Attester是一个(一组)智能合约,该合约用于验证用户的Request和ZKP,生成Attestation,Attester有多种用途和多种算法实现。
Sismo Attester(Sismo 验证者)是 Sismo 协议中的一个重要角色,负责验证用户的身份和数据,并为其生成证明(Proof)。Sismo Attester 是一个可信的实体,通常是一个智能合约或外部服务,用于验证用户提供的数据和声明的真实性。
Sismo Attester 的主要功能是对用户提供的数据进行验证,并生成具有可验证性的证明。这些证明可以用于不同的场景,例如身份验证、访问控制和数据共享。通过验证用户的数据并生成证明,Sismo Attester 帮助确保数据的可信性和完整性。
Sismo Attester 使用的验证方法可以是各种不同的技术,例如零知识证明(Zero-Knowledge Proof)、数字签名、哈希函数等。具体使用哪种验证方法取决于应用程序的需求和安全性要求。
用户在与 Sismo Attester 进行交互时,通常需要提供相关的数据和声明,并请求 Attester 对其进行验证。Attester 接收到用户的请求后,会对数据进行验证,并生成相应的证明。验证的结果和证明通常会返回给用户,以便用户在需要时进行使用和验证。
Sismo Attester 的存在可以提供数据和身份验证的可信机制,帮助构建安全、隐私保护的数字生态系统。它确保用户的数据得到合法验证,并能够证明其真实性,从而增强了数据的可信度和应用程序的安全性。
Attestations Registry
太长不看版:Attestations Registry是一个智能合约,用于储存和管理所有的Attestation。
Attestations Registry(认证注册表)是 Sismo 协议中的一个组成部分,用于存储和管理认证数据和证明。它充当了一个集中化的存储和索引系统,用于记录和跟踪认证数据的状态和可用性。
在 Sismo 中,认证是指对用户的身份、属性或其他数据进行验证和确认的过程。认证数据通常由第三方机构或验证者生成,并被存储在认证注册表中。认证数据可以包括数字身份证明、证书、许可证等。
认证注册表的主要功能包括:
- 存储认证数据:认证注册表作为一个数据存储系统,可以持久化地保存认证数据和相应的证明。这些数据可以根据不同的标识符或密钥进行索引和访问。
- 管理认证状态:认证注册表可以跟踪和管理认证数据的状态,例如认证的有效期、吊销状态等。这有助于保持认证数据的及时性和准确性。
- 提供认证查询接口:认证注册表提供了查询接口,使其他应用程序或验证者可以查询和验证认证数据的有效性和真实性。这有助于构建可信的数据生态系统和信任框架。
通过使用认证注册表,Sismo 协议能够实现可信的认证和验证机制。用户可以通过认证注册表查找和验证他们的认证数据,并向第三方应用程序提供具有可信度和完整性的认证证明。认证注册表提供了一种标准化和可扩展的方法,帮助构建具备信任和安全性的数字身份和数据生态系统。
Badge
太长不看版:Badge即上文提到的ZK勋章,任何人都可以创建Badge,一个Badge可以通过关联多个Group,或者自定义规则来定义能领取的用户标识符集合。目前,Badge的创建也需要Sismo团队的审核。
Sismo Badge(Sismo 徽章)是 Sismo 协议中的一个概念,它代表着用户在特定的数据群组中具有特定属性或身份的认证证明。徽章是通过在 Sismo Hub 上创建和管理数据群组,并将其注册到区块链上来实现的。
Sismo Badge 与数据群组相关联,数据群组是一组具有相似属性或身份的用户数据的集合。例如,一个数据群组可以是所有在某个特定时间段内注册的法国公民,或者是所有在 Proof of Humanity 注册表中的参与者。徽章充当了对数据群组成员身份的确认和证明。
生成 Sismo Badge 的过程如下:
- 创建数据群组:使用 Sismo Hub 的 Group Generator 工具创建一个数据群组,并指定相应的条件和属性。
- 注册数据群组:将创建的数据群组注册到区块链上,以便其他用户和验证者可以访问和验证数据群组的存在和内容。
- 构建徽章:将数据群组与相应的徽章关联起来,形成 Sismo Badge。徽章可以包含与数据群组相关的元数据和属性,以及用于验证和检索徽章的证明数据。
- 使用徽章:具有特定徽章的用户可以将其用于不同的应用程序和场景中,以证明他们属于特定的数据群组并具备相应的属性或身份。
Sismo Badge 的目的是提供一个可信、可验证和可复用的方式,使用户能够在不同的环境中证明自己的身份和属性。通过使用 Sismo Hub 和区块链技术,徽章的生成和验证过程变得透明、安全和不可篡改,为用户提供了更可靠和可信的身份认证机制。
Data Gem
官方的定义是:存储在用户Data Vault中的数据源中的原子数据被称为Data Gem(The atomic pieces of data stored in a user’s Data Vault, housed within Data Sources, are characterized as Data Gems)
但我觉得Sismo官方对这些概念的定义都挺难理解的,我们可以简单粗暴理解为Data Gem就是Data Group中的一项。
技术上,Data Gem包含了三个要素:
- Owner——数据的所有者,即用户标识符(可以理解为键)
- Value——价值,即对应于特定声誉级别的数字(可以理解为键对应的值)
- Type——类型,即组合了唯一的groupId和时间戳(默认为最新),将用户分类到特定的数据组中
所以,一堆相同类型的Data Gem组成了一个Group,我们就可以理解为他就是Group中的一项。
0x02 Sismo产品体验
创建Group(可选)
我们可以先创建一个自己的Group,首先,进入Sismo官网:Sismo - Own your identities,点击右上角的Factory,进入Factory页面:
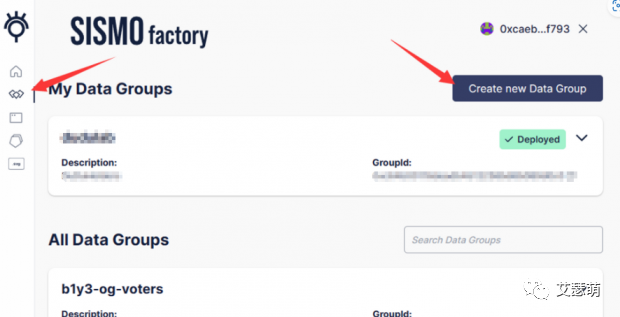 按照上图指引,点击Create new Data Group,在新页面创建自定义的Group。
按照上图指引,点击Create new Data Group,在新页面创建自定义的Group。
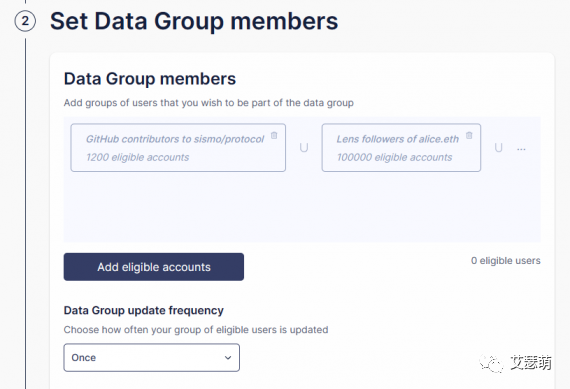 这里最主要的就是Set Data Group members这部分,点击Add eligible accounts,我们可以通过多种方式构建这个Group,比如获取一个ERC721的 Holder列表:
这里最主要的就是Set Data Group members这部分,点击Add eligible accounts,我们可以通过多种方式构建这个Group,比如获取一个ERC721的 Holder列表:
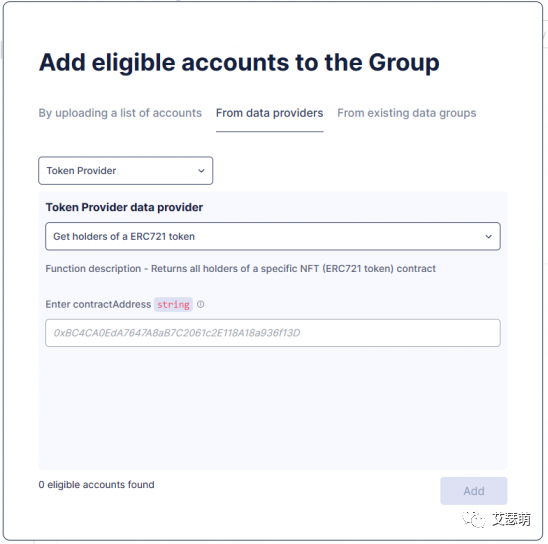 我们可以创建多个条件,最终生成的Group是所有条件的地址的并集。接着,补全一下基本信息,就可以给Sismo提出创建Group请求了(需要一定时间给Sismo团队审核,一般都很快)
我们可以创建多个条件,最终生成的Group是所有条件的地址的并集。接着,补全一下基本信息,就可以给Sismo提出创建Group请求了(需要一定时间给Sismo团队审核,一般都很快)
创建Badge
有了Group之后(当然,也可以没有),我们就可以创建自定义的Badge了。
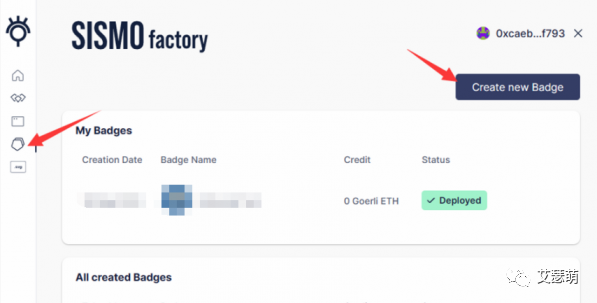 按照上图指引,点击Create new Badge,在新页面创建自定义的Badge。
按照上图指引,点击Create new Badge,在新页面创建自定义的Badge。
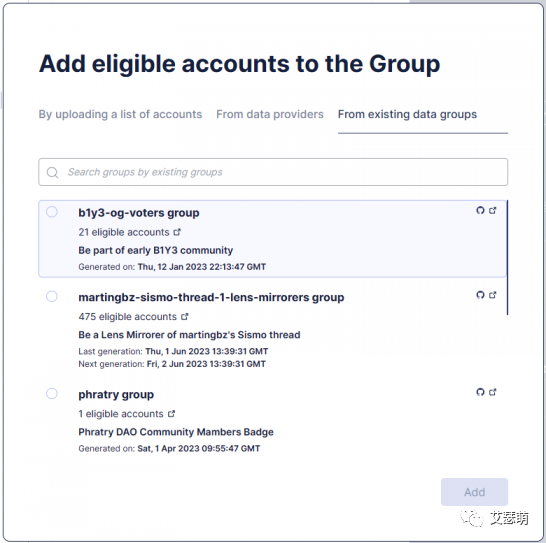
创建Badge和创建Group是很像的,也需要设置一个Eligible Accounts,表示能领取的用户列表(地址列表),当然,我们可以直接使用上面创建好的那个Group:
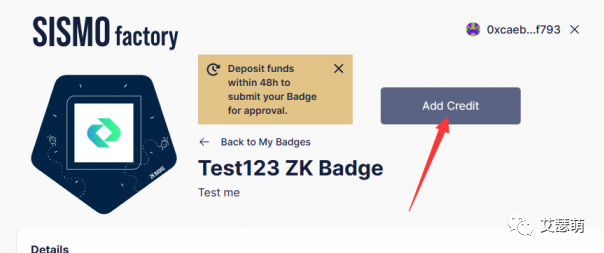
 只要补全勋章图片等信息,即可成功创建Badge。创建Badge之后,我们还需要给Badge进行一个Add Credit操作,选择要部署的链,并且支付一定的代币用于部署和发行一定数量的Badge:
只要补全勋章图片等信息,即可成功创建Badge。创建Badge之后,我们还需要给Badge进行一个Add Credit操作,选择要部署的链,并且支付一定的代币用于部署和发行一定数量的Badge:
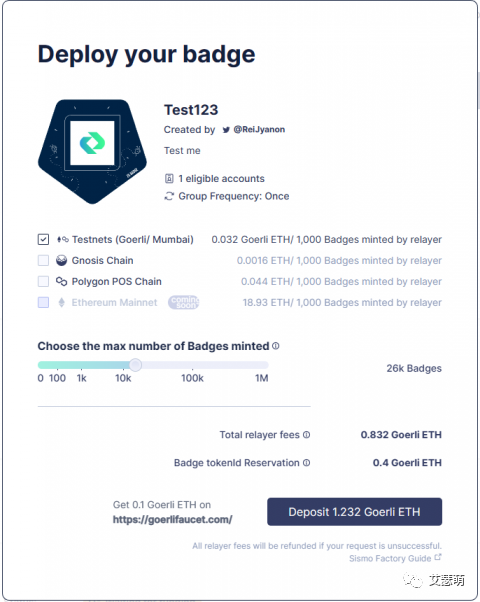 在上图的例子里,我们选择Goerli测试网部署,总共需支付1.232 GoerliETH,用于部署(0.4 GoerliETH)和发行26k个Badge(0.032GoerliETH / 1000 Badges)
在上图的例子里,我们选择Goerli测试网部署,总共需支付1.232 GoerliETH,用于部署(0.4 GoerliETH)和发行26k个Badge(0.032GoerliETH / 1000 Badges)
我们完成Deposit操作之后,系统就会自动提交创建Badge申请,只需等待Sismo团队审核通过,即可公开展示并允许所有符合条件的用户Mint!
Mint Badge
我们要如何领取Badge呢?等我们的Badge部署好后(或者找其他已经部署了的Badge),点开详情,在Overview里能看到“Minting link”,点开该链接:
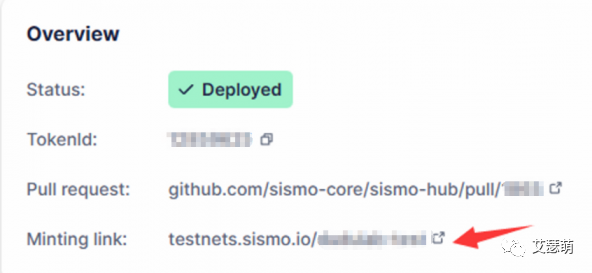 进入Sismo平台,我们连接好钱包,通过搜索很快就能发现我们刚才创建的Badge,并且当前连接的钱包是满足该勋章的mint条件的:
进入Sismo平台,我们连接好钱包,通过搜索很快就能发现我们刚才创建的Badge,并且当前连接的钱包是满足该勋章的mint条件的:
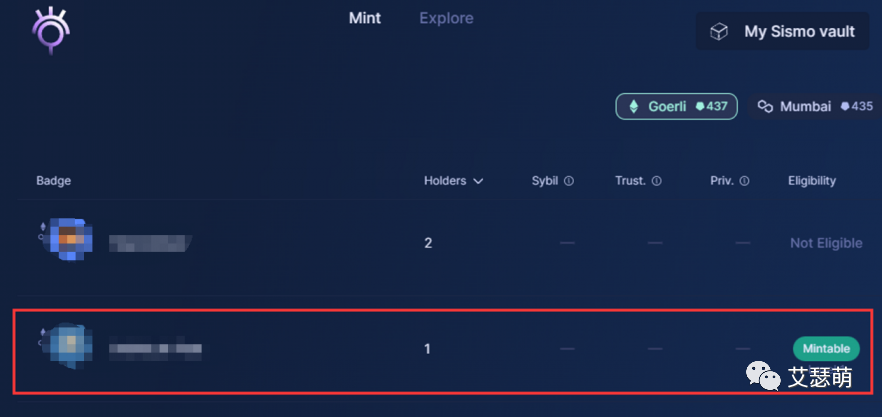 点开Badge详情,我们Import一个新钱包,将这个Badge mint到新钱包上,实现Badge与原地址关系分离:
点开Badge详情,我们Import一个新钱包,将这个Badge mint到新钱包上,实现Badge与原地址关系分离:
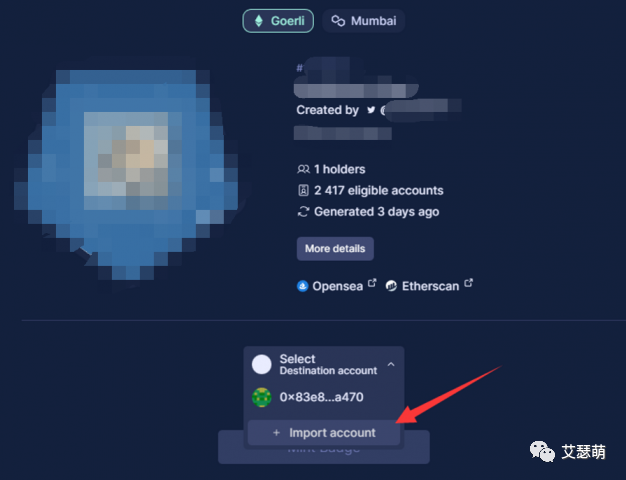 最终,我们成功将Badge mint到新钱包上:
最终,我们成功将Badge mint到新钱包上:
 0x03 链上交互和源码分析
0x03 链上交互和源码分析
我们刚刚在Sismo上mint了一个Badge,我们现在从这个交易出发,解读一下Sismo Badge相关合约的整个逻辑。
交易信息:Goerli Transaction Hash (Txhash) Details | Etherscan
batchGenerateAttestations
我们通过Detail里解码之后的Input Data(因为Sismo是高度开源的项目,我们可以很方便对其合约操作进行解码),可以发现他是调用了0x40713429614c47e94bC078069Df9C084fb44edfC(他是一个Proxy,实际是调用0xbd72cfd7C0874B0E46C47EE05a218093D21C248f,即Front合约。关于Proxy:ERC1967 代理合约标准详解 - 简书 (jianshu.com))的batchGenerateAttestations函数:
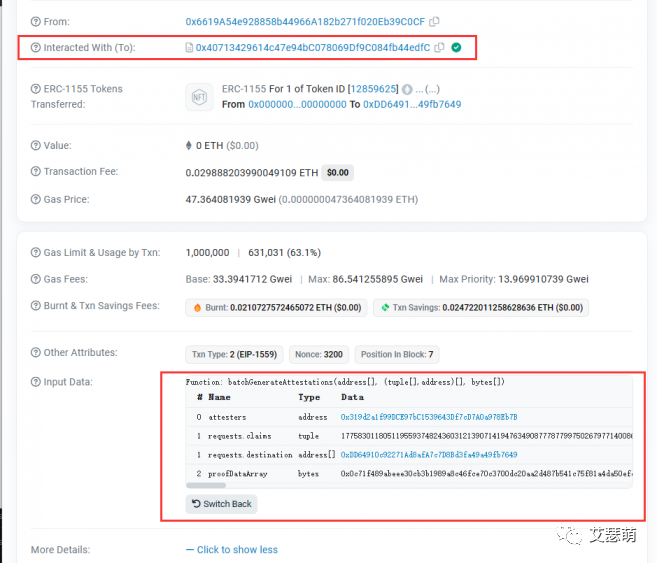
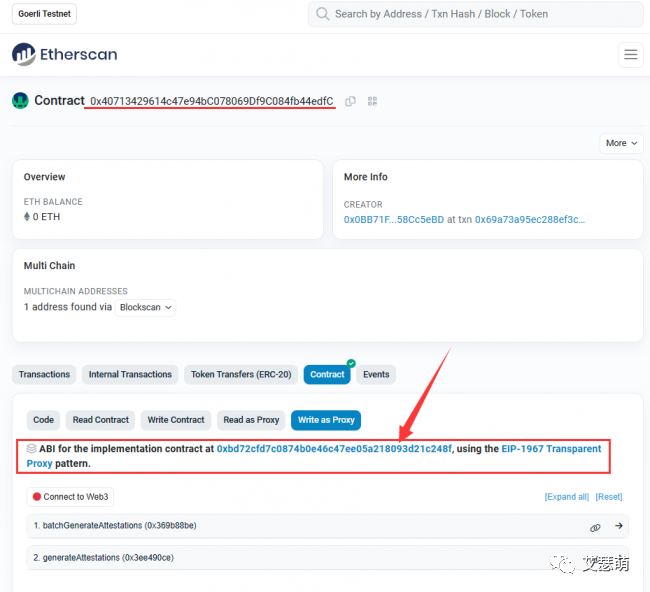 有了函数名,我们很容易就能找到该函数的定义:
有了函数名,我们很容易就能找到该函数的定义:
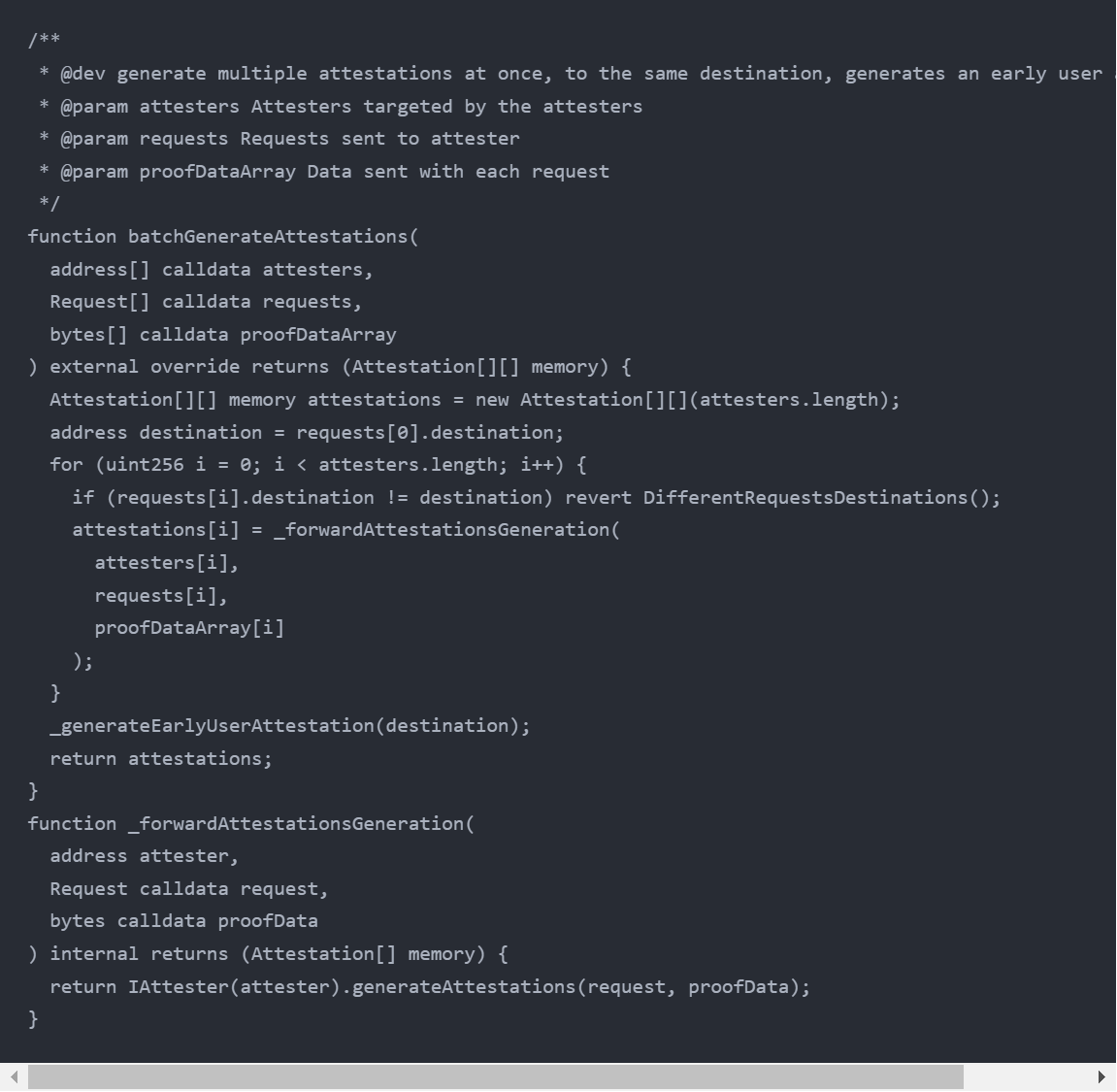
这个函数的逻辑很简单,其实就是遍历每一个传入的attesters、requests和proofDataArray(在本例中所有参数都只有一项),对每一项都进行generateAttestations操作(定义在IAttester)。
我们传入的attesters,实际上就是每项的Attester合约的地址。前面说过,Attester是一组合约,目前Sismo Attester有三种实现:
- Hydra-S1 —— 用于ZK Badge
- Hydra-S2 —— 用于Sismo Connect
- Pythia ZK Proving Scheme —— 仍未正式发布
上述每一个实现都是一个独立的合约,供特定用途时调用。
在Badge的场景中,使用Hydra-S1方案做验证,所以传入的attester地址也应该是该方案所对应的合约的地址,我们点开上面交易里传入的地址:0x319d2a1f99DCE97bC1539643Df7cD7A0a978Eb7B,发现他也是一个Proxy,实际调用的地址是:0xAB8F48001f70BD45225C3f334E70a3E27B6D1c4e,果不其然,他是一个HydraS1AccountboundAttester,是Hydra-S1方案的Attester的实现。
generateAttestations
在上面的代码中,合约调用了attester的generateAttestations函数,但是我们在HydraS1AccountboundAttester合约内,并没有发现这个函数。但我们顺着该合约的继承关系(HydraS1AccountboundAttester < HydraS1SimpleAttester < HydraS1Base < Attester),就能发现其基类Attester中实现了该函数:
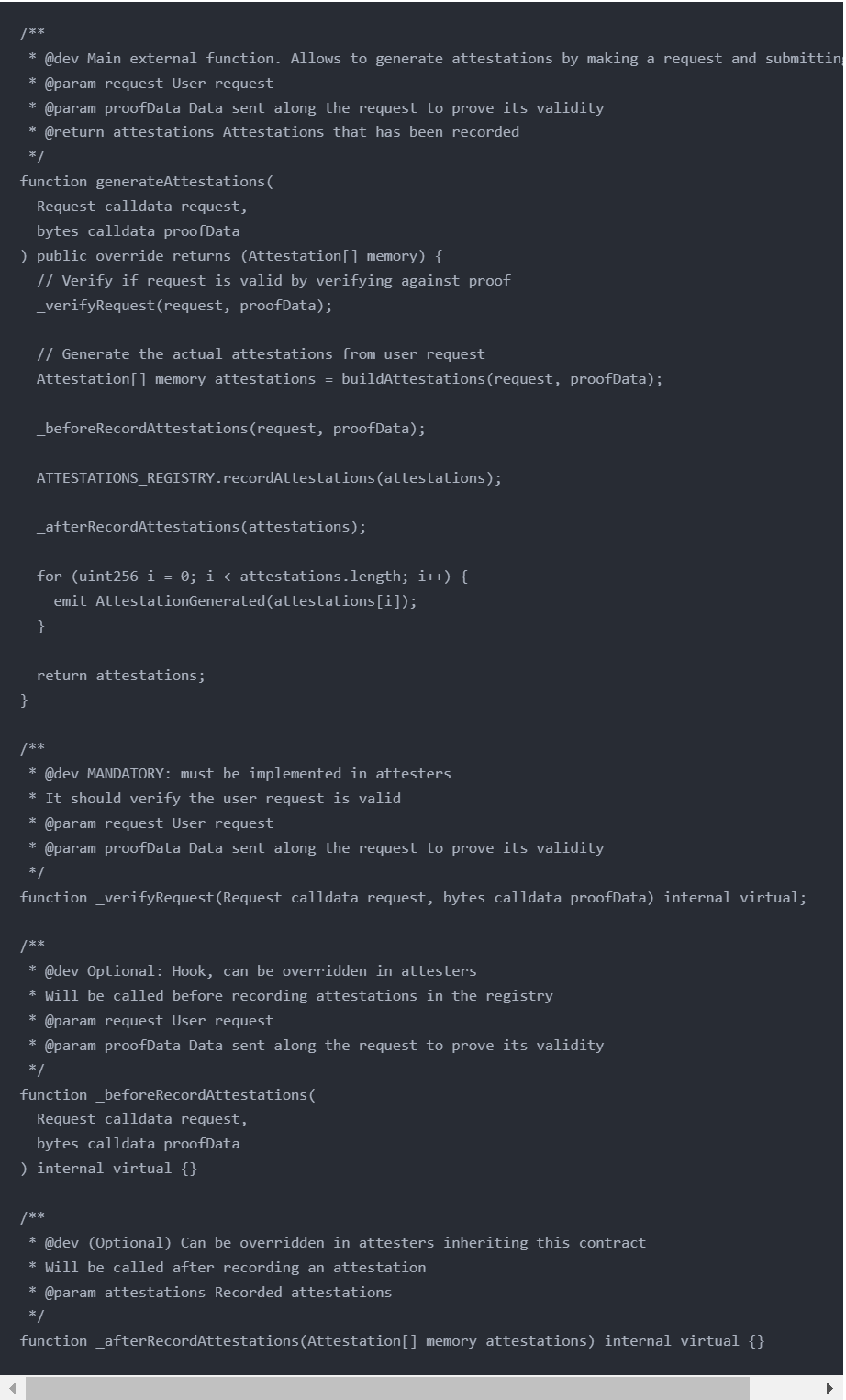
该函数用于生成attestations,它接收一个request和proofData作为参数,并返回一个包含已记录attestations的数组。函数的主要逻辑如下:
- 调用_verifyRequest函数用于验证请求的有效性,通过对request和proofData进行验证。
- buildAttestations函数根据用户请求和proofData生成attestations
- _beforeRecordAttestations函数是一个可选的Hook,可以在attesters中重写。它将在记录attestations之前被调用,用于执行一些预处理操作。
- ATTESTATIONS_REGISTRY.recordAttestations函数将attestations记录到attestations注册表中。
- _afterRecordAttestations函数是一个可选的Hook,可以在attesters中重写。它将在记录attestations之后被调用,用于执行一些后处理操作。
- 最后,通过循环遍历attestations数组,触发AttestationGenerated事件,并将attestations数组返回。
该函数会调用到三个虚函数:
- _verifyRequest函数是一个内部虚函数,需要在attesters中实现。它用于验证用户请求的有效性,接收一个request和proofData作为参数。
- _beforeRecordAttestations函数是一个内部虚函数,可以在attesters中重写。它将在记录attestations之前被调用,接收一个request和proofData作为参数。
- _afterRecordAttestations函数是一个内部虚函数,可以在attesters中重写。它将在记录attestations之后被调用,接收一个包含记录的attestations的数组作为参数。
_verifyRequest
对于HydraS1AccountboundAttester而言,其_verifyRequest定义在HydraS1SimpleAttester,具体定义如下:
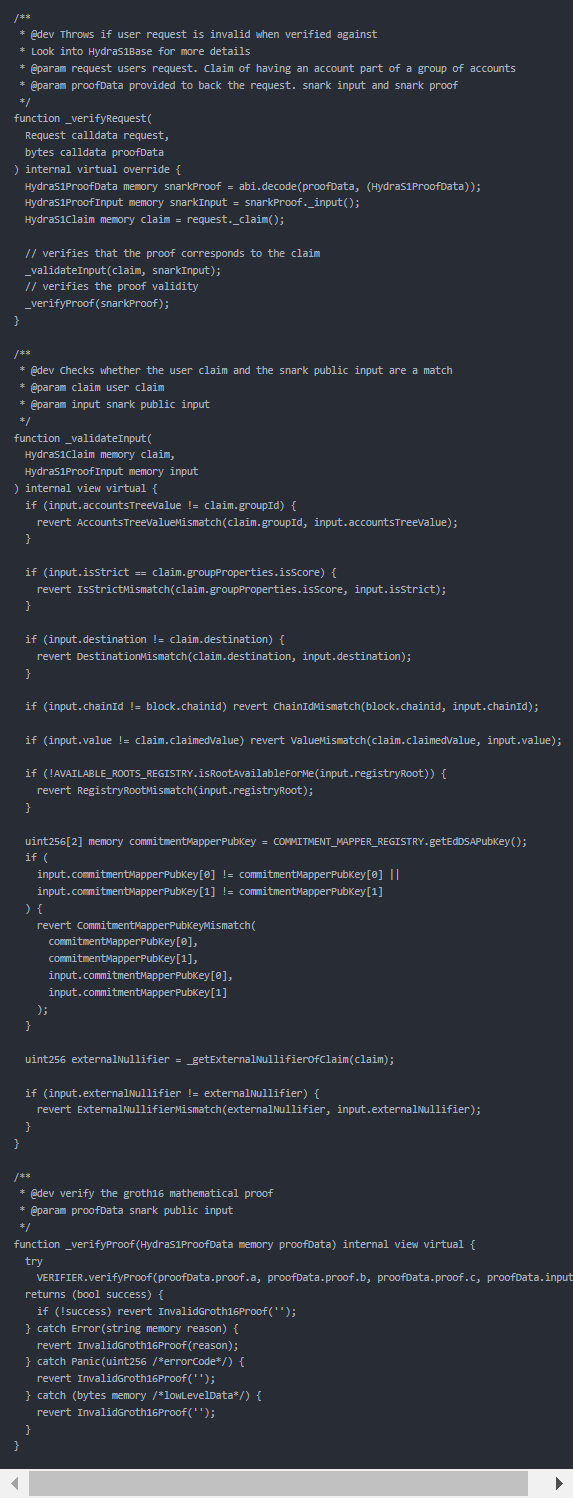
该函数用于验证用户请求的有效性,并与用户提供的proofData进行验证:
- abi.decode函数将proofData解码为HydraS1ProofData结构体。
- _validateInput函数用于检查用户声明和snark公共输入是否匹配。
- 它接收一个HydraS1Claim和HydraS1ProofInput作为参数,并进行以下验证:
- 验证input.accountsTreeValue是否与claim.groupId匹配。
- 验证input.isStrict是否与claim.groupProperties.isScore匹配。
- 验证input.destination是否与claim.destination匹配。
- 验证input.chainId是否与当前区块的chainid匹配。
- 验证input.value是否与claim.claimedValue匹配。
- 验证input.registryRoot是否在AVAILABLE_ROOTS_REGISTRY中可用。
- 验证input.commitmentMapperPubKey是否与COMMITMENT_MAPPER_REGISTRY中的公钥匹配。
- 验证input.externalNullifier是否与通过_getExternalNullifierOfClaim函数计算的claim的外部空化器匹配。
- _verifyProof函数用于验证Groth16数学证明的有效性。
- 它接收一个HydraS1ProofData作为参数,并使用VERIFIER.verifyProof函数进行验证。如果验证失败,将抛出相应的异常。其中,VERIFIER是HydraS1Verifier合约,用于验证Hydra-S1方案,将在下文进行解读。
_beforeRecordAttestations
对于HydraS1AccountboundAttester而言,其_beforeRecordAttestations在HydraS1AccountboundAttester有最终定义,具体定义如下:
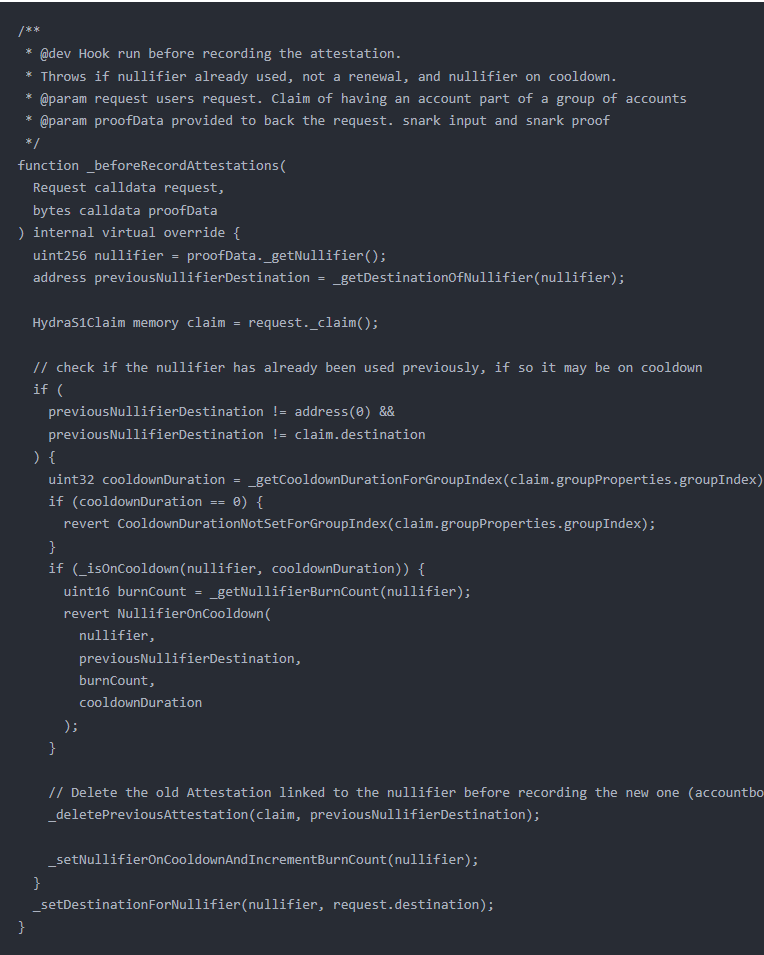
该函数是在记录attestation之前执行的钩子函数,用于进行一些前置检查。具体如下:
- 获取nullifier并检查是否已使用:
- uint256 nullifier = proofData._getNullifier();
- address previousNullifierDestination = _getDestinationOfNullifier(nullifier);
- 从proofData中获取nullifier,并根据nullifier获取之前使用过的nullifier的目标地址previousNullifierDestination。
- 获取声明信息:
- HydraS1Claim memory claim = request._claim();
- 从request中获取声明信息,并存储在claim变量中。注意,这里的_claim并非定义在Request中,而是在HydraS1Lib中(library)实现的:

3.检查nullifier是否已使用并在冷却中:

- 首先,检查之前是否已使用过该nullifier,并且之前使用过的nullifier的目标地址与当前声明的目标地址不一致。如果是这种情况,则进一步检查nullifier是否在冷却中。
- 首先,通过_getCooldownDurationForGroupIndex函数获取与声明的groupIndex关联的冷却期限cooldownDuration。如果返回值为0,表示未设置该groupIndex的冷却期限,将抛出异常CooldownDurationNotSetForGroupIndex。
- 然后,通过_isOnCooldown函数检查nullifier是否在冷却中,如果是,则获取nullifier的burn计数burnCount,并抛出异常NullifierOnCooldown。
- 删除之前的attestation:
- _deletePreviousAttestation(claim, previousNullifierDestination);
- 在记录新的attestation之前,删除之前与该nullifier关联的attestation。这是一个accountbound特性的操作。
- 设置nullifier的冷却状态和burn计数:
- _setNullifierOnCooldownAndIncrementBurnCount(nullifier);
- 将nullifier设置为冷却状态并递增其burn计数。
- 为nullifier设置新的目标地址:
- _setDestinationForNullifier(nullifier, request.destination);
- 为nullifier设置新的目标地址,即将其与当前请求的目标地址进行关联。
recordAttestations
为了确保你的大脑还清醒,我们先停下来想想,是不是似乎漏了点什么没有讲?
对,我们漏了很关键的一步——mint Badge!
上面讲到的都是如何验证用户请求和ZKP,生成Attestation,但完全没有提及Badge是如何mint出来的!实际上,虽然Attester合约里有一个mintBadges函数,但该函数在正式环境下似乎并不会被调用。
但该交易中又确实发生了Badge的转移,到底是在哪个地方触发的呢?
其实就是在我们前面忽略的一个函数里:ATTESTATIONS_REGISTRY.recordAttestations(attestations)
在这里,ATTESTATIONS_REGISTRY是一个IAttestationsRegistry对象(四舍五入就是AttestationsRegistry),我们查看AttestationsRegistry的源代码,recordAttestations函数定义如下:
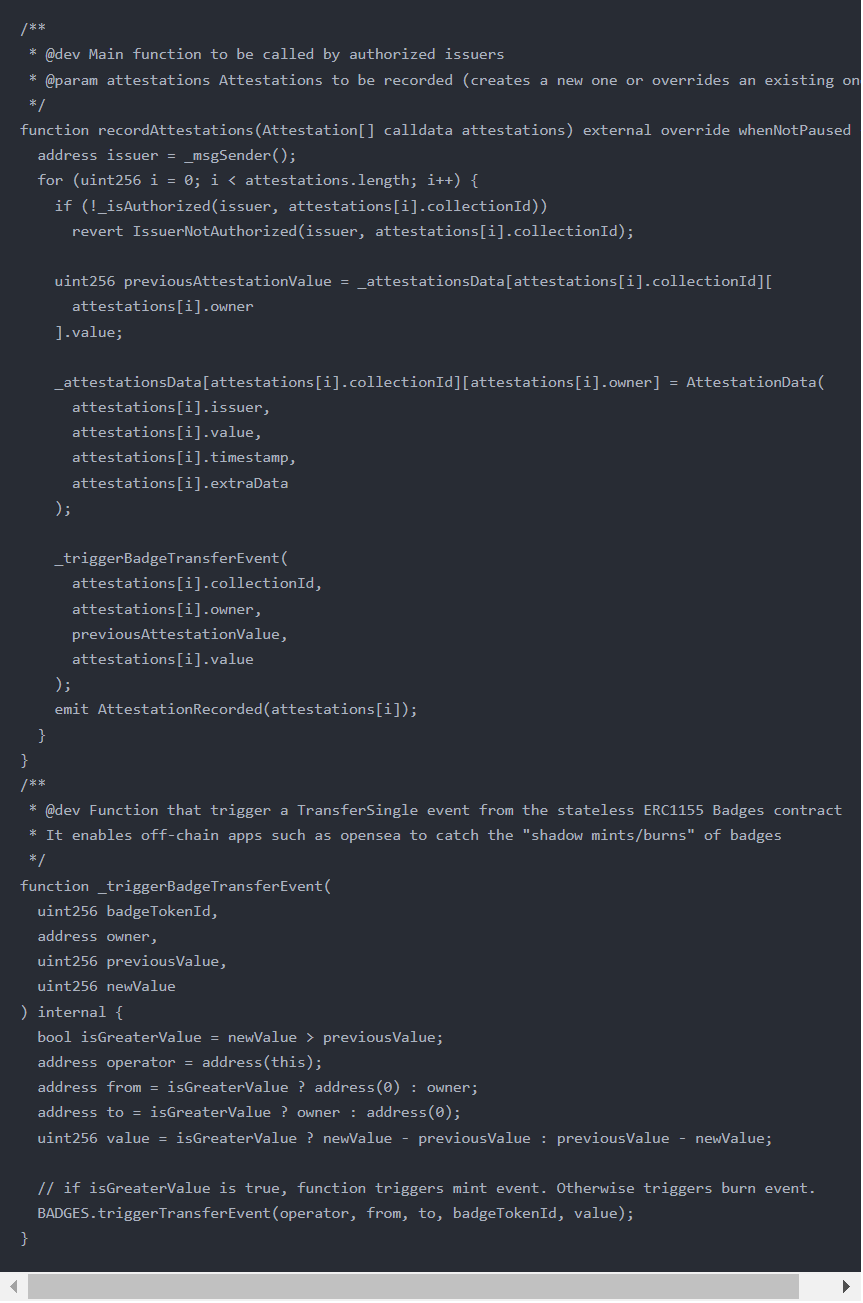
这个函数既保存了Attestation,也在_triggerBadgeTransferEvent函数里触发了Badge的Transfer事件:

Badges
BADGES是IBadges对象,我们可以看看Badges合约:
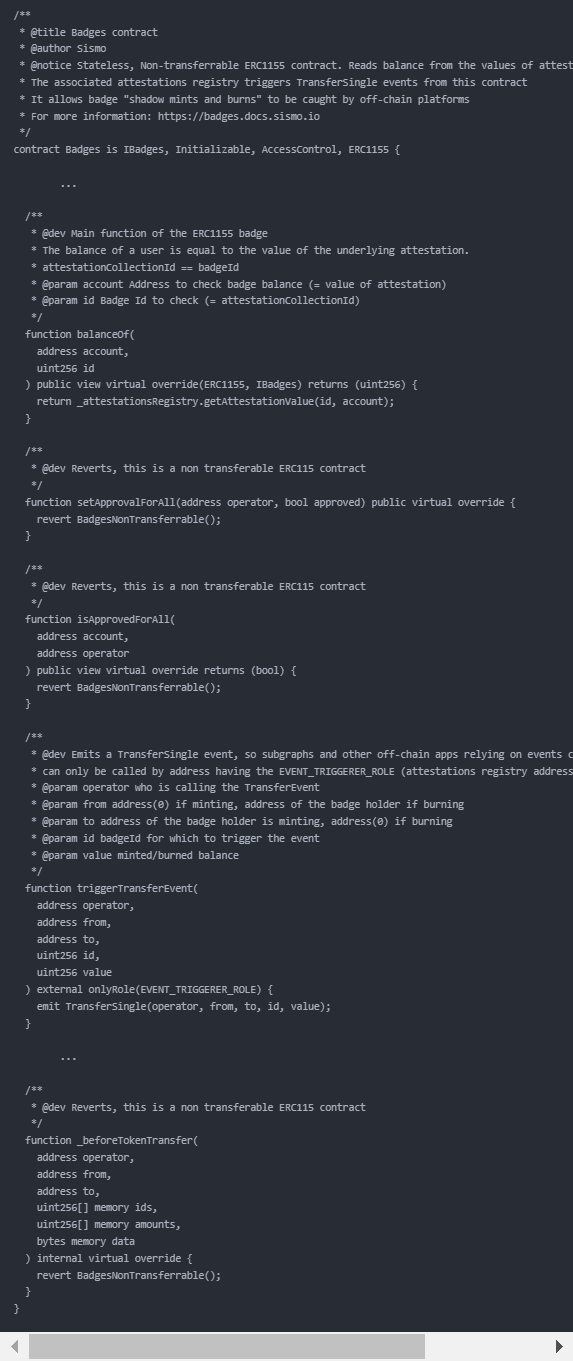
该合约最主要是处理三件事:
- 对Approval、Transfer等操作进行revert,确保其无法被转移
- triggerTransferEvent函数触发转移事件(用于GraphQL查询)
- 改写balanceOf函数,这也是ERC1155最主要的函数之一。改写之后,合约就直接获取AttestationRegistry里的Value来表示用户的勋章“数量”(价值)
也就是说,Badges合约虽然继承ERC1155,但其实它完全摒弃了ERC1155合约的内部功能,转为对AttestationRegistry的一层封装,使其满足ERC1155的接口规定。也就是说,实际上不存在“Transfer”或者“Mint”之类的操作,在生成Attestation的时候,Badge的数据已经被创造出来了,可以被Badges合约获取到了。
总结
至此,我们应该已经大致了解在领取Badge时候会发生的事情。如果仍有疑问,还是非常推荐大家直接看源码(文末会给出所有参考资料)。当然,本人水平有限,这里的解析也可能会有疏漏,欢迎大家批评指正~
0x04 Hydra-S1-ZKP
最后,我们聊聊Sismo的Hydra-S1方案,并尝试解读其电路代码。
官方文档:Hydra-S1 - Sismo Docs
Hydra-S1
Hydra-S1是一种用于验证所有权的证明方案,它是Hydra家族中的第一个方案。它旨在允许参与者通过一种零知识证明的方式,证明以下内容:
- 用户拥有两个账户:源账户和目标账户(源账户就是有数据的账户,目标账户就是我们mint Badge的目标账户)。
- 源账户是账户树的一部分,账户树是一个用于存储账户信息的数据结构。
- 源账户在账户注册树中注册,并具有特定的价值。
- 参与者对于源账户价值的Claim是真实的。可以是非严格的Claim(如超过某个值)或严格的Claim(如严格等于某个值)。
- 参与者正确生成了一个空值证明,用于确保他们无意中使用了相同的证明标识符。
Hydra-S1的应用场景包括验证Data Gem的所有权,以及发行ZK Badge。该方案通过使用零知识证明技术,确保了验证过程的隐私和安全性。Hydra-S1证明方案的目标是提供一种高效、可扩展且可靠的所有权验证机制。
其中:
- Hydra = 使用基于Commitment Mapper的Hydra所有权证明
- S1 = 单一来源,版本1:验证单个Data Gem的所有权
CommitmentMapper
Commitment Mapper是由Sismo提供的一个可信的Off-Chain服务,旨在将账户所有权的证明转化为秘密知识的证明。它通过将用户的账户与承诺(例如,秘密的哈希值)进行关联,形成委托的所有权证明。Commitment Mapper的工作方式如下:
- 用户提交账户所有权的证明,例如以太坊账户的ECDSA签名或Web2账户(如GitHub或Twitter)的OAuth验证,同时提交一个承诺,例如只有用户自己知道的秘密的哈希值或其中一个账户的EdDSA公钥。
- Commitment Mapper验证账户所有权证明的有效性,并将账户与承诺的对应关系记录在一个存储在数据库中的映射中。
- 如果账户已经与一个Commitment相关联,则Commitment Mapper返回错误。
- Commitment Mapper向用户发送一个已签名的承诺收据,确认用户已完成承诺过程。
- 用户可以随时通过提供新的账户所有权证明来获取承诺收据。
下面是Sismo官方文档的示例:
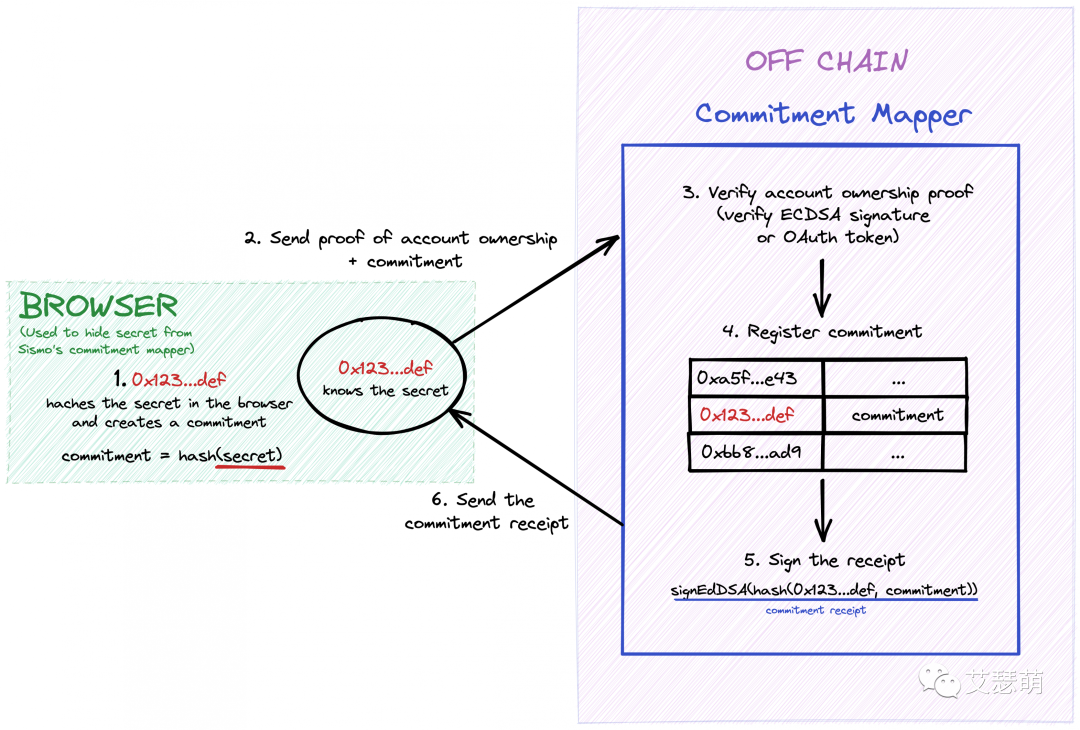
使用Commitment Mapper、Poseidon哈希函数和EdDSA数字签名方案(这些方案对SNARK友好),一个以太坊账户所有者和一个秘密Commitment将按照以下步骤进行操作:
- 0x123..def的所有者签署一条消息以证明所有权。
- 他们将签名与Commitment(poseidonHash(secret))一起发送。
- Commitment Mapper验证签名,并注册键值对:{key: 0x123...def, value: commitment = poseidonHash(secret)}。
- Commitment Mapper使用其EdDSA私钥(即后端内部私钥)对以下Receipt进行签名:poseidonHash(0x123...def, poseidonHash(secret))。
- 用户可以使用此Receipt在SNARK中证明他们知道这个秘密,并且已经成功注册到Commitment Mapper。
我们可以使用这个示例来理解使用Commitment Mapper、Poseidon哈希函数和EdDSA数字签名方案进行Hydra委托所有权证明的过程。
Commitment Mapper的作用在于在受限环境(如zk-SNARK电路)中使用更廉价的方式进行账户所有权的证明和验证。它使用EdDSA地址进行签名,这在SNARK中的证明和验证过程更加高效,这也是为什么使用Commitment Mapper。同时,Sismo采取了安全措施来确保Commitment Mapper的可信性,包括部署在隔离基础设施中、使用AWS KMS存储私钥以及进行详细的操作追踪和审计。
Sismo正在开发一个新版本的Commitment Mapper,该版本将减少对可信性的依赖。Commitment Mapper内部的操作将在SNARK中执行,并在链上进行验证。这将进一步提高Commitment Mapper的安全性和可靠性。
Commitment Mapper是开源的,GitHub:sismo-core/sismo-commitment-mapper (github.com)
电路源码
有了上面的介绍,我们最后来解读其电路源码:hydra-s1-zkps/hydra-s1.circom at main · sismo-core/hydra-s1-zkps · GitHub
- 定义电路模板:
(因为没有支持circom的语法高亮,这里我选择了Solidity)
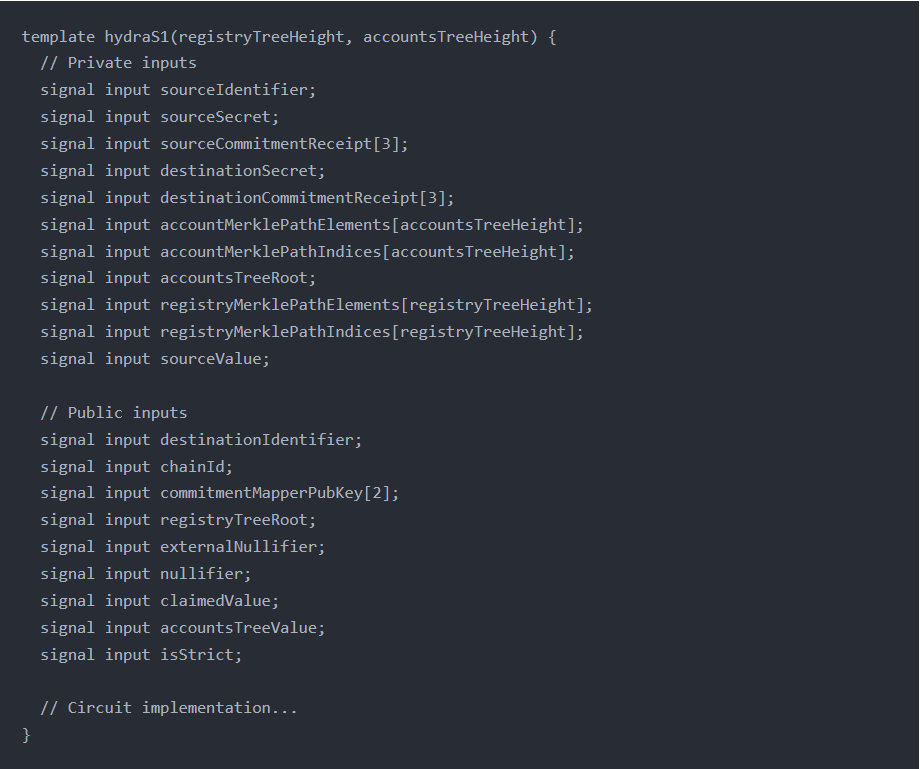
hydraS1是一个circom电路模板,它接收两个参数:registryTreeHeight和accountsTreeHeight,用于定义电路中的一些MerkleTree的高度。模板中包含了一系列私有输入和公共输入信号:
私有输入:
- sourceIdentifier: 源账户的标识符。
- sourceSecret: 源账户的秘密信息(上文Commitment Mapper中提到的那个Secret,实际上这个Secret可以随机生成,确保不会重复即可)。
- sourceCommitmentReceipt[3]: 源账户的Commitment Receipt,由三个输入组成。
- destinationSecret: 目标账户的秘密信息。
- destinationCommitmentReceipt[3]: 目标账户的Commitment Receipt,由三个输入组成。
- accountMerklePathElements[accountsTreeHeight]: 账户Merkle树路径中的元素列表,用于验证账户在Merkle树中的位置。
- accountMerklePathIndices[accountsTreeHeight]: 账户Merkle树路径中的索引列表,用于验证账户在Merkle树中的位置。
- accountsTreeRoot: 账户Merkle树的根哈希。
- registryMerklePathElements[registryTreeHeight]: 注册Merkle树路径中的元素列表,用于验证账户Merkle树在注册树中的位置。
- registryMerklePathIndices[registryTreeHeight]: 注册Merkle树路径中的索引列表,用于验证账户Merkle树在注册树中的位置。
- sourceValue: 源账户的价值(Data Gem中的Value)。
公共输入:
- destinationIdentifier: 目标账户的标识符(地址)。
- chainId: 区块链网络的ID。
- commitmentMapperPubKey[2]: Commitment Mapper的公钥,由两个输入组成。
- registryTreeRoot: 注册树MerkleRoot。
- externalNullifier: 外部nullifier。
- nullifier: nullifier。
- claimedValue: 要Claim的价值。
- accountsTreeValue: 账户MerkleTree的价值。
- isStrict: 是否严格模式,用于Claim价值的有效性验证(大于或严格等于)。
这些输入参数用于验证源账户和目标账户的拥有权、账户之间的关系、Claim价值有效性以及nullifier的有效性。通过提供正确的输入参数,电路可以执行相应的验证操作,并生成验证结果。
- 定义子组件:
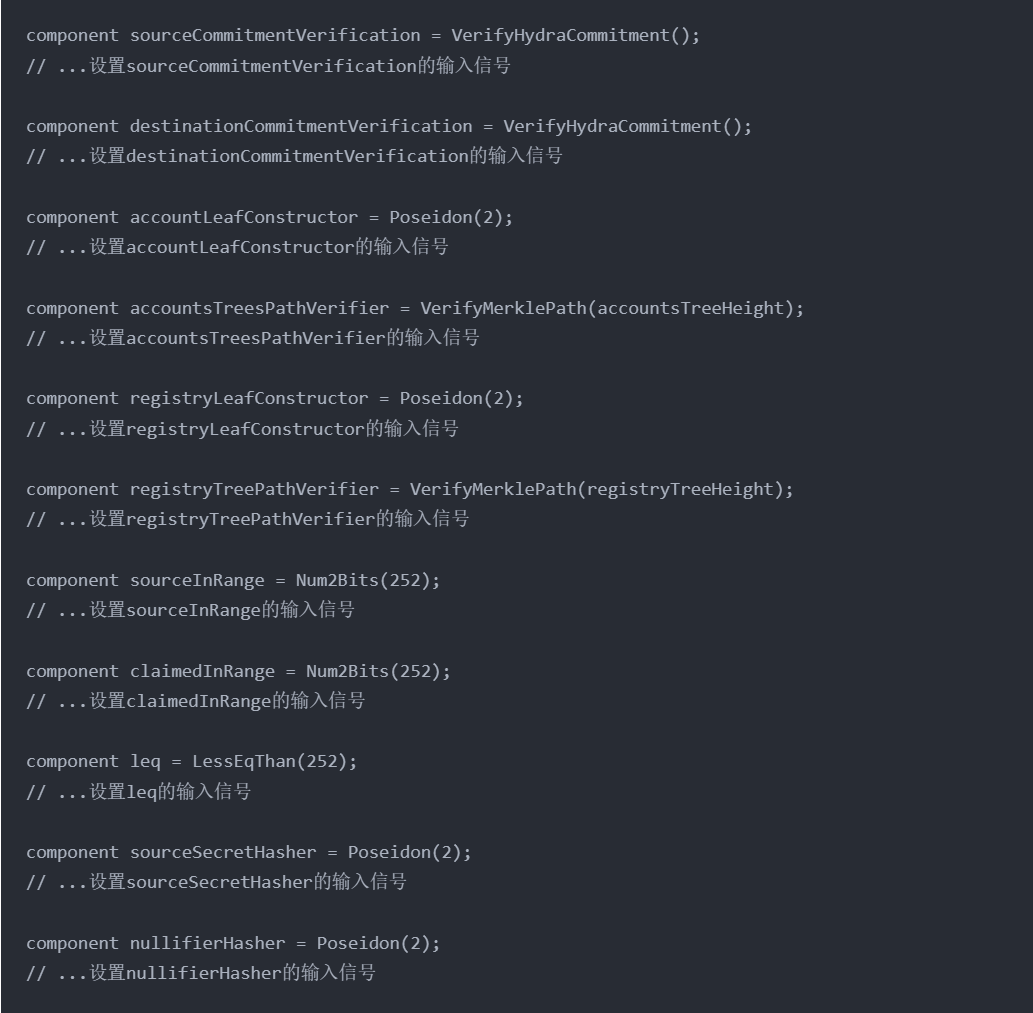
这部分定义了一系列子组件,并通过设置其输入信号来初始化这些组件:
- sourceCommitmentVerification: 源账户Commitment验证器,是一个VerifyHydraCommitment组件,该组件在common文件夹下有定义,最终是通过EdDSAPoseidonVerifier(circomlib下定义的组件)来验证的。
- destinationCommitmentVerification: 目标账户Commitment验证器,和sourceCommitmentVerification一样。
- accountLeafConstructor: 账户树的叶子构造器,是一个哈希函数,哈希的结果就是账户树的叶子(在MerkleTree下)。
- accountsTreesPathVerifier : 账户树路径验证器,是一个VerifyMerklePath组件,该组件在common文件夹下有定义,作用是根据叶子和MerkleTree路径信息构造回MerkleRoot,并对比该MerkleRoot和传入的MerkleRoot(accountsTreeRoot)是否一致,用于MerkleRoot验证。
- registryLeafConstructor: 注册树的叶子构造器,和accountLeafConstructor一样。
- registryTreePathVerifier: 注册树路径验证器,和accountsTreesPathVerifier 一样。
- sourceInRange: 确保sourceValue在一定范围内。
- claimedInRange: 确保claimedValue在一定范围内。
- leq: 小于等于比较器,比较sourceValue和claimedValue,具体而言,会通过判断isStrict来决定比较方式(是严格等于还是只是大于等于)。
- sourceSecretHasher : 用于计算和验证sourceSecret的哈希。
- nullifierHasher : 用于计算和验证nullifier的哈希。
- 进行各种验证操作:
对上面所说的每一个组件,设置相应的输入和执行验证。如验证源账户和目标账户通过了Hydra Delegated Proof of Ownership,验证账户是否属于账户树和注册树,验证声明的值的有效性以及验证nullifier是否有效。
- 返回主组件:
component main {public [commitmentMapperPubKey, registryTreeRoot, externalNullifier, nullifier, destinationIdentifier, claimedValue, chainId, accountsTreeValue, isStrict]} = hydraS1(20,20);
最后,通过将hydraS1模板实例化为名为main的主组件,并指定主组件的公共输出信号,以完成整个电路的构建。
在上面电路中,我们提到了两个组件:VerifyHydraCommitment和VerifyMerklePath,他们定义在common文件夹下:hydra-s1-zkps/circuits/common at main · sismo-core/hydra-s1-zkps · GitHub
这两个组件的代码,结合注释和上下文来看,还是比较简单易懂的,这里就不做过多的解释。其中,VerifyHydraCommitment是将输入进行Poseidon哈希后,通过EdDSAPoseidonVerifier来校验Commitment Receipt;VerifyMerklePath是使用输入的路径和叶子信息构造出MerkleTree并将得到的MerkleRoot与传入的MerkleRoot比较,来校验MerkleRoot。
电路调用
上面的电路代码写出来了,要怎么调用呢?
在JS中,我们可以使用snarkjs来编译和调用电路。不过,我们这篇文章已经写得够长了,这里就不继续展开了,我分享一些在我学习过程中看过的资料:
https://www.jianshu.com/p/7b772e5cdaef —— ZKSnark的介绍和数学原理(科普向,但也能学到很多)
Using Zero-Knowledge Proofs with Fluree Fluree(中文翻译:零知识证明实战渔业监控【zksnark】 | 学习软件编程 (hubwiz.com))—— 一个snarkjs的简单应用例子,非常好的入门教程
当然,Sismo的GitHub是最好的学习材料,在hydra-s1-zkps/test at main · sismo-core/hydra-s1-zkps (github.com)的test文件夹下,Sismo提供了几个测试文件(ts)来调用电路,值得我们参考。
对了,为了避免大家走弯路,也为了感谢大家能耐心看我一直胡扯到这里,我分享一个我遇到的大坑!
一般来说,我们执行zk电路,都是在前端执行的(如果是后端执行就失去zk的意义了)。按照Sismo的测试文件,我们把它迁移到前端开发也很顺利。那么大坑在哪里呢?
其实,我们在开发DAPP的时候,特别是前端,或多或少会遇到各种坑。比如一些npm包(比如web3.js)都是在node环境下的,导致浏览器环境下无法build,或者build出来无法运行,相信有经验的开发者都遇到过这些问题。
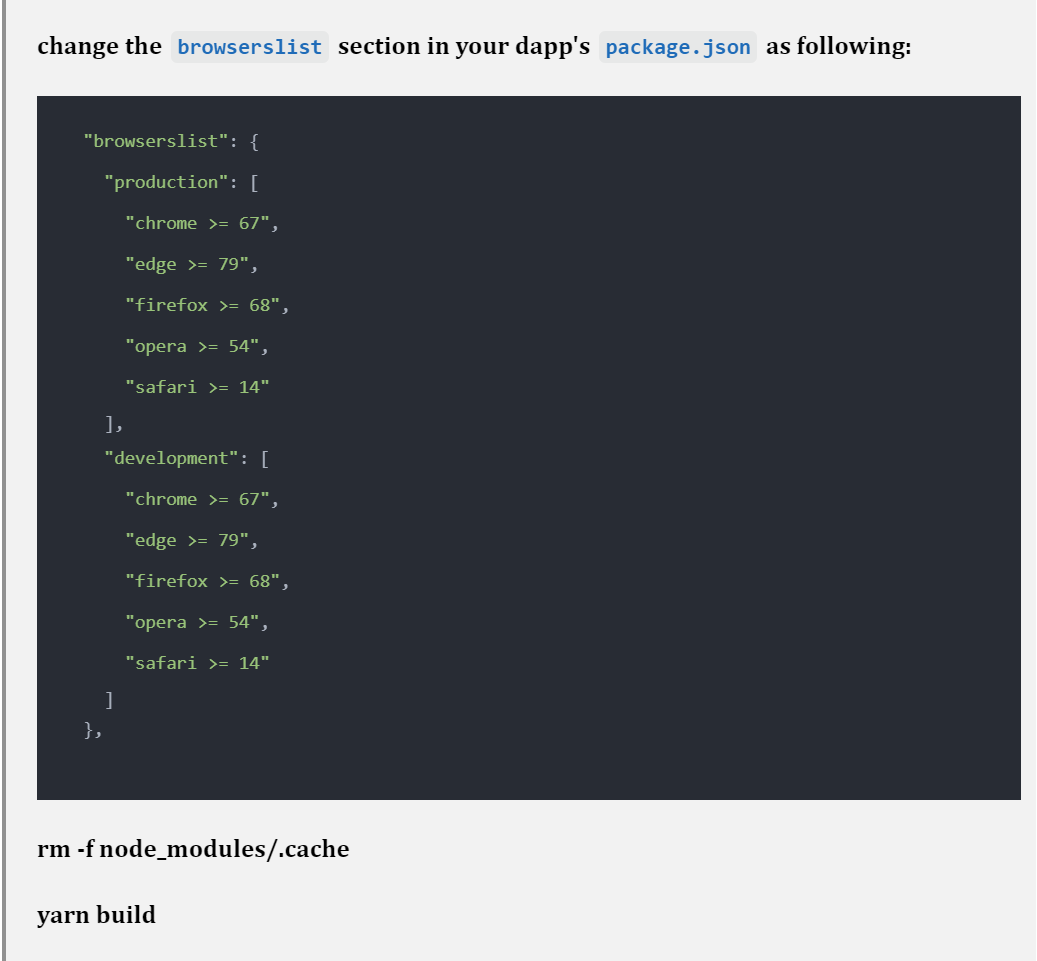
是的,snarkjs也有类似的问题,具体原因是BigInt在一些旧版本的JS里是不支持的,导致和BigInt相关的运算都会出错,直接导致snarkjs无法运行——而这一切都只有在build出来之后才会发生,往往你都不清楚这发生了什么,因为他不会直接提示你是因为BigInt的问题。
所以,我们发现问题所在,就好解决了。
我们可以参考Starcoin库的建议(@starcoin/starcoin - npm (npmjs.com))来进行修改:
0x05 参考资料
本文主要参考的资料如下:
【官方文档】Technical Concepts:Technical Concepts - Sismo Docs
【GitHub】Sismo Badges:sismo-core/sismo-badges: Contracts of the Sismo Badge Minting Protocol (github.com)
【GitHub】Sismo Hub:sismo-core/sismo-hub (github.com)
【GitHub】Hydra-S1-ZKP:sismo-core/hydra-s1-zkps: Hydra-S1 ZK Proving scheme circuits, used for ZK Attesters in Sismo (github.com)
【GitHub】Commitment Mapper:sismo-core/sismo-commitment-mapper (github.com)
【GitHub】Sismo Badges官方文档(已被删除,但可以从其docs仓库的历史版本中找到):https://github.com/sismo-core/sismo-docs/tree/3e717767f2dc9ef3719b9f94a337a421a6f02605/knowledge-base/resources/sismo-badges
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。
本文来源:a16zcrypto



24H热门新闻
暂无内容