



长推:a16z 新论文构建LLM工作流程的三个阶段
@indigo11热度: 12710
当用户提交一个查询时,应用程序会构建一系列的提示词给大语言模型。
原文作者:@indigo11
原文来源:Twitter
注:原文来自@indigo11发布长推。
A16Z 最新的这篇“LLM 应用的新兴架构”来自他们对 AI 初创企业中创始人与工程师的对谈总结,非常清晰的概括了现在基于大语言模型的开发模式。不过这一切非常早期,随着底层技术的发展,可能会有很大的变化。
https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/…
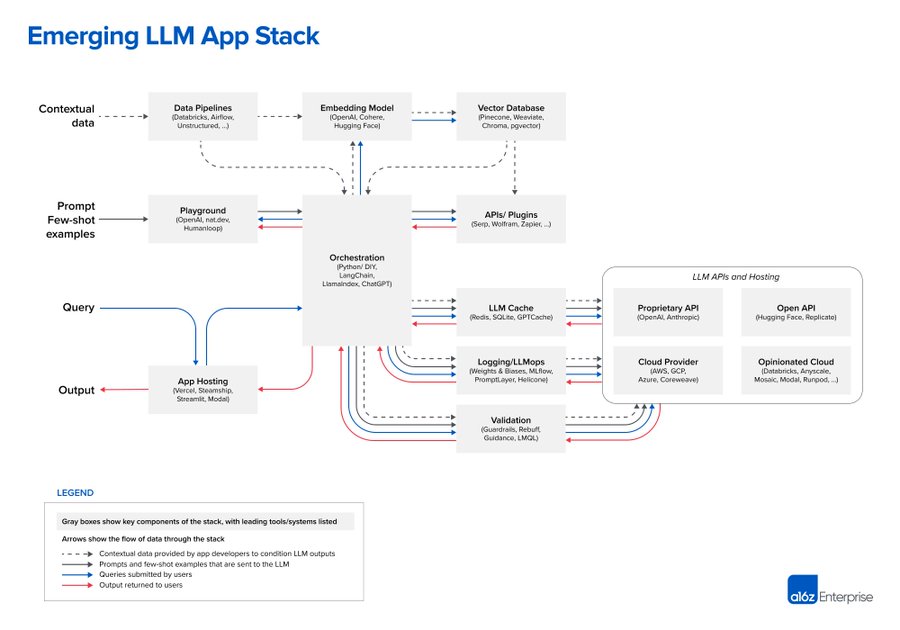
大家有很多方法来构建LLM,从头开始训练模型,微调开源模型,或者直接使用托管 API。这里展示的设计模式是只有在大模型中可以做到的 In-context Learning(语境学习),其工作流程可以分为三个阶段: 1. 数据预处理与嵌入 2. 提示词构建与检索 3. 提示词执行与推理。
1. Data preprocessing / embedding:这个阶段涉及存储私人数据,以便以后检索。通常情况下,文件被分成几块,通过一个嵌入模型,然后存储在一个称为矢量数据库的专门数据库中。
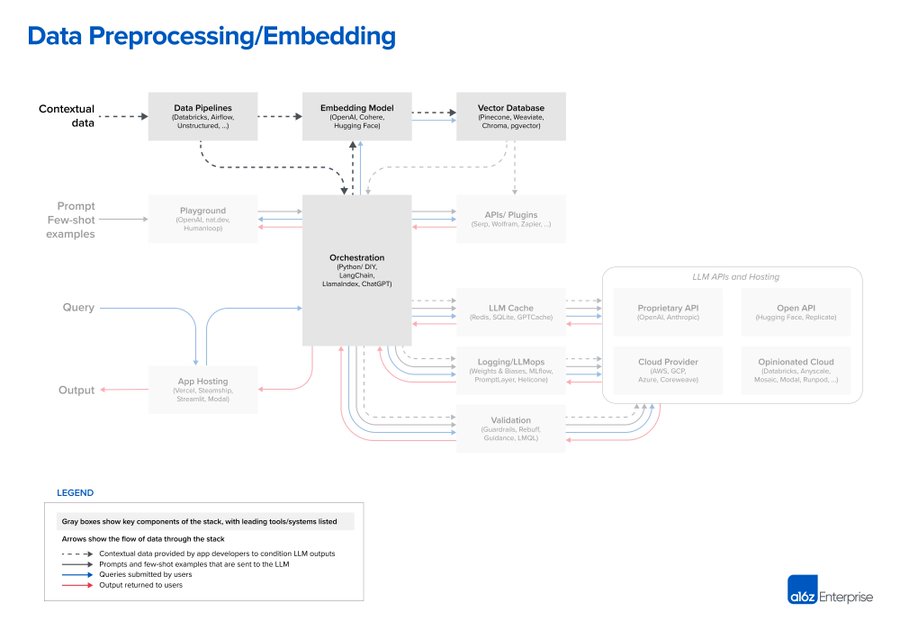
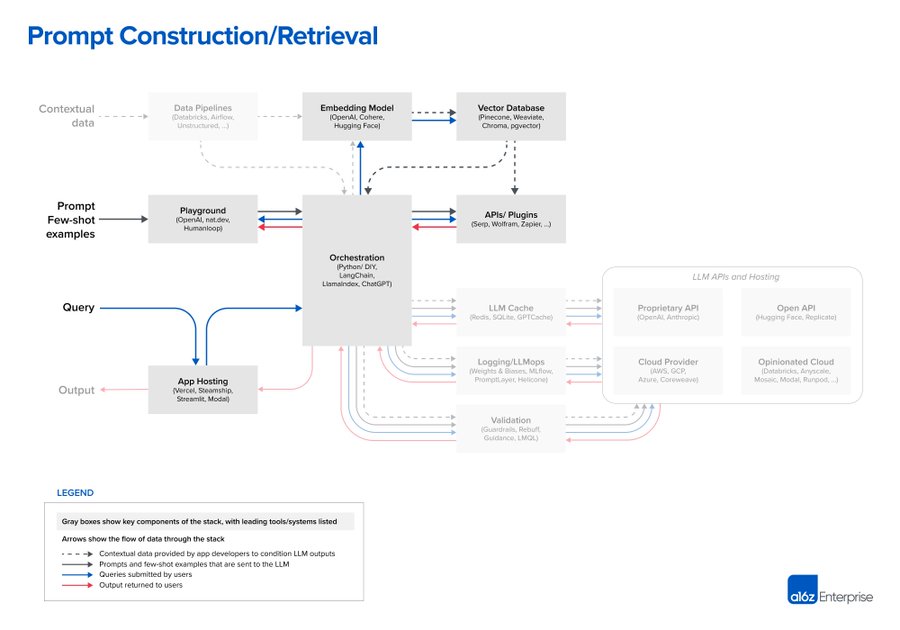
2. Prompt construction / retrieval:当用户提交一个查询时,应用程序会构建一系列的提示词给大语言模型。提示词通常结合了由开发者硬编码的提示模板;为得到有效输出,使用 few-shots 的方式,可以是从外部 API 检索的任何必要信息,或者是从矢量数据库检索到相关文件。
3. Prompt execution / inference::一旦提示词被编译,它们就被提交给预先训练好的 LLM 进行推理,这里包括了闭源模型的 API、开源或自我训练的模型。一些开发者还在这一阶段添加了日志、缓存和验证等系统操作。
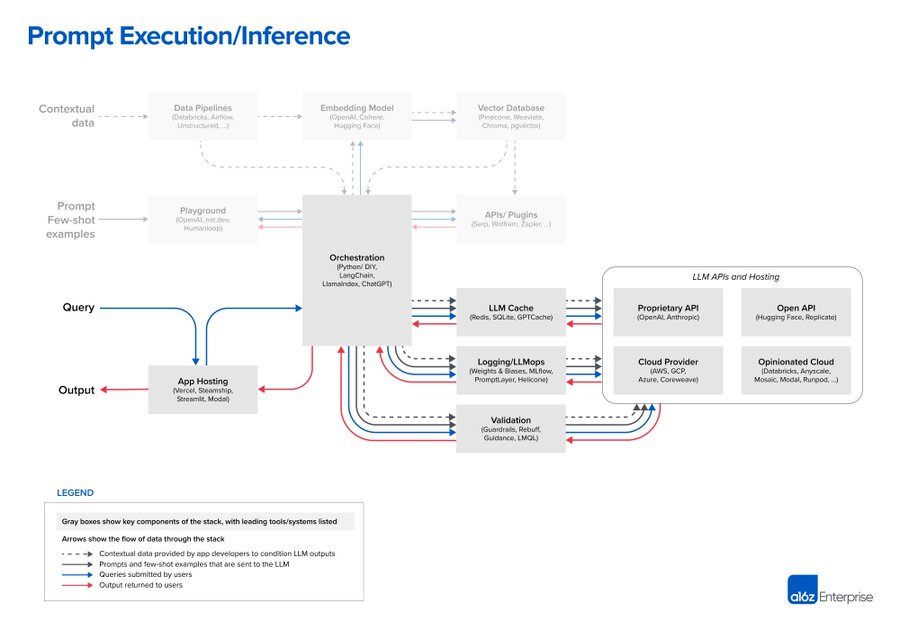
这种模式有效地将人工智能问题变成了数据工程问题。对于相对较小的数据集,它的表现往往优于微调,或者自己训练模型。预训练的大模型代表了自互联网以来,软件中最重要的架构变化,文中列举的模式只是整合 LLM 的起点,而不是最终形态。
本内容旨在传递行业动态,不构成投资建议或承诺。


