




Dragonfly 合伙人:“不要信任,亲自验证”在去中心化推理中的应用
Haseeb Qureshi热度: 12279
大型语言模型Llama2-70B需要超过140GB内存,无法在家用计算机运行。解决方案有转向云服务,但信任问题仍存在。可验证推断有三种方法:零知识证明(高成本)、乐观型欺诈证明(安全但成本高)、加密经济学(安全且成本低)。每种方法都有优缺点,需要根据网络参数和需求选择。GPT-3推断成本约为1 petaflop,但博弈论表明几乎不可能发生。验证ML困难,因为计算图不是为了被证明而设计。去中心化推理网络需要考虑许多细节,但区块链和机器学习都是创造信任的技术。期待企业家如何利用这些工具来构建最佳网络。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文标题:Don’t Trust, Verify: An Overview of Decentralized Inference
原文作者:Haseeb Qureshi
原文来源:medium
编译:深潮TechFlow
你想要运行一个像 Llama2–70B 这样的大型语言模型。如此庞大的模型需要超过 140GB 的内存,这意味着您无法在家用计算机上运行原始模型。那么你有哪些选择?你可能会转向云服务提供商,但你可能不太愿意信任一个单一的中心化公司来为你处理这个工作负载并收集你所有的使用数据。那么你需要的是去中心化推断,它可以让你运行机器学习模型而不依赖于任何单一的提供商。
信任问题
在去中心化网络中,仅仅运行模型并信任输出是不够的。假设我让网络使用 Llama2–70B 分析一个治理困境,我怎么知道它实际上没有使用 Llama2-13B,给我提供了更糟糕的分析,并将差额收入囊中?
在中心化的世界中,你可能会相信像 OpenAI 这样的公司是诚实的,因为它们的声誉受到了威胁(而且在某种程度上,LLM 的质量是不言而喻的)。但在去中心化的世界中,诚实并不是默认的,它需要经过验证。
这就是可验证推断发挥作用的地方。除了对查询提供响应之外,你还要证明它在你请求的模型上正确运行了。但是怎么做呢?
最简单的方法是将模型作为智能合约在链上运行。这肯定可以保证输出经过验证,但这是极其不切实际的。GPT-3 用一个维度为 12,288 的嵌入来表示单词。如果你在链上进行这个大小的单次矩阵乘法运算,根据当前的Gas价格,它将花费约100亿美元,这个计算将填满每一个区块大约一个月的时间。
所以,我们需要采取不同的方法。
观察了这个领域之后,我清楚地看到了三种主要的方法,用于解决可验证推断:零知识证明、乐观型欺诈证明和加密经济学。每种方法都有其自身的安全和成本影响。
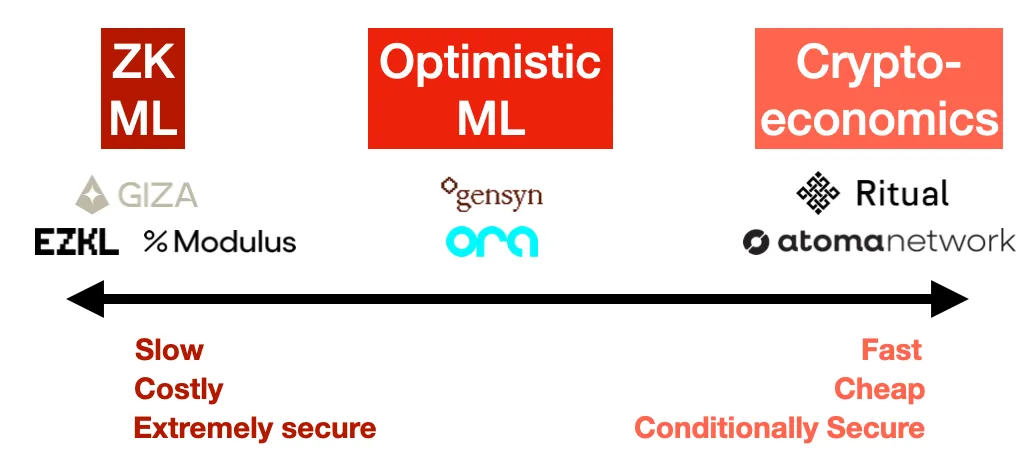
1.零知识证明(ZK ML)
想象一下能够证明你运行了一个大型模型,但证明的大小实际上是固定的,不管模型有多大。这就是 ZK ML(机器学习) 所承诺的,通过 ZK-SNARK实现。
虽然原则上听起来很优雅,但将一个深度神经网络编译成零知识电路,然后证明它,是极其困难的。而且成本极高 ,至少,你可能会看到推断成本增加了1000倍,延迟增加了1000倍(生成证明的时间),更不用说在任何事情发生之前,将模型本身编译成电路。最终,这个成本必须转嫁给用户,因此对终端用户来说,这将变得非常昂贵。
另一方面,这是唯一一种在密码学上保证正确性的方法。使用 ZK,无论模型提供者多么努力,都无法作弊。但是这样做的成本很高,使得这对于可预见的未来的大型模型来说是不切实际的。
示例:EZKL, Modulus Labs, Giza
2.乐观型欺诈证明(Optimistic ML)
乐观的方法是相信,但要验证。我们假设推断是正确的,除非证明相反。如果一个节点试图作弊,“观察者”可以在网络中指出作弊者,并使用欺诈证明对其进行挑战。这些观察者必须随时观察链,并重新运行他们自己的模型以确保输出正确。
这些欺诈证明是 Truebit 风格的交互式挑战:响应游戏,在游戏中,你要反复在链上对模型执行轨迹进行分割,直到找到错误为止。
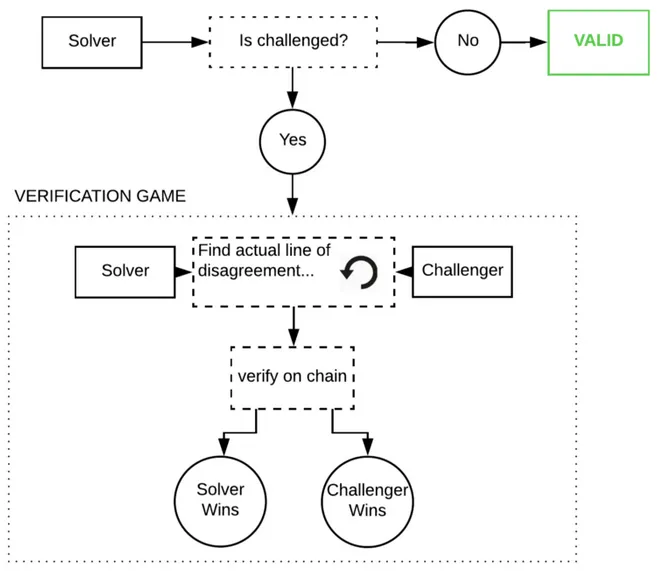
如果这确实发生了,那将是极其昂贵的,因为这些程序庞大且具有巨大的内部状态,一个单独的 GPT-3 推断成本约为 1 petaflop(10⁵ 浮点运算)。但是博弈论表明,这几乎不可能发生(欺诈证明在编码时也非常难以正确编写,因为在实际生产中几乎不会执行到这段代码)。
乐观的好处是,只要有一个诚实的观察者在关注,ML 就是安全的。成本比 ZK ML 便宜,但请记住,网络中的每个观察者都在重新运行每个查询。在平衡状态下,这意味着如果有10个观察者,那么安全成本必须转嫁给用户,所以他们将不得不支付超过10倍推断成本的费用(或者有多少观察者就支付多少)。
缺点是,与乐观型聚合技术一样,你必须等待挑战期结束,以确保响应已被验证。但是,根据网络参数的设置方式,你可能只需要等待几分钟而不是几天。
3.加密经济学(Cryptoeconomic ML)
在这里,我们放弃所有花哨的技术,做简单的事情:权益加权投票。用户决定有多少节点应该运行他们的查询,它们各自透露他们的响应,如果响应之间有差异,那么奇怪的节点就会被砍掉。标准的预言机机制,这是一个更直接的方法,让用户设定他们想要的安全级别,平衡成本和信任。如果 Chainlink 在做 ML,这就是他们会采取的方式。
这里的延迟很快,你只需要每个节点的提交和揭示。如果这被写入到区块链中,那么从技术上讲,这可以在两个区块中发生。
然而,安全性是最弱的。如果大多数节点都愿意合作,那么它们可以理性地选择合谋。作为用户,你必须思考这些节点投入了多少,并且作弊会给他们带来多大的成本。也就是说,使用类似 Eigenlayer 的重新质押和可归因的安全性,网络可以在安全失败的情况下提供有效的保险。
但这个系统的好处是用户可以指定他们想要多少安全性。他们可以选择在他们的法定数量中有3个节点或5个节点,或者是网络中的每个节点。或者,如果他们想要冒险,他们甚至可以选择 n=1。这里的成本函数很简单:用户为他们的 quorum 中想要的法定数量支付费用。如果你选择了3个,你就要支付3倍的推断成本。
这里的棘手问题是:你能让 n=1 安全吗?在一个简单的实现中,一个孤立的节点应该每次都会作弊,如果没有人监督的话。但我怀疑,如果你加密查询并通过意向进行支付,你可能能够对节点隐瞒他们实际上是唯一回应这个任务的节点。在这种情况下,你可能可以向普通用户收取少于2倍推断成本的费用。
最终,加密经济学方法是最简单、最容易的,也可能是最便宜的,但从原则上讲,它是最不引人注目和最不安全的。但是一如既往,细节决定成败。
示例:Ritual 、Atoma Network
为什么可验证的 ML 很难
你可能会想,为什么我们还没有所有这些东西呢?毕竟,归根结底,ML模型只是非常大的计算机程序。证明程序正确执行一直是区块链的核心。
这就是为什么这三种验证方法反映了区块链如何保护其区块空间的方式,ZK rollup使用 ZK 证明,乐观型rollup使用欺诈证明,大多数 L1 区块链使用加密经济学。毫无疑问,我们最终会得出基本相同的解决方案。那么当应用于 ML 时,是什么使这变得困难?
ML 是独特的,因为 ML 计算通常被表示为密集的计算图,旨在在 GPU 上高效运行。它们不是为了被证明而设计的。因此,如果你想在 ZK 或乐观环境中证明 ML 计算,它们必须重新编译成可行的格式,这是非常复杂和昂贵的。
机器学习的第二个基本困难是非确定性。程序验证假设程序的输出是确定性的。但是,如果你在不同的 GPU 架构或 CUDA 版本上运行相同的模型,你会得到不同的输出。即使你强制每个节点使用相同的架构,你仍然会遇到算法中使用的随机性问题(扩散模型中的噪声,或者LLM中的代币抽样)。你可以通过控制随机数种子来修复这种随机性。但即使如此,你仍然会面临最后一个令人不安的问题:浮点运算中固有的非确定性。
几乎所有的 GPU 操作都是在浮点数上进行的。浮点数很难处理,因为它们不是可结合的——也就是说,对于浮点数来说,(a + b) + c 总是与 a + (b + c) 相同这种说法并不正确。由于 GPU 高度并行化,每次执行时加法或乘法的顺序可能会不同,这可能会导致输出中的小差异。这不太可能影响LLM的输出,因为单词的离散性质,但对于图像模型来说,可能会导致像素值微妙地不同,从而使两个图像不能完全匹配。
这意味着你要么需要避免使用浮点数,这会对性能造成巨大的打击,要么你需要在比较输出时允许一些灵活性。无论哪种方式,细节都很烦琐,你无法完全抽象出来。(这就是为什么以太坊虚拟机不支持浮点数,尽管一些区块链如NEAR支持浮点数的原因。)
简而言之,去中心化推理网络很难,因为所有的细节都很重要,而现实中的细节却出人意料地多。
总结
目前,区块链和机器学习显然有很多共同之处。其中一个是创造信任的技术,另一个则是迫切需要信任的技术。虽然去中心化推理的每种方法都有其自身的权衡,但我非常感兴趣地想看看企业家们如何利用这些工具来构建最好的网络。
本内容旨在传递行业动态,不构成投资建议或承诺。


