




NEAR:为何AI需要Web3?Web3究竟会给AI带来什么样的颠覆式进步
IOSG Ventures热度: 22598
4月17日,IOSG Ventures举办了第十二届老友记活动,主题为《Singularity: AI x Crypto Convergence》。与会者分享了人工智能和加密货币领域的融合对未来的影响。其中,IOSG Ventures联合创始人Illia Polosukhin发表了《Why AI Needs to be Open - 为何AI需要Web3》的主题演讲,探讨了人工智能领域的开放性。他介绍了自己的背景和对人工智能发展的看法,以及如何利用区块链技术解决挑战。讨论了AI x Crypto的发展趋势,包括加速创新和保护用户免受互联网危险。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文作者:IOSG Ventures
原文来源:IOSG Ventures
4月17日,IOSG Ventures 第十二届老友记(Old Friends Reunion)如期举行,本次活动主题为《Singularity: AI x Crypto Convergence》, 因此,我们也邀请了行业中正在崭露头角的杰出代表。这次聚会的目的是让参与者共同探讨人工智能和加密货币领域的融合之处,以及这种融合对未来的影响。在这样的活动中,与会者有机会分享他们的见解、经验和想法,从而促进行业内的合作与创新。
接下来是本次活动的Keynote之一,由来自 IOSG Ventures的 Portfolio NEAR Protocol 的联合创始人 Illia Polosukhin 为大家带来 《Why AI Needs to be Open - 为何AI需要Web3》

Why AI Needs to be Open
让我们来探讨一下“为什么人工智能需要开放”。我的背景是Machine Learning,在我的职业生涯中大约有十年的时间一直在从事各种机器学习的工作。但在涉足Crypto、自然语言理解和创立NEAR之前,我曾在谷歌工作。我们现在开发了驱动大部分现代人工智能的框架,名为Transformer。离开谷歌之后,我开始了一家Machine Learning公司,以便我们能够教会机器编程,从而改变我们如何与计算机互动。但我们没有在2017或者18年这样做,那时候太早了,当时也没有计算能力和数据来做到这一点。

我们当时所做的是吸引世界各地的人们为我们做标注数据的工作,大多数是学生。他们在中国、亚洲和东欧。其中许多人在这些国家没有银行账户。美国不太愿意轻易汇款,所以我们开始想要使用区块链作为我们问题的解决方案。我们希望以一种程序化的方式向全球的人们支付,无论他们身在何处,都能让这变得更加容易。顺便说一句,Crypto的目前挑战是,现在虽然NEAR解决了很多问题,但通常情况下,你需要先购买一些Crypto,才能在区块链上进行交易来赚取,这个过程反其道而行了。
就像企业一样,他们会说,嘿,首先,你需要购买一些公司的股权才能使用它。这是我们NEAR正在解决的很多问题之一。现在让我们稍微深入讨论一下人工智能方面。语言模型并不是什么新鲜事物,50年代就存在了。它是一种在自然语言工具中被广泛使用的统计工具。很长一段时间以来,从2013年开始,随着深度学习重新被重新启动,一种新的创新就开始了。这种创新是你可以匹配单词,新增到多维度的向量中并转换为数学形式。这与深度学习模型配合得很好,它们只是大量的矩阵乘法和激活函数。

这使我们能够开始进行先进的深度学习,并训练模型来做很多有趣的事情。现在回顾起来,我们当时正在做的是神经元神经网络,它们在很大程度上是模仿人类的模型,我们一次可以读取一个单词。因此,这样做速度非常慢,对吧。如果你试图在Google.com上为用户展示一些内容,没有人会等待去阅读维基百科,比如说五分钟后才给出答案,但你希望马上得到答案。因此,Transformers 模型,也就是驱动ChatGPT、Midjourney以及所有最近的进展的模型,都是同样来自这样的想法,都希望有一个能够并行处理数据、能够推理、能够立即给出答案。
因此这个想法在这里的一个主要创新是,即每个单词、每个token、每个图像块都是并行处理的,利用了我们具有高度并行计算能力的GPU和其他加速器。通过这样做,我们能够以规模化的方式对其进行推理。这种规模化能够扩大训练规模,从而处理自动训练数据。因此,在此之后,我们看到了 Dopamine,它在短时间内做出了惊人的工作,实现了爆炸式的训练。它拥有大量的文本,开始在推理和理解世界语言方面取得了惊人的成果。
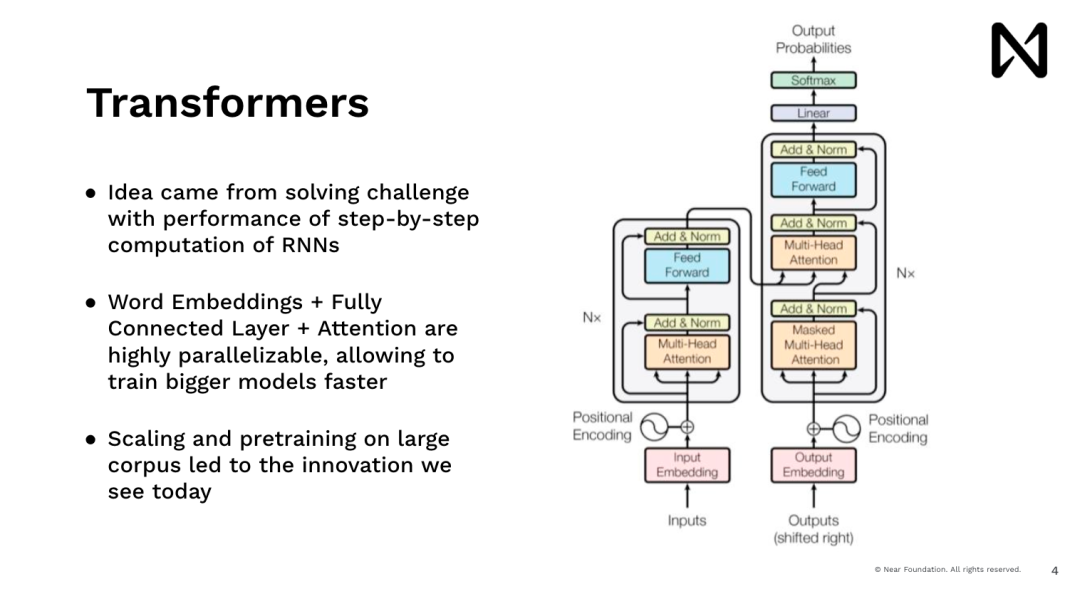
现在的方向是加速创新人工智能,之前它是一种数据科学家、机器学习工程师会使用的一种工具,然后以某种方式,解释在他们的产品中或者能够去与决策者讨论数据的内容。现在我们有了这种 AI 直接与人交流的模式。你甚至可能都不知道你在与模型交流,因为它实际上隐藏在产品背后。因此,我们经历了这种转变,从之前那些理解AI 如何工作的,转变成了理解并能够将其使用。

因此,我在这里给你们一些背景,当我们说我们在使用GPU来训练模型时,这不是我们桌面上玩视频游戏时用的那种游戏GPU。

每台机器通常配备八个GPU,它们都通过一个主板相互连接,然后堆叠成机架,每个机架大约有16台机器。现在,所有这些机架也都通过专用的网络电缆相互连接,以确保信息可以在GPU之间直接极速传输。因此,信息不适合CPU。实际上,你根本不会在CPU上处理它。所有的计算都发生在GPU上。所以这是一个超级计算机设置。再次强调,这不是传统的“嘿,这是一个GPU的事情”。所以规模如GPU4的模型在大约三个月的时间里使用了10,000个H100进行训练,费用达到6400万美元。大家了解当前成本的规模是什么样的以及对于训练一些现代模型的支出是多少。
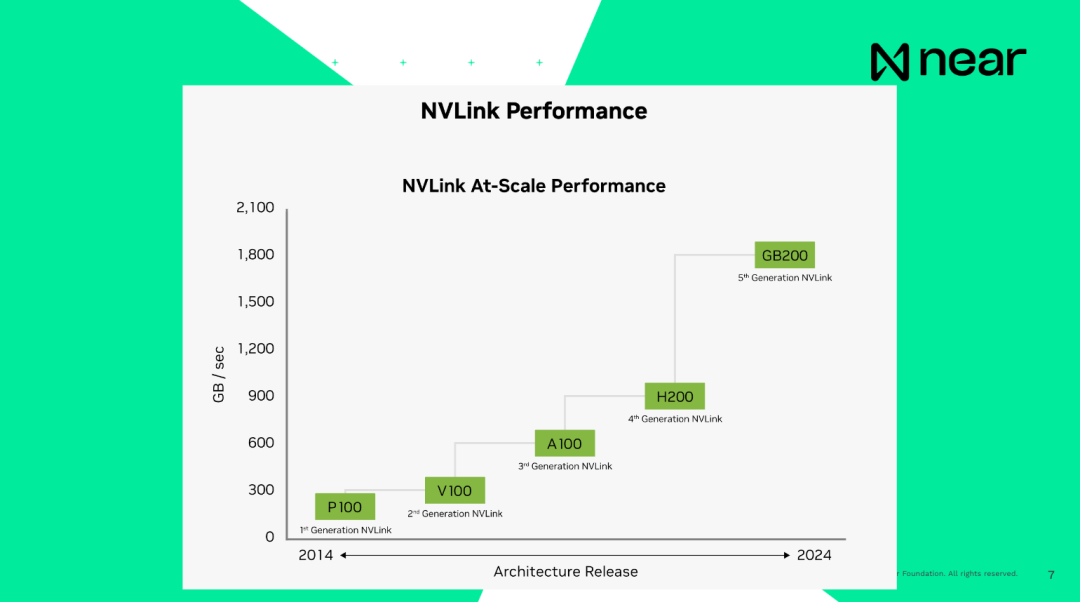
重要的是,当我说系统是相互连接的时候,目前H100的连接速度,即上一代产品,是每秒900GB,计算机内部 CPU 与 RAM 之间的连接速度是每秒 200GB,都是电脑本地的。因此,在同一个数据中心内从一个GPU发送数据到另一个GPU的速度比你的计算机还快。你的计算机基本上可以在箱子里自己进行通信。而新一代产品的连接速度基本上是每秒1.8TB。从开发者的角度来看,这不是一个个体的计算单元。这些是超级计算机,拥有一个巨大的内存和计算能力,为你提供了极大规模的计算。
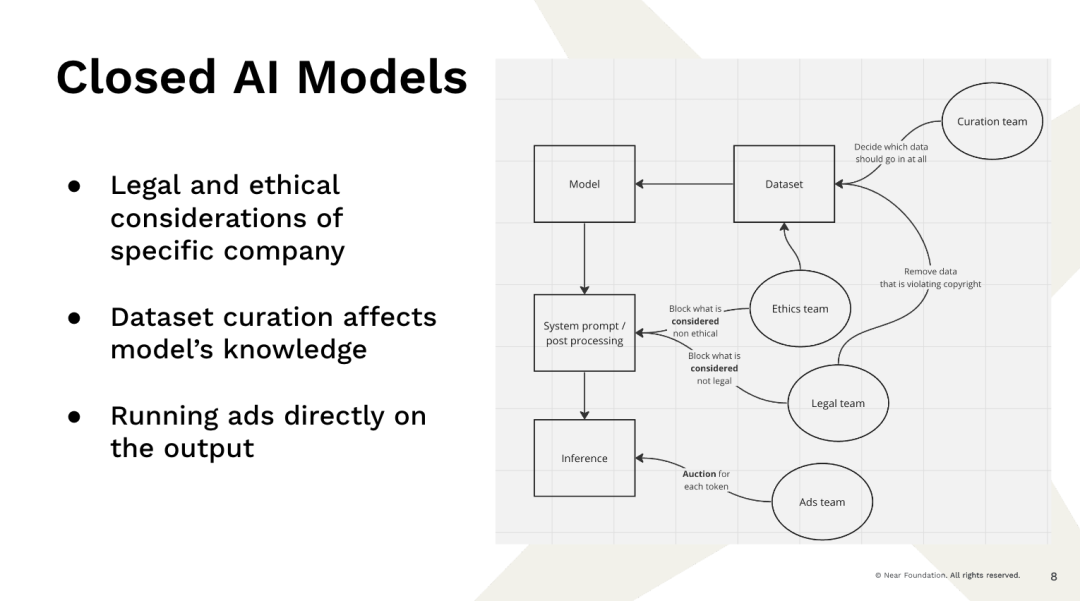
现在,这导致了我们面临的问题,即这些大公司拥有资源和能力来构建这些模型,这些模型现在几乎已经为我们提供了这种服务,我不知道其中究竟有多少工作,对吧?所以这就是一个例子,对吧?你去找一个完全集中式的公司提供者,然后输入一个查询。结果是,有几个团队并不是软件工程团队,而是决定结果如何显示的团队,对吧?你有一个团队决定哪些数据进入数据集。
举个例子,如果你只是从互联网上爬取数据,关于巴拉克·奥巴马出生在肯尼亚和巴拉克·奥巴马出生在夏威夷的次数是完全相同的,因为人们喜欢猜测争议。所以你要决定要在什么上进行训练。你要决定过滤掉一些信息,因为你不相信这是真的。因此,若像这样的个人已经决定哪些数据会被采用且存在这些数据,这些决定在很大程度上是由做出它们的人所影响的。你有一个法律团队决定我们不能查看哪些内容是受版权保护,哪些是非法的。我们有一个“道德团队”决定什么是不道德的,我们不应该展示什么内容。
所以在某种程度上,有很多这样的过滤和操纵行为。这些模型是统计模型。它们会从数据中挑选出来。如果数据中没有某些内容,它们就不会知道答案。如果数据中有某些内容,它们很可能会将其视为事实。现在,当你从AI得到一个回答时,这可能会令人担忧。对吧。现在,你理应是从模型那里得到回答,但是没有任何的保证。你不知道结果是如何生成的。一个公司可能会把你的特定会话卖给出价最高的人来实际改变结果。想象一下,你去询问应该买哪种车,丰田公司决定觉得应该偏向丰田这个结果,丰田将支付这家公司10美分来做到这一点。

因此,即使你将这些模型用作应该中立并代表数据的知识库,实际上在你得到结果之前,会发生很多事情,这些事情会以一种非常特定的方式对结果进行偏见。这已经引发了很多问题,对吧?这基本上就是大公司和媒体之间不同法律诉讼的一个星期。SEC,现在几乎每个人都在试图起诉对方,因为这些模型带来了如此多的不确定性和权力。而且,如果往前看,问题在于大型科技公司将永远有继续增加收入的动机,对吧?比如,如果你是一家上市公司,你需要报告收入,你需要继续保持增长。
为了实现这一目标,如果你已经占据了目标市场,比如说你已经有20亿用户了。在互联网上已经没有那么多新用户了。你没有太多的选择,除了最大化平均收入,这意味着你需要从用户那里提取更多的价值,而他们可能根本没有什么价值,或者你需要改变他们的行为。生成式人工智能非常擅长于操纵和改变用户的行为,特别是如果人们认为它是以一切知识智能的形式出现的。因此,我们面临着这种非常危险的情况,在这种情况下,监管压力很大,监管机构并不完全了解这项技术的工作原理。我们几乎没有保护用户免受操纵的情况。

操纵性内容、误导性内容,即使没有广告,你也可以只是截取一些东西的屏幕截图,改变标题,发布到Twitter上,人们就会发疯。你有经济激励机制,导致你不断地最大化收入。而且,这实际上不像在谷歌内部你是在做恶事,对吧?当你决定启动哪个模型时,你会进行A或B测试,看看哪个能带来更多收入。因此,你会通过从用户那里提取更多价值来不断地最大化收入。而且,用户和社区并没有对模型的内容、使用的数据以及实际尝试实现的目标有任何输入。这就是应用程序用户的情况。这是一种调节。
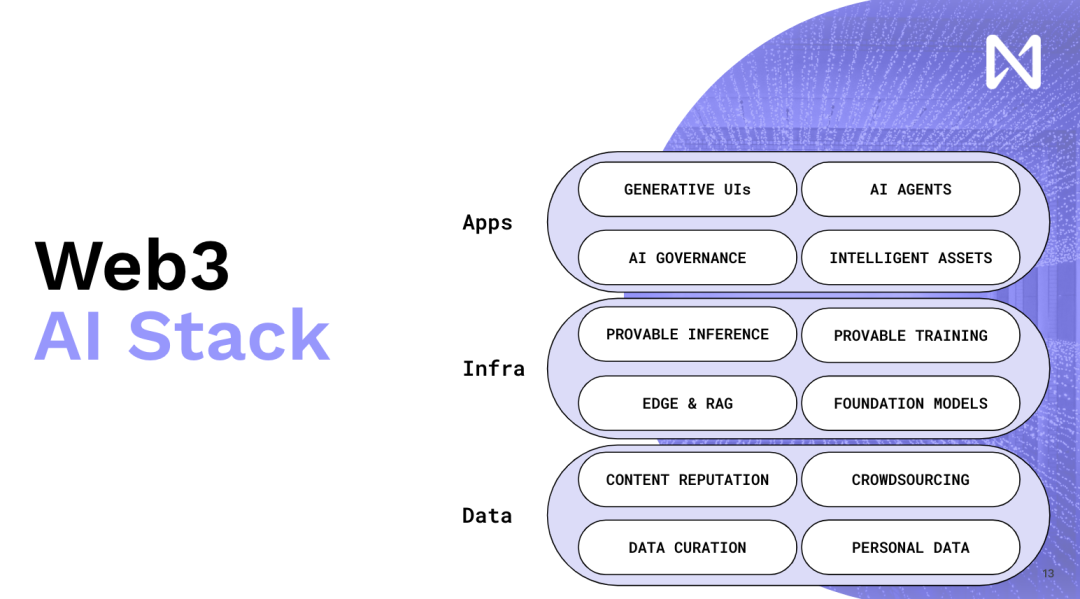
这就是为什么我们要不断推动WEB 3和AI融合的原因,web 3 可以是一种重要的工具,它允许我们有新的激励方式,并且还是以去中心化的形式去激励我们生产更好的软件和产品。这是整个web 3 AI 开发的大方向, 现在为了帮助理解细节,我会简单讲一下具体的部分,首先第一部分是Content Reputation。

再次强调,这不是一个纯粹的人工智能问题,尽管语言模型为人们操纵和利用信息带来了巨大的影响力并扩大了规模。你想要的是一种可以追踪的、可追溯的加密声誉,当你查看不同的内容时,它会显现出来。所以想象一下,你有一些社区节点,它们实际上是加密的,并且在每个网站的每个页面上都可以找到。现在,如果你超越这一点,所有这些分发平台都将会受到干扰,因为这些模型现在几乎将阅读所有这些内容并为你提供个性化摘要和个性化输出。
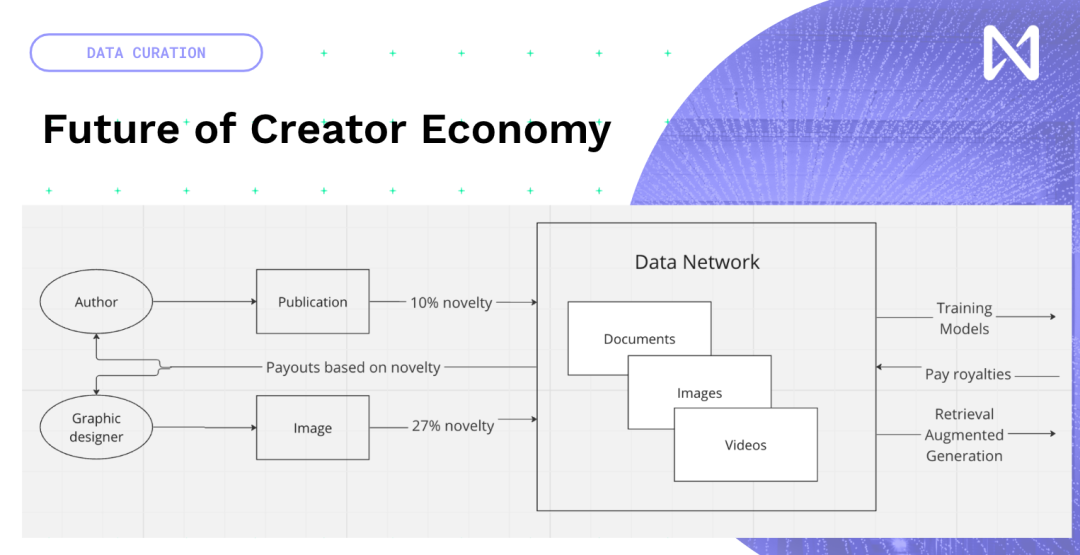
因此,我们实际上有机会创造新的创造性内容,而不是试图重新发明,让我们在现有内容上加上区块链和NFTs。围绕模型训练和推理时间的新创作者经济,人们创造的数据,无论是新的出版物、照片、YouTube、还是你创作的音乐,都将进入一个基于其对模型训练的贡献程度的网络。因此,根据这一点,根据内容可以在全球范围内获得一些报酬。因此,我们从现在由广告网络推动的吸引眼球的经济模式过渡到了真正带来创新和有趣信息的经济模式。
我想提一件重要的事情,那就是大量的不确定性来自浮点运算。所有这些模型都涉及大量的浮点运算和乘法。这些都是不确定性的操作。
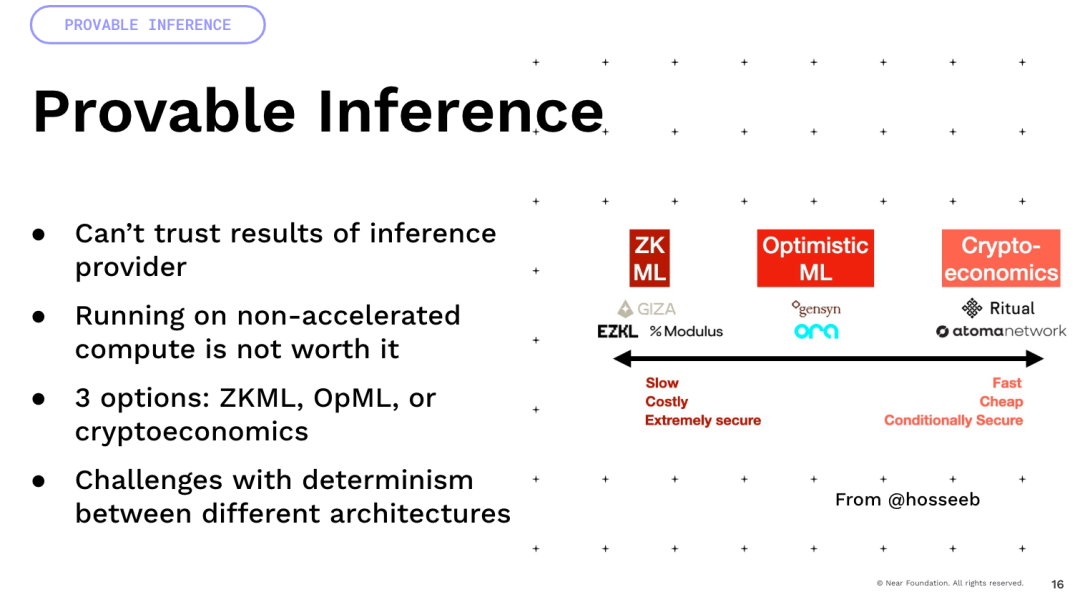
现在,如果你将它们在不同架构的GPU上进行乘法运算。所以你拿一个A100和一个H100,结果会有所不同。因此,很多依赖确定性的方法,比如加密经济和乐观主义,实际上会遇到很多困难,并且需要很多创新才能实现这一点。最后,有一个有趣的想法,我们一直在构建可编程货币和可编程资产,但是如果你能想象一下,你给它们添加这种智能,你就可以有智能资产,它们现在不是由代码定义的,而是由自然语言与世界互动的能力来定义,对吧?这就是我们可以有很多有趣的收益优化、DeFi,我们可以在世界内部进行交易策略。

现在的挑战在于所有当前事件都不具备强大的Robust行为。它们并没有被训练成具有对抗性的强大性,因为训练的目的是预测下一个token。因此,说服一个模型给你所有的钱会更容易。在继续之前,实际上解决这个问题非常重要。所以我就给你留下这个想法,我们处在一个十字路口上,对吧?有一个封闭的人工智能生态系统,它有极端的激励和飞轮,因为当他们推出一个产品时,他们会产生大量的收入,然后把这些收入投入到建设产品中。但是,该产品天生就是为了最大化公司的收入,从而最大化从用户那里提取的价值。或者我们有这种开放、用户拥有的方法,用户掌控着局面。

这些模型实际上对你有利的,试图最大化你的利益。它们为你提供了一种方式,真正保护你免受在互联网上的许多危险。所以这就是为什么我们需要AI x Crypto更多的开发和应用。谢谢大家。
本内容旨在传递行业动态,不构成投资建议或承诺。
本文来源:IOSG Ventures



24H热门新闻
暂无内容