



万字解析Al+ Web3:新型生产关系赋能人工智能时代
Frank-Zhang.eth热度: 18508
本文介绍了人工智能和Web3的结合,认为人工智能是新型生产力,Web3将成为新时代的生产关系,避免AI垄断。作者是一名Web3投资者和AI研究者,介绍了人工智能的基础概念和新兴方向,以及AI在Web3上的应用。近十年,人工智能取得了突破性进展,主要得益于算力、数据和模型的发展。大语言模型是一种重要的人工智能模型,可以通过预训练和Fine tune训练来提升专业知识。Web3项目可分为基础设施、中间件和应用层,其中基础设施包括数据、算力和算法的去中心化。杀手级应用可能会成为顶级大项目,如ChatGPT在大模型领域的成功。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文作者:Frank-Zhang.eth
原文来源:twitter
注:本文来自@dvzhangtz 推特,火星财经整理如下:
笔者认为,人工智能本身代表新型生产力,是人类的发展方向;Web3与A的结合将使得Web3成为新时代的新型生产关系,成为组织未来人类社会,避免 AI 巨头形成绝对垄断的救赎之路。
作为一名长期奋战在 Web3 一级投资一线,以及曾经的 AI研究者,写一篇赛道 mapping,弟认为自己责无旁贷。

一、本文目标
为了更充分地理解 A,我们需要了解:
1.A的一些基础概念如:什么是机器学习,为何需要大语言模型。
2.AI开发的步骡如:数据获取,模型预训练,模型fine tune,模型使用;都是在做什么。
3.一些新兴方向如:外置知识库,联邦学习,ZKML,FHEML,promptlearning,能力神经元。
4.整个 A链条上对应 Web3 都有哪些项目。
5.对于整个 AI链条 什么环节具有比较大的价值 或者说容易出大项目。
在描述这些概念的时候,笔者会尽量不使用公式、定义,而是用打比方的方式进行描述。
本文尽可能覆盖了较多的新名词,笔者希望在读者心里留下个印象,如果未来遇到,可以回来查其处于知识结构中的什么位置。
二、基础概念
Part 1
当今咱们熟悉的 web3+ai项目,他们的技术是属于人工智能 中的 机器学习 中的 神经网络这一思路。
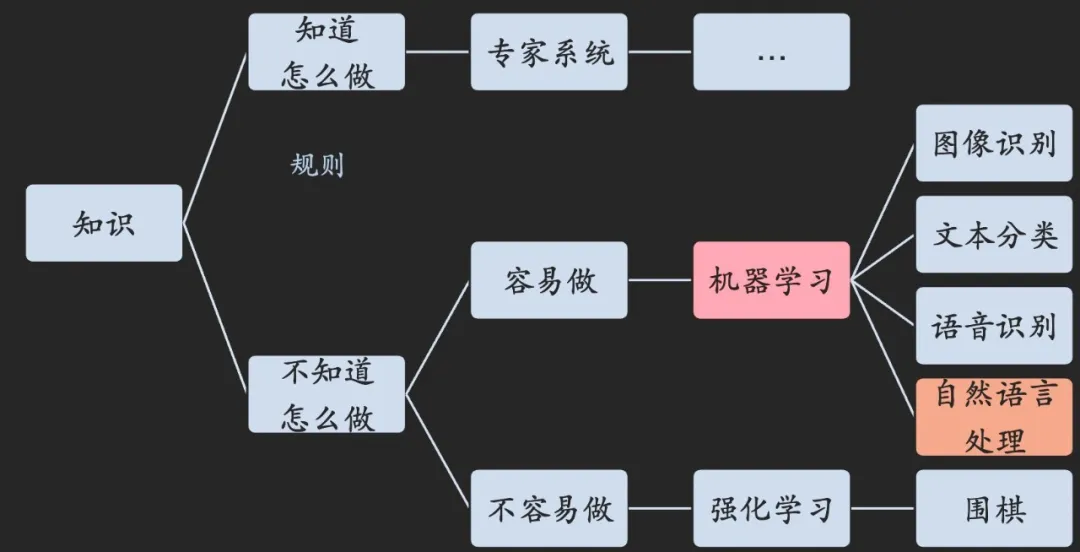
下面的这段主要界定清楚一些基础概念:人工智能、机器学习、神经网络、训练、损失函数、梯度下降、强化学习、专家系统。
Part 2
人工智能
定义:人工智能是研究开发能够模拟、延申、扩展人类智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能的研究目的是促使智能机器,会:听,看,说,思考,学习,行动
我的定义:机器给的结果和人给的结果一样,真假难辨(图灵测试)
Part 3
专家系统
如果一件事 有明确的步骤、需要用到的知识:专家系统

Part 4
如果一件事 难以描述怎么做到:
1.有标注数据:机器学习,比如分析文本中的情感
例子:需要的训练数据
配钥匙师傅问我:”你配吗”neutral
隔壁很壮的小王问我:”你配吗“-negative
2.几乎无标注数据:强化学习,比如 下棋

Part 5
神经网络是怎么教会机器一个知识的
机器学习现在涉及的知识和范围很广,我们这里仅仅讨论机器学习中最经典的套路,神经网络。
神经网络是怎么教会机器一个知识的呢?我们可以类比为我们:
如果想教会小狗如何在垫子上小便(经典案例,无不良指向)——(如果想教会机器一个知识)
方法1:如果狗狗在垫子小便则奖励块肉,如果不在则打屁股
方法2:如果狗狗在垫子小便则奖励块肉,如果不在则打屁股;而且距离垫子越远,打得越狠(计算损失函数)
方法3:狗狗每走一步,就进行一次判定:
如果是朝向垫子走,则奖励块肉,如果不是朝向垫子走,则打屁股
(每进行一次训练,计算一次损失函数)
方法4: 狗狗每走一步,就进行一次判定
如果是朝向垫子走,则奖励块肉,如果不是朝向垫
子走,则打屁股;
并且给狗狗在指向垫子的方向摆一块肉,吸引狗狗往垫子走
(每进行一次训练,计算一次损失函数,之后向着能最好降低损失函数的方向,进行梯度下降)

Part 6
为什么最近十年神经网络突飞猛进?
因为最近十年人类在 算力、数据、算法上突飞猛进。
算力:神经网络其实上个世纪就被提出了,但是当时的硬件运行神经网络,耗时过长。但随着本世纪芯片技术的发展,计算机芯片运算能力以18个月翻一倍的速度发展。甚至还出现了 GPU这种擅长并行运算的芯片,这使得神经网络在运算时间上变得“可接受”。
数据:社交媒体,互联网上沉淀了大量训练数据大厂们也有相关的自动化需求。
模型:在有算力,有数据的情况下,研究者研究出了一系列更高效,更准确的模型。
“算力”、“数据”、“模型”也被成为 人工智能 三要素。
Part 7
大语言模型(LLM)为什么其很重要
为什么要关注:今天我们欢聚于此,是因为大家对Al+ web3 很好奇;而A 火是因为 ChatGPT;ChatGPT 就属于 大语言模型。
为什么需要大语言模型:我们上面说了,机器学是需要训练数据的,但是大规模数据标注成本太高;大语言模型以一种巧妙的方式解决了这个问题。

Part8
Bert——第一个 大语言模型
我们没有训练数据怎么办?一句人话本身就是一段标注。我们可以使用完型填空法创造数据。
我们可以在一段话之中挖空,将一些词挖出来,让 transformer架构(不重要)的模型预测这些地方应该填写什么词(让狗狗找垫子);
如果模型预测错了,测一些损失函数,梯度下降(狗狗如果是朝向垫子走,则奖励块肉,如果不是朝向垫子走,则打屁股,并且给狗狗在指向垫子的方向摆一块肉,吸引狗狗往垫子走)
这样所有互联网上的文段,都能成为训练数据。这样的一个训练过程也就叫做“预训练”,所以大语言模型也称为预训练模型。这样的模型可以给他一句话,让他去一个词一个词的猜,下面应该说什么词。这个体验和我们现在使用 chatgpt 是一样的。
我对预训练的理解:预训练让机器从语料中学到了人类通用的知识,并培养了“语感”。

Part 9
大语言模型的后续发展
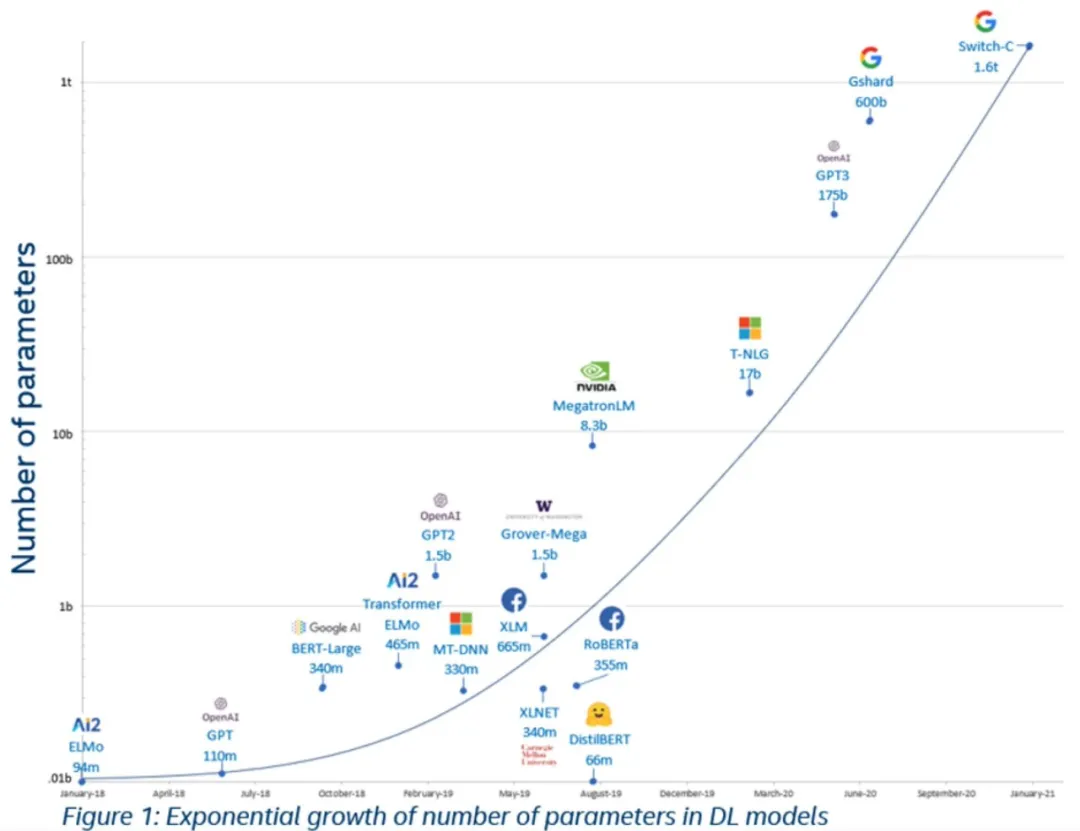
在 Bert 提出之后,大家发现这玩意真好用!
只需要将模型变得更大,训练数据变得更多,效果就能越来越好。这不是无脑冲就好了。
训练数据暴涨:Bert 使用的是全部 wikipedia、书籍数据训练的,后来的训练数据扩展到全网的英文数据,后扩展到全网全语言
模型参数量飞速上涨
三、AI开发的步骤
Part 1
预训练数据获取
(本步骤一般仅大厂/大研究所会做)预训练一般会需要巨量数据,需要对全网各类网页进行爬取,积累以 TB为单位的数据,然后进行预处理
模型预训练(本步骤一般仅大厂/大研究所会做)在完成数据收集之后,需要调集大量算力,数百张 A100/TPU 级别算力进行预训练
Part 2
模型二次预训练
(option)预训练让机器从语料中学到了人类通用的知识,并培养了“语感”,但如果我们想要让模型有某个领域的更多知识,可以拿这个领域的语料,灌入模型进行二次预训练。
比如美团,作为一个餐饮外卖平台,需要的大模型就应该了解更多的餐饮外卖知识。所以美团拿美团点评业务语料进行二次预训练,开发出MT-Bert.这样得到的模型在相关场景上效果更好。
我对二次预训练的理解:二次预训练让模型成为某个场景下的专家
Part 3
模型 fine tune 训练
(option)预训练模型如果想要成为某个任务上的专家,比如情感分类的专家,主题抽取的专家,说读理解的专家;可以使用该任务上的数据,对模型进行 fine tune。
但这里就需要标注数据,比如如果需要情感分类数据,就需要类似下面的数据:
配钥匙师傅问我:”你配吗”neutral
隔壁很壮的小王问我:”你配吗“negative
我对二次预训练的理解:Fine tune让模型成为某个任务下的专家
需要注意,模型的训练都需要显卡间大量传输数据。当前咱们 Al+ web3 有一大类项目是 分布式算力--世界各地的人将自己的闲置机器贡献出来做某些事情。但想用这种算力做完整的分布式预训练,是非常非常难的;想做做分布式 Fine tune 训练,也需要很巧妙的设计。因为显卡间传输信息的时间将高于计算的时间。
Part 4
需要注意,模型的训练都需要显卡间大量传输数据。当前咱们 Al+web3 有一大类项目是 分布式算力——世界各地的人将自己的闲置机器贡献出来做力某些事情。但想用这种算力做完整的分布式预训练,是非常非常难的;想做做分布式 Fine tune 训练,也需要很巧妙的设计。因为显卡间传输信息的时间将高于计算的时间。
Part 5
模型使用
模型使用,也称为 模型推理(inference)。这指的是模型在完成训练之后进行一次使用的过程。
相比训练,模型推理并不需要显卡大量传输数据,所以 分布式 推理 是个相对容易的事情。
四、大模型的最新应用
Part 1
外置知识库
出现原因:我们希望模型知道一些少量我们领域的知识,但又不希望花大成本再训练模型
方法:将大量 pdf 数据打包到 向量数据库 之中,将其作为背景信息作为输入
案例:百度云一朵、Myshell
Promptlearning
出现原因:我们感觉外置知识库还无法满足 我们对模型的定制化需求,但又不想负担整个模型的调参训练
方法:不对模型进行训练,仅使用训练数据,去学应该写一个什么样的 Prompt
案例:广泛应用于当今
Part 2
联邦学习(Federated Learning,FL)
出现原因:在训练模型的使用,我们需要提供自己的数据,这会泄露我们隐私,这对于一些金融、医疗机构是不可接受的
方法:每一家机构都在本地使用数据训练模型,然后将模型集中到一个地方进行模型融合
案例:Flock
FHEML
出现原因:联邦学习需要每个参与方本地都训练个模型,但这对每个参与方门槛太高了
方法:使用 FHE的手段进行全同态加密,是的模型可以用加密后的数据直接训练
缺点:极慢,极贵
案例:ZAMA,Privasea
Part 3
ZKML
出现原因:我们在使用别人提供的模型服务的时候,希望确认其真的在按我们的要求,提供模型服务,而不是使用一个小模型再瞎搞
方法:让其用ZK的手段生成个证明,证明其确实在做他号称他做了的运算
缺点:很慢,很贵
案例:Modulus
能力神经元(skillneuron)
出现原因:当今模型就像是一个黑箱,我们喂了他很多训练数据,但他到底学到了什么我们不知道;我们希望能有某种方式,让模型在某个特定方向优化,比如具有更强的情感感知能力,具有更高的道德水平
方法:模型就像大脑,有些区域的神经元管理情感,有些区域管理道德,找出这些节点,我们就可以针对性的优化
案例:未来方向
五、A链条上对应 Web3 项目分类方式
Part 1
笔者会分为三大类:
Infra:去中心化A的基础设施
中间件:让Infra 可以更好服务应用层
应用层:一些直接面向 C端/B端的应用
Part 2
Infra 层:AI的基础设施永远是三大类:数据算力算法(模型)
去中心化算法(模型):
@TheBittensorHub 研报:x.com/dvzhangtz/stat..@flock_ io
去中心化算力:
通用算力: @akashnet_, @ionet
专用算力:@rendernetwork(渲染)、@gensynai(AI),@heuris_ai(Al)@exa_bits (A)(AD,
去中心化数据:
数据标注:@PublciAl_,QuestLab
存储:IPFS,FIL
Oracle: Chainlink
索引:The Graph
Part 3
中间件:如何让Infra 可以更好服务应用层
隐私: @zama fhe, @Privasea_ai
验证: EZKL, @ModulusLabs , @gizatechxyz
应用层:应用其实其实很难全部分类,只能列举其中最具代表性的几项
数据分析
@_kaitoai,@DuneAnalytics ,Adot
Agent
Market: @myshell_ai
Web3知识聊天机器人:@qnaweb3
帮人做操作:@autonolas
六、什么样的地方更容易出大项目?
首先,与其他领域类似,Infra 容易出大项目,尤其是去中心化模型、去中心化算力,笔者感觉其边际成本较低。
然后,在与 @owenliang60 哥的启发下,笔者感到应用层 如果能出现一个杀手级应用,其也会成为顶级大项目。
回顾大模型的历史,是 ChatGPT这个杀手级应用将其推向封口浪尖,其不是什么技术上的大迭代,而是针对 Chat 这个任务的优化。也许在A+Web3 领域未来也会出现像 Stepn/Friendtech 这样的现象级应用,我们拭目以待
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。
本文来源:Frank-Zhang.eth



24H热门新闻
暂无内容