



AI数据革命:探索加密货币与人工智能的交叉创新
IOSG Ventures热度: 14657
本文讨论了人工智能领域的数据问题,指出数据是人工智能的关键,但目前存在收集不透明、来源不可追溯、所有者未得到合理补偿等问题。加密货币技术可以通过代币化激励、数据货币化、隐私保护等手段解决这些问题。人工智能和区块链技术的结合将推动人工智能的发展,数据质量将变得尤为关键。未来,AI与加密技术的结合将带来更多的合作与整合,提升数据价值,实现无信任性和智能。随着Web 3.0和区块链技术的发展,数据完整性、质量和隐私问题得到了解决。作为早期投资者,IOSG Ventures致力于推动加密行业的发展和创新,投资了多个领先项目。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文来源: IOSG Ventures
TL;DR
数据对于人工智能的作用,就像汽油对于汽车一样关键。在人工智能的时代,数据蕴含着巨大的价值,但目前这些价值还没有得到透明和负责任的利用,因为许多大型科技公司常常未经用户同意就擅自获取数据,从而截留了大量的潜在价值。
- 人工智能数据目前面临的问题包括数据收集不透明、来源不可追溯、数据所有者未得到合理补偿、隐私风险、收集困难、高质量数据稀缺、特定数据缺失和实时数据供应不足。
- Web 3和加密货币技术通过代币化激励、数据货币化、隐私保护等手段,致力于增强AI数据的安全性、模型的可解释性和数据质量的监管,确保数据的经济利益归属于真实所有者,并保障数据使用符合道德标准。
- 在人工智能与加密货币的交叉领域,企业通过垂直扩张和建立战略联盟来加强合作,这在行业发展的初期阶段尤为常见。这些合作对于推动加密人工智能解决方案的广泛应用至关重要。
- 未来,人工智能和区块链技术将趋向于“模块化”发展。利用区块链技术驱动的数据解决方案,将成为推动人工通用智能(AGI)向更高级别发展的钥匙。
 1. 数据:AI的“燃料”
1. 数据:AI的“燃料”
上周,OpenAI的GPT-4o和谷歌的Project Astra的推出,再次为人工智能的热潮添了一把火。科幻电影《她》中所描绘的女声人工智能助手,几乎已经成为现实!
近年来的人工智能热潮已经成为推动多个行业创新的重要引擎。区块链技术也不甘落后,这一点从今年迄今为止AI代币的强劲表现中可见一斑,其98%的增长率在所有代币类别中排名第四。
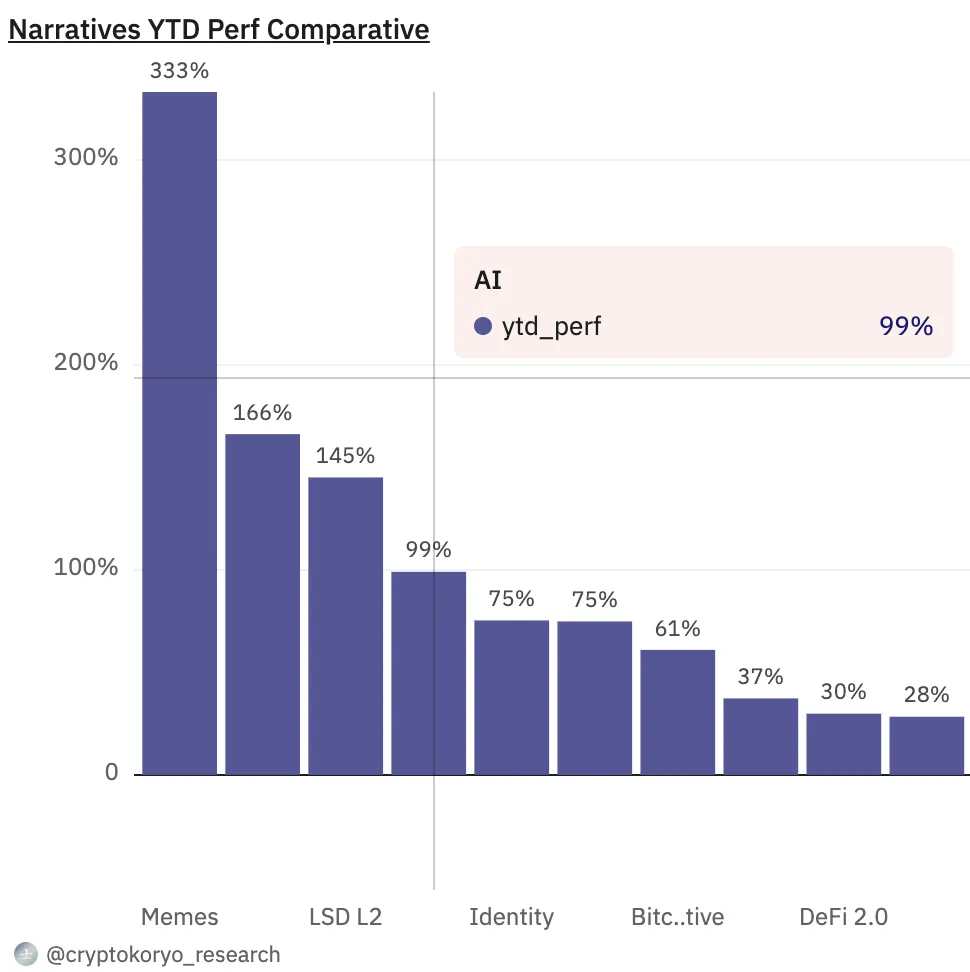
最近人工智能领域的进步,主要得益于在各种大型语言模型(LLMs)的开发上取得的进展。
大型语言模型(LLMs)的性能主要由三个关键因素决定:
- 模型
- 数据
- 计算能力
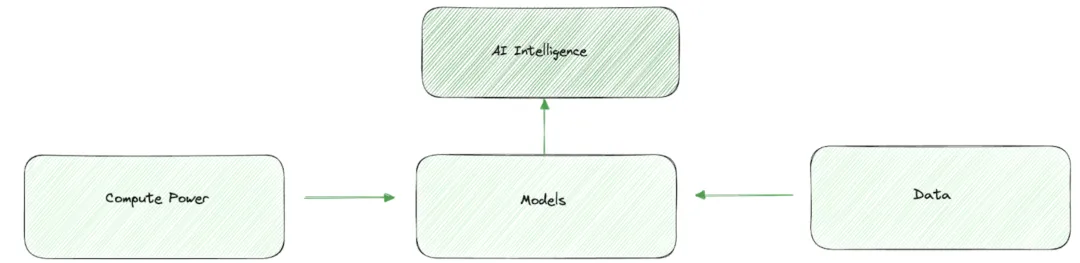 Source:IOSG Ventures
Source:IOSG Ventures
人工智能的核心是支撑它的底层模型。这些模型就像汽车一样,有众多不同的品牌和类型(比如开源或闭源模型),每种模型都有其独特的优势:像是汽车,有的速度快,有的驾驶体验更佳。总的来说,他们都极大地方便了我们的日常生活。
 Source:Michael Dempsey
Source:Michael Dempsey
正如人工智能模型的性能决定了AI的智能水平,计算的强度和数据的质量是推动AI模型发展的关键动力。继续用汽车来打比方,计算能力就像是汽车的引擎,而数据则是汽车发动所需的燃料。它们一起构成了实现人工智能智能所必需的基本要素,并且在许多AI公司的成本结构中扮演着两个重要的成本因素。据LXT的报告显示,人工智能预算中有59%被用于数据。因此,大量的的数据储备实际上成为了众多AI公司的护城河。
如果说计算能力是大型语言模型(LLMs)的引擎,那么数据就是这些模型的燃料。
在一个计算资源无限充裕的环境下,如果能将目前最大规模的数据集扩大100倍(从1万亿个token增加到100万亿个token),那么模型的预测误差将会大幅降低。
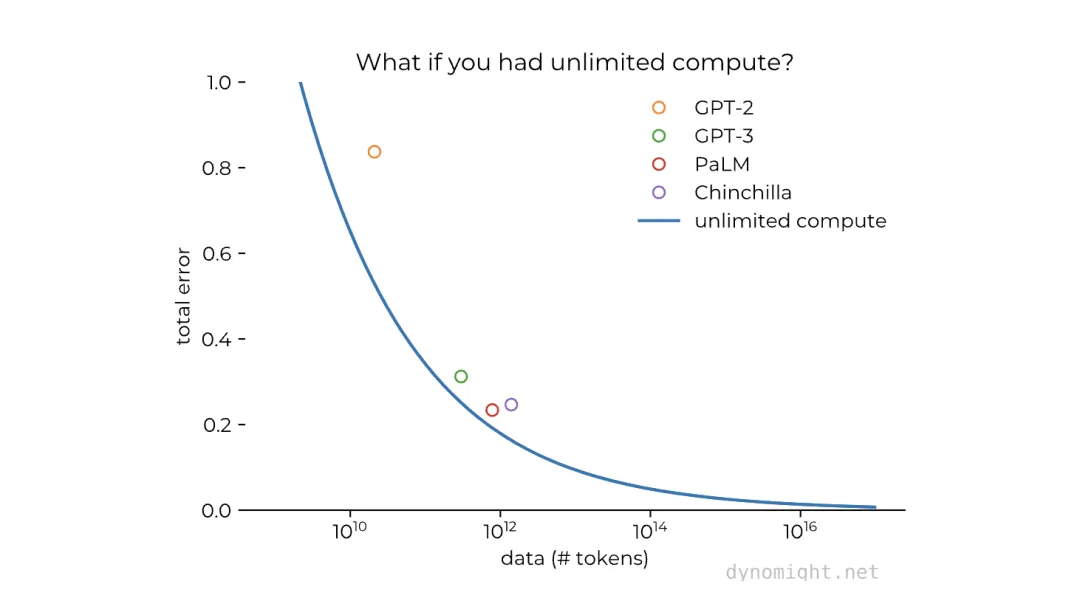 Source:dynomight.net
Source:dynomight.net
当工智能预测的准确性随着训练数据的增多而提高,人们也越来越重视数据的质量而非数量。2022年的一项分析表明,未来几年内,新的高质量文本数据可能会逐渐减少。因此,数据质量将变得尤其关键。
"阻碍人工智能普及的主要因素是什么?两个问题:数据和人才的短缺" — Andrew Ng,斯坦福大学人工智能实验室前主任。

2. 人工智能的数据瓶颈
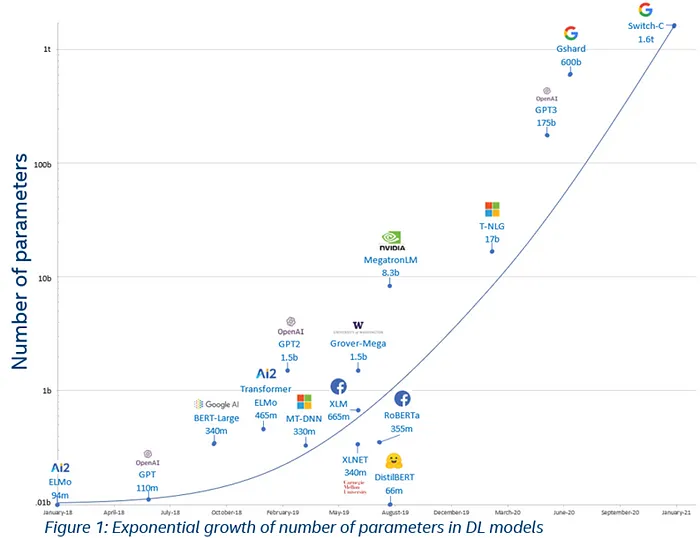 Source: <Towards Data Science> Gadi Singer
Source: <Towards Data Science> Gadi Singer
为了构建出人们梦寐以求的强大大型语言模型(LLMs),我们必须在预训练、训练、微调和推理的各个阶段都有数据输入。
目前,大型语言模型(LLMs)是通过使用公开可获取的数据来训练的,这些数据被转换成Token (Token是对输入文本进行分割和编码时的最小单位)。这些数据涵盖了所有已发布书籍的相当大部分以及整个互联网的内容,因此的得名"大型语言模型"。随着每天都有新的公共信息产生,这也导致了最新模型中参数数量的相应增加。
具有讽刺意味的是,许多来自公共网络数据的训练语料库被那些大型AI公司所控制,这些公司在数据收集方面存在很多秘密。
像GPT-3这样的大型语言模型对其公共数据来源和收集过程的描述非常模糊。在GPT-3的论文中,它简要地将Books1和Books2(它的两个主要来源)描述为“两个基于互联网的书籍语料库”。
因此,无论开源还是闭源模型,我们都没有办法验证AI模型训练中使用的确切数据来源。AI模型中的数据出处完全是一个黑箱。这意味着用户无法得知自己的个人信息是否被收集,以及数据是否被保护。如果AI模型出现问题,数据出处不明确也导致很难确定问题数据的责任归属,用户也难以理解模型决策的依据。
这就是为什么AI被大型科技巨头所主导,因为他们控制着用户生成的数据。谷歌可以看到个人的搜索查询,Meta可以看到他们分享的内容,亚马逊可以看到他们的购买行为。这赋予了他们对各自市场内用户活动的全知视角。
一些科技巨头甚至将用户生成的数据视为自己的私有财产,并以高额利润出售,而数据的创作者却一无所获。最近,Reddit与谷歌达成了一笔6000万美元的训练数据交易。原始数据所有者没有办法阻止这一点,也无法防止他们的私人信息泄露。您可能还在想,网络数据是公共的,我是否可以自己用爬虫爬取所有内容。从理论上讲是可行的,这个世界上充斥着各种数据。根据市场研究公司IDC报告显示,2018年全球产生了总共33泽字节的数据,足以填满7万亿张DVD。
不幸的是,为了防止DDOS攻击,网站通常会对利用AWS等数据中心进行的大规模网络爬取活动实施限速,或设置蜜罐等防御性措施。即便我们设法避开了网站的安全防护措施并成功抓取了数据,数据标注这一关仍然是无法回避的。与网络抓取相比,数据标注是一项更加费人力和需要手动操作的过程。
尽管有Common Crawl等非营利性开放存储库以及Scale AI等Web 2标注解决方案可用,但其数据和数据标签的质量并不总能保证,这往往会导致具有偏见的模型,这些模型会复制刻板印象并歪曲事实。
如果现实世界的数据获取太困难,还有一种选择是自己编造一些数据。为了对其Go商店的视觉识别模型进行微调,亚马逊使用图形软件来创建虚拟购物者,这些人造人被用来模拟一些消费者在无售货员购物时可能出现的潜在极端情况。这些极端情况在Go商店上线之前并没有真实出现过,但是可能存在于Go商店实际上线后。然而,使用合成数据训练AI有优点也有缺点。合成数据的主要优点就是可扩展性的场景,例如Amazon Go商店的无人商店购物场景模拟。另外就是合成数据可以经过净化消除任何潜在的个人信息或无意的偏见。当然显而易见的缺点就是,合成数据可能缺乏真实世界的复杂性和细微差别,导致模型无法在真实场景中表现良好。
数据的时效性也是一个需要考量的因素。很多时候,收集到的数据可能是一次性的,并且不能反映不断变化的世界。这对人工智能模型来说是一个挑战,因为它们容易受到“漂移”的影响,也就是说,随着世界运作方式的变化,它们的精确度会逐渐降低。例如,在COVID-19疫情期间,一些面部识别模型,习惯于识别未遮挡的面孔,在人们普遍佩戴口罩的疫情情况下则遇到了识别困难。
总结一下人工智能数据的瓶颈问题:
- 数据收集缺乏透明度
- AI模型中数据来源无法追溯
- 数据所有者没有得到公平的补偿
- 用户数据隐私面临风险
- 数据虽多但收集困难
- 高质量数据非常稀缺
- 特定所需的数据可能没有
- 缺乏实时数据供应
幸运的是,因为区块链,我们有了好的解决方法。

3. 区块链赋能AI数据
显然,人工智能在解释数据和推理数据方面非常出色,一旦你拥有了数据,它就能发挥作用。在区块链技术中,代币激励机制在大规模的众筹数据收集和资源共享方面发挥着卓越的功效,而区块链内的密码学技术在确保数据安全方面展现出了极高的能力。
因此,为了解决人工智能数据瓶颈,日前出现了大量的加密数据项目。这些项目涵盖了数据质量保证、数据标注和加密,简化数据收集、维护数据质量、保护数据隐私,并增强人工智能生成结果的可验证性。
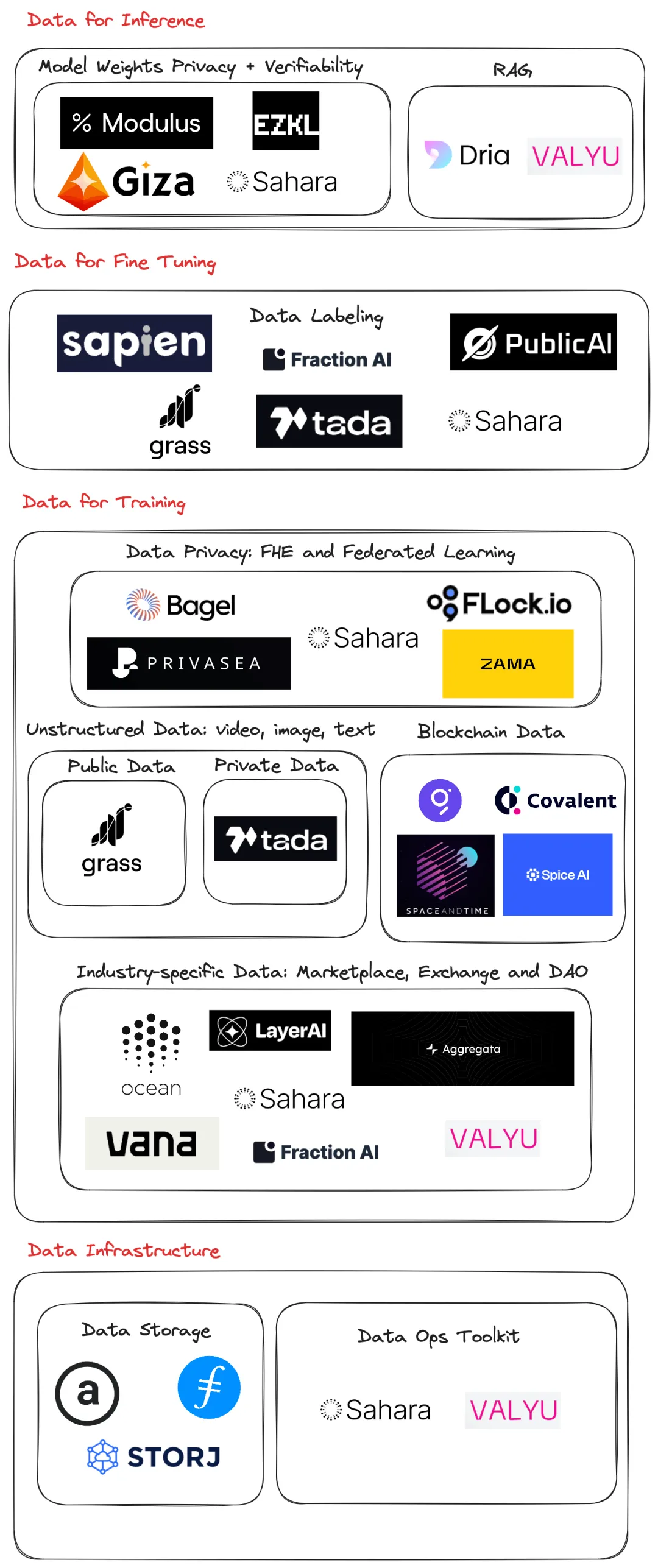 Source: IOSG Ventures
Source: IOSG Ventures
3.1 数据存储
随着数据量的增加,人工智能训练所需的结构化数据需要存储在一个库中,以便随时使用。去中心化的数据存储,如 Arweave、Filecoin 和 STORJ,解决了中心化存储的单点故障问题。今年 2 月,Arweave 推出了 Arweave AO,提供了无需信任的协作计算服务,并没有规模限制。AO 能够存储大量数据,如 AI 模型,并允许多个并行进程在计算单元中运行,通过开放的消息传递与其他单元协作,而无需依赖中心化的内存空间。
3.2 数据基础设施工具包
Sahara 构建了一个 L1 区块链,供个人或企业自由、安全地部署个性化的自主 AI。它提供了所有与数据相关的基础设施,包括社区构建的知识库、训练数据集、数据存储、数据归属和数据工具包(收集、标注、质量保证等)。
3.3 公共网络数据
以 Grass 协议为主要例子。Grass 是一个网络爬虫协议。它包含了一个由 200 万台设备组成的网络,实时抓取互联网数据。它将数据清理成结构化的向量格式,供 AI 公司使用。
要为该网络做出贡献,用户只需安在住宅网络设备上安装一个浏览器扩展,随后该扩展就会利用用户的互联网带宽从网站中爬取数据。目前,用户会获得 Grass 点数收益,未来则会以代币形式捕获收益,从而从他们的数据贡献中获得实际价值。
在Grass网络上,用户仅通过扩展程序交换他们的无限局域宽带,成为Grass网络中的分布式节点,从而实现大规模的公共网络数据抓取。由于是分布式节点,并且每个节点使用住宅宽带网络(Residential Network)而不是集中的数据中心网络,来发送爬取数据的网站访问请求,使得用户不容易遭受到网站限速和蜜罐等防御措施。
此外,Grass 节点不会抓取登录墙之后的数据,从而避免与访问私人数据相关的法律问题。所有收集的数据都来自公共互联网,这增强了过程的合法性和隐私性。对网络数据的持续抓取还意味着数据可以实时提供,防止人工智能模型中的“漂移”现象。
3.4 行业特定数据
仅仅抓取公共互联网数据通常是不够的。为了进一步训练能够做出良好预测的 LLM 模型,我们需要在训练阶段为它们提供更多特定领域的数据。这些上下文数据通常以私人数据和/或区块链数据的形式出现。
每天都会有大量私人数据产生。对于大型中心化公司来说,利用这些数据并不容易。例如,谷歌和 Meta 因违反 GDPR 规则而没有妥善处理私人数据而被处以巨额罚款。然而,仅仅在公共数据上训练会限制 LLM 模型的性能。
幸运的是,代币激励促进了高质量训练数据获取的民主化。
一个典型的例子是 Ocean 协议。它旨在促进企业和个人之间的数据交换和货币化,同时确保数据不会离开存储数据的提供者。所有提供的数据都被代币化为数据代币(datatokens),并且数据代币的提供者会获得 OCEAN 代币作为奖励.
3.5 数据清理和标注
这种代币激励的众包逻辑同样适用于数据清洗和标注。在 Web 2 时代,数据清洗和标注是极其劳动力密集的工作。
“Cognilytica 表示,在典型的人工智能项目中,各种数据处理工作占用了大约 80% 的时间。训练机器学习系统需要大量精心标注的样本,而这些标注通常需要人工完成。”
在 Web 3 时代,我们可以通过提供 X to earn 的 Gamfi 体验,轻松将这些任务外包给公众。Sapien 和 PublicAI 等项目正在积极开展这方面的工作。尤其是 Grass 即将推出自己的数据标注服务,竞争会愈加激烈。
3.6 区块链数据
为了用区块链特定数据丰富人工智能模型,像 Covalent 和 Space and Time 这样的索引器和去中心化数据仓库解决方案,通过统一的 API 和 SDK 为机器学习开发者提供了高质量的区块链数据。
3.7 数据隐私和可验证性
模型训练和推理过程中的一个主要担忧是如何确保所涉及的数据保持私密性。这种担忧包括了数据输入、权重数据的传输和数据输出的问题。
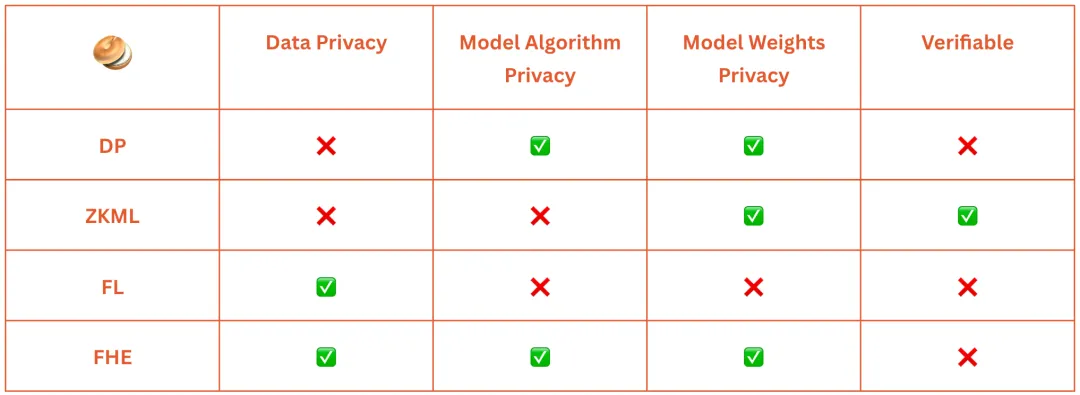
几种新的密码学解决方案已经可以应对这一挑战,Bagel 提供了一个很好的比较表:
Source: Bagel Blog
联邦学习(Federated Learning,FL)和全同态加密(Fully Homomorphic Encryption,FHE)都是在训练过程中保护数据隐私的良好解决方案。
Flock.io 是一个著名的项目,致力于联邦学习(FL)。它确保了隐私,因为本地服务器上的本地数据从未被共享,所有计算都在本地完成。因此,它是一个分布式机器学习框架。尽管联邦学习确保了训练数据的隐私性,但最近的研究表明,联邦学习可能存在数据泄露的风险,并且全球模型并不是私有的,因为它在每个本地服务器之间共享。因此,每一步聚合的权重和梯度也会被共享。
全同态加密(FHE)允许对加密后的数据进行计算。由于所有内容都是加密的,训练数据和模型权重也得到了隐私保护。因此,FHE 在医疗保健或金融等用例中变得非常宝贵,因为在进行计算时数据仍能确保安全。著名的 FHE 项目包括 Zama、Bagel、Fhenix、Inco、Sunscreen和 Privasea等。FHE 的缺点是速度和可验证性,因为用户必须信任加密后的数据是正确的。
ZKML 的最大优势在于它能够在保持模型权重不公开的情况下验证计算输出,这使得它在模型推理方面特别有用。它生成零知识证明,保证训练或推理的正确执行,并且对数据所有者没有任何信任假设。致力于 ZKML 的项目包括 Modulus、Giza 和 EZKL。
值得注意的是,虽然联邦学习(FL)和全同态加密(FHE)更常用于训练目的,而零知识机器学习(ZKML)通常用于推理,但它们的使用实际上是灵活的,可以用于训练或推理中的任何一种技术。
3.8 RAG(检索增强式生成)
在 AI 推理阶段,一个危险的陷阱是“模型幻觉”。它指的是大语言模型(LLM)生成的文本虽然连贯,但文本包含错误或编造的信息,与事实或用户的需求不符。
这种现象通常是由于模型在训练或微调过程中没有接触到外部知识数据造成的。一个通常的解决方案是提供上下文数据重新微调 LLM。然而,这个过程可能非常耗时,并且通常需要重新训练模型。因此,一种更简单的解决方案——RAG(检索增强生成)被发明了出来。
RAG(检索增强生成)可以有效帮助开发者,因为他们不需要不断地用新数据训练他们的模型,从而减少计算成本。RAG 允许任何 AI 模型(例如 LLM)从外部知识源检索相关信息(即使这些信息不在其训练数据中),并生成更加准确和符合上下文的答案,从而减少错误信息的产生
外部知识数据以向量嵌入的形式存储在向量数据库中。RAG 的一个主要优点是确保用户可以访问模型数据的来源,并且可以验证生成结果的准确性。
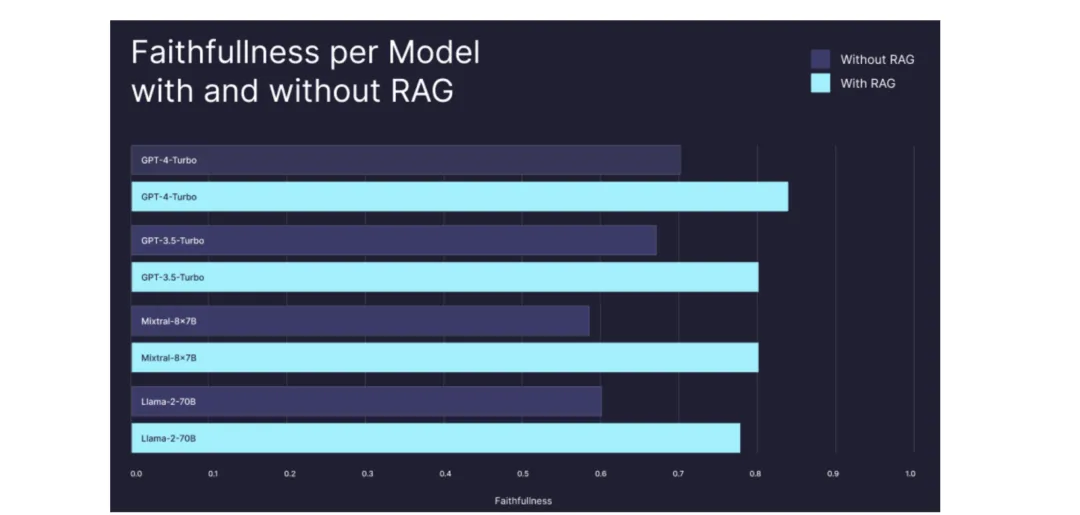
研究表明,使用 RAG 的 LLM 模型显著优于不使用 RAG 的同一模型。
一个创新的 Web 3 解决方案是 Dria,它在 RAG 方面有着重要的应用。Dria 是一个运行在以太坊二层(L2)的解决方案,作为向量数据库(存储在 Arweave 上),并且为外部知识数据集提供了一个代币激励的市场。
在观察 AI 与加密数据堆栈后,可以明显看出,Web 3 项目主要通过以下几种方式来提升数据在 AI 中的价值:
- 数据收集
- 没有Web 3: 无法大规模收集数据,只能依赖第三方 API,支付高昂费用,或仅使用非盈利数据。
- 有Web 3: 通过代币激励的数据众包,实现大规模、全球可访问的收集,满足特定需求。
- 数据货币化
- 没有Web 3: 用户无法从他们的数据贡献中获得价值。
- 有Web 3: 数据被代币化和货币化,使数据的价值回归给数据所有者。
- 隐私增强
- 没有Web 3: 在 AI 模型开发过程中,数据共享可能会引发隐私问题。
- 有Web 3: 数据所有者保持对其私人和个人数据的控制,这些数据在训练、微调或推理过程中不会泄露。
- 可解释AI
- 没有Web 3: 无法管理和验证数据集的来源及模型结果的出处。
- 有Web 3: 帮助了解数据的来源,确保数据合法授权,使用户能够自信地实施模型并验证模型输出。
- 数据质量
- 没有Web 3: 无法保证所收集数据的质量,需要内部数据验证团队或外包第三方,增加巨大运营成本。
- 有Web 3: 通过代币奖励进行数据验证;未遵守数据质量标准的验证者将面临代币罚没处罚。
正如 Vitalik 在他的 AI x Crypto 文章(https://vitalik.eth.limo/general/2024/01/30/cryptoai.html)中所强调的:
- AI 提供高度“集中化”的智能
- 区块链提供高度“去中心化”的无信任性
- AI x Crypto = 无信任性 + 智能,使 AI 从“不会作恶”提升到“不能作恶”

4. 趋势与展望
随着 AI x Crypto 领域竞争的加剧,一个显著的趋势是项目间合作与整合的频率不断增加,以扩大AI x Crypto这个新型市场的份额。一些例子如下:
4.1 产业上下游之间合作:Kaito在Bittensor上运行子网
问题:如何在去中心化环境中提供可靠的搜索服务?
解决方案:Kaito 是一个支持 Web3 的 AI 搜索平台,为 Bittensor 生态系统构建了基础设施层。今年三月,Kaito 发布了名为 OpenKaito 的子网。OpenKaito 是一个去中心化的搜索索引层,具备透明的搜索排名和可扩展性设计。其他子网可以查询特定领域信息,矿工通过提供排名列表获得激励,并利用计算能力增强数据获取、索引、排名和知识图谱。为了防止伪造结果,验证者验证搜索结果的 URL,以确保其与原始来源一致。矿工根据其结果的真实性、相关性、时效性和多样性来获得奖励。
4.2 竞争对手之间的合作:Privasea 和 Zama 的 FHE 算法集成
问题:如何在区块链环境中增强 AI 操作的隐私和安全性?
解决方案:Privasea 和 Zama 通过合作,互相使用对方的技术。在 Zama 的授权下,Privasea 现在可以在其网络中使用 Zama 的 TFHE-rs 库,以增强 AI 操作的隐私和安全性。Privasea 计划基于 Zama 的 Concrete ML 构建基于区块链的私有 AI 应用程序。这些工具将用于人脸识别、医疗图像分析和金融数据处理等任务。
4.3 整个垂直供应链的整合:SingularityNet、Fetch.AI 和 Ocean Protocol 的代币合并
问题:如何通过合并代币提升项目的市场竞争力和协同效应?
解决方案:2024 年 3 月 27 日,SingularityNet、Fetch.AI 和 Ocean Protocol 宣布了一个价值 75 亿美元的代币合并。合并后的 Fetch.AI(FET)代币将变为 ASI 代币,总供应量为 26 亿个。SingularityNet(AGIX)和 Ocean(OCEAN)代币将按约 0.43:1 的比率转换为 ASI 代币。合并后的代币名为 ASI,意为人工超级智能联盟(Artificial Superintelligence Alliance)。ASI 代币计划于 5 月 24 日正式推出。
4.4 AI 与加密技术的未来
有些人认为,AI 竞争格局最终可能会回到一个熟悉的领域,即主要是双寡头市场动态,就像 Android 和 iOS 的情况一样,在各自的类别中分别由一个主导的开源模型和一个主导的闭源模型主宰。
无论关于开源模型和闭源模型的争论如何,我认为 AI 的未来将是一个多模型推理的世界。
多模型推理的一个具体实现发生在 AI 代理层,目前的趋势是AI代理之间的合作。上周,Web 3 的 AI 代理协议 ChaimML 宣布完成了 620 万美元的种子扩展轮融资,推出了其革命性的代理基础层 Theoriq。其核心理念是使 AI 代理能够动态识别并自主与其他代理合作,以应对复杂的用例。Theoriq 的测试网计划在即将到来的夏季推出,预计将在 2024 年的 Consensus 大会上揭示更多细节。
另一个多模型推理的实现是“专家混合”(MoE)架构。它包含一组较小且高度专业化的专家模型,并让这些模型协同工作以解决整体问题。据推测 GPT-4 已经采用了这种方法。这种方法具有高度的适应性,提供了模块化和个性化的配置。
有趣的是,AI 代理和大型语言模型(LLM)的转变类似于区块链领域正在发生的变化,我们正从单体区块链过渡到模块化区块链:
单体区块链 -> 模块化区块链
单一 AI 代理 -> 模块化和可组合的 AI 代理基础层
单一大型语言模型 -> 专家模型混合
在这些专家模型混合(MoE)模型经历的思维链(CoT)过程中,一个专家模型的输出被作为下一个专家模型的输入。
一个模型的错误可以通过另一个模型的优势来减轻,从而导致更可靠的结果。然而,在这种思维链推理过程中,错误也可能被放大。
这构成了一种威胁,毕竟大型语言模型(LLMs)既可以被用于好的方面,也可以被用于不好的方面,就像一把双刃剑。
OpenAI 的 SSL 证书日志显示了 "search.chatgpt.com" 的开发和搜索产品的潜在推出。这表明越来越多的大型语言模型(LLM)项目可能会推出自己的搜索引擎产品,以与 Google 和 Perplexity 等知名平台竞争。
鉴于现在越来越多的人毫无疑问地相信大型语言模型(LLM)所说的一切,恶意行为者有无限动机通过将虚假知识作为训练数据输入 AI 模型,从而开始污染 LLM 的输出。如果恶意行为者在训练数据中仅引入 1% 或 2% 的偏见,模型链条就可能传播这些偏见,并显著毒化结果。
如果恶意行为者通过污染输入给大型语言模型(LLM)的数据来影响人类的决策,尤其是在即将到来的总统选举等重大事件中,这将变得非常可怕。如果个人接触到由 LLM 散布的虚假或捏造的信息,这种操纵甚至可能扭曲投票结果。
在 2016 年和 2020 年的选举中,Twitter 上传播的虚假信息和极化的政治观点的影响及随之而来的批评已经显现出来!
幸运的是,随着我们进入通用人工智能(AGI)的世界,Web 3.0 和区块链技术为保障数据完整性、质量和隐私问题提供了灵丹妙药。
AI 的未来看起来非常光明,我们期待看到加密数据领域的创新将如何继续赋能 AI。
了解更多投资新闻,IOSG Ventures 投资组合动向等请返回点击下一篇

IOSG Ventures 于2017年开始在加密行业投资布局,是Web 3.0主要垂直领域的早期投资者。作为行业研究和社区驱动的原生加密基金,我们长期与优秀的早期项目和协议一道,致力于行业的发展和创新。我们的投资组合包括一系列创造性和高潜力的项目,如 ZKRU (Scroll、StarkWare、Arbitrum、zkSync、Taiko)、Security Auditing (Runtime Verification、Hexens)、MEV (Flashbots、 Blocknative)、DeFi/NFT-Fi (1inch、MetaMask)、FOG (Big Time、Illuvium),Staking/Restaking (EigenLayer、Ether.fi、Renzo、Kiln) 以及 Arweave、Cosmos、Celestia、Scroll、zkSync、Nil Foundation 和 Mina 等行业领先项目。


免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。


