




苹果渴求的端侧AI杀出黑马:首个认知模型诞生,4B打平GPT-5.4
新智元热度: 9421
中国公司明日新程推出行业首个端侧认知模型“新程 Alpha”,仅4B参数即在群体智能任务中达到千亿级大模型(如GPT-5.4)效果,显著降低算力与Token成本,支持MacBook及具身智能设备端侧部署,推动AI从响应式向主动式智能体演进。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
【导读】在刚过去的 WWDC 上,苹果 Siri 借 AI 重生成为关键词,「端侧模型」已成趋势!更早些时候,Andrej Karpathy 呼吁把模型的知识剥离、只保留「认知核心」。一家中国公司称已将这一方向落地——4B 参数,在群体智能任务中打出千亿级大模型的效果。端侧认知模型到底能改变什么?
昨晚,Siri 借谷歌的 1.2 万亿参数 Gemini 重生了。
但另一头,亚马逊却关停了引发巨大争议的内部 AI 排行榜——员工大量使用 AI 工具,算力开销飙升到管理层坐不住的地步。
Token 成本成为 AI 大规模落地最硬的一道门槛。
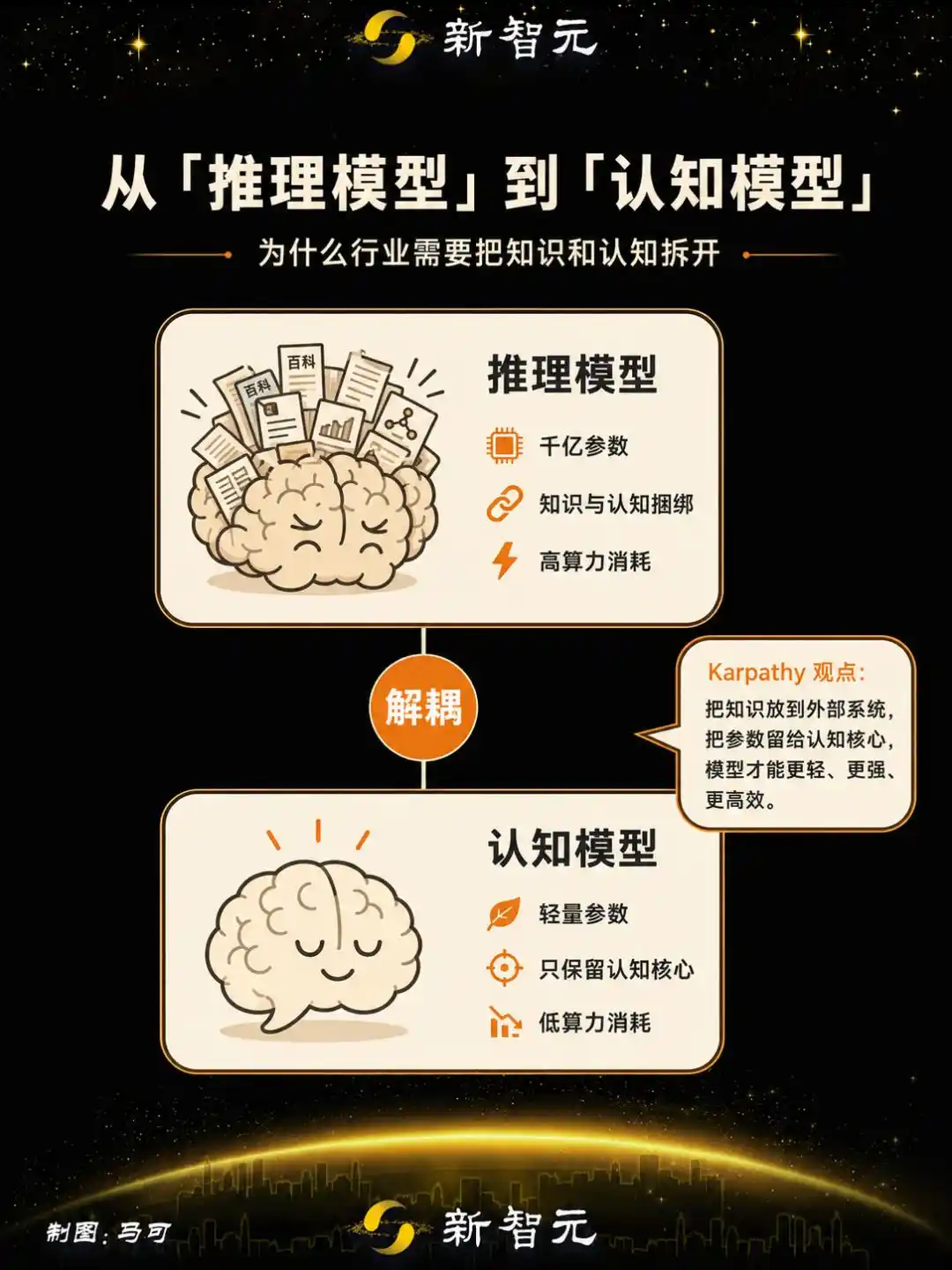
Andrej Karpathy 之前在访谈中给出了一个方向:把模型里的海量知识剥离掉,只保留一个会思考、会规划、知道自己不知道什么的「认知核心」,1B 级别的参数就够。

https://www.youtube.com/watch?v=lXUZvyajciY
这个方向正在被验证。
一个 4B 参数的模型,在群体智能任务中打出了与 GPT-5.4 等千亿级大模型等效的结果,且支持端侧部署。
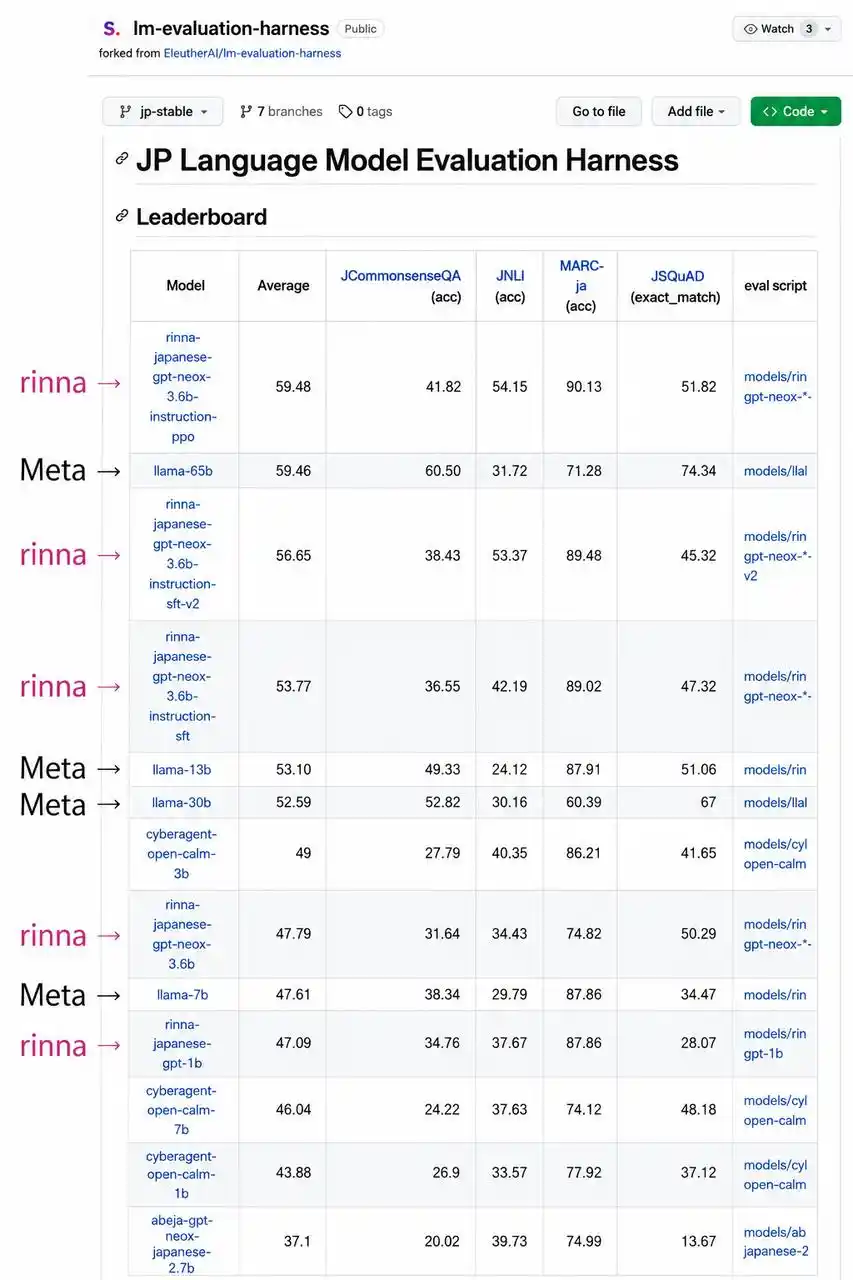
它来自一家创始团队,曾以 3.6B 参数击败 65B Llama、登顶日本 Hugging Face 排行榜。
这次,他们做出了行业首个端侧认知模型。
Karpathy 的预言与算力的账单
算力成本的压力已经从技术议题变成财务议题,亚马逊的案例只是缩影。
亚马逊员工通过内部 AI 工具频繁调用大模型推理能力,推高了整体算力支出,管理层不得不紧急叫停排行榜机制以遏制用量。

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
行业正在经历第一次「Token 大撤退」,部分公司的单日算力消耗已触及亿元量级。
大模型的商业模型正撞上一堵结构性的墙:能力越强、推理链越深,单次调用的成本越高。
GPU 成本营收比(GPU Cost / Revenue)是所有 AI 公司的命门指标,模型参数持续膨胀的趋势只会让这个指标更难看。
Karpathy 的思路指向了另一条路:他提出需要把模型中的「记忆 / 知识」剥离掉,保留他所说的「认知核心」——
一个被剥离了海量事实、知识,但保留了思考算法、智能魔力、问题解决策略的实体。
他判断,即便是 10 亿参数的规模,也能实现高效的类人思考:
它会像人类一样思考……如果你问它一个事实性问题,它可能需要查阅——它知道自己不知道,并且会去查。
这段话在技术社区引发广泛讨论。
方向上的共识正在形成,但能将「认知核心」从概念推到可部署产品的团队,才是真正的变量。
4B 打平千亿级,新程 Alpha 做了什么
把 Karpathy 描述的「认知核心」从概念推到产品的,是明日新程(Nextie)。
这家公司对开源推理模型进行强化学习训练,将知识与认知解耦——剥离模型中记忆性的知识储备,强化泛化和抽象思考能力。
产出的模型被命名为新程 Alpha,参数规模 4B,已完成训练并部署上线,是行业中首个被定义为「认知模型」的产品。
具体到其训练方法,其实是一个不常见的起点。
明日新程团队整理了 1800 年至 2020 年、跨越 220 年的人类学术论文,试图梳理出群体智能的演化脉络,为技术路线提供参照系。
在这套研究的基础上对开源推理模型做强化学习,专注于提升泛化和抽象能力。
举一个直观的例子:经过训练的模型能将围棋选手的决策模式迁移到日常生活场景——Karpathy 所说的「保留思考算法」,在这里有了具体的技术实现。
效果层面,新程 Alpha 在群体智能任务(辩论、反思、挑战、投票等环节)中,4B 参数达到了与 GPT-5.4 等大模型等效的输出质量,算力消耗和推理速度优势显著。
更值得关注的是这个模型解锁的场景空间,有三层递进的意义。
第一层,多智能体决策质量提升。
在 Harness 决策框架中,使用认知模型的输出效果优于推理模型。
底层模型从「推理」升级为「认知」,带来的是多智能体协作系统中决策链条整体质量的跃升。
第二层,算力成本量级缩减。
4B 相较于千亿参数模型,云端部署的算力开销大幅降低。
新程 Alpha 同时支持端侧部署——MacBook、具身智能设备均可直接运行,算力成本由此转化为电力成本。
这对具身智能领域意义尤为突出:用千亿参数大模型驱动一个家务机器人,每一次「思考」都在消耗大量 Token,综合成本可能比请人做家务还贵。
4B 端侧部署,从根本上改写了这笔账。
第三层,主动式(Proactive)场景解锁。
当前绝大多数 AI 产品运行在响应式(Reactive)模式下——用户发指令,模型响应。
Proactive 模式意味着智能体自主决策和执行任务,无需等待命令,商业规模远超 Reactive,但过去始终被算力成本挡在门外。
新程 Alpha 支持 24 小时不间断运行,成本可控,让此前因为太贵而搁置的主动式智能体成为可能。

团队底牌与赛道卡位
明日新程由微软小冰创始团队创立。
这个团队的标签是「用小参数赢大参数」——此前训练的开源模型 rinna(日本小冰)以 3.6B 参数登顶日本 Hugging Face 排行榜第一名,击败了 65B 参数的 Llama。
新程 Alpha 用 4B 打平千亿级大模型的效果,延续的是同一套技术基因。
明日新程重仓布局的赛道是——Harness 群体多智能体。
这条赛道正在获得头部资本的确认——2026 年 3 月,OpenAI 投资了初创公司 Isara,直接将其估值推至 6.5 亿美元,Isara 的研究方向正是多智能体协同与群体智能。

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
在该领域的智能深度评测(IDI)中,明日新程的综合表现显著高于任何单一大模型。
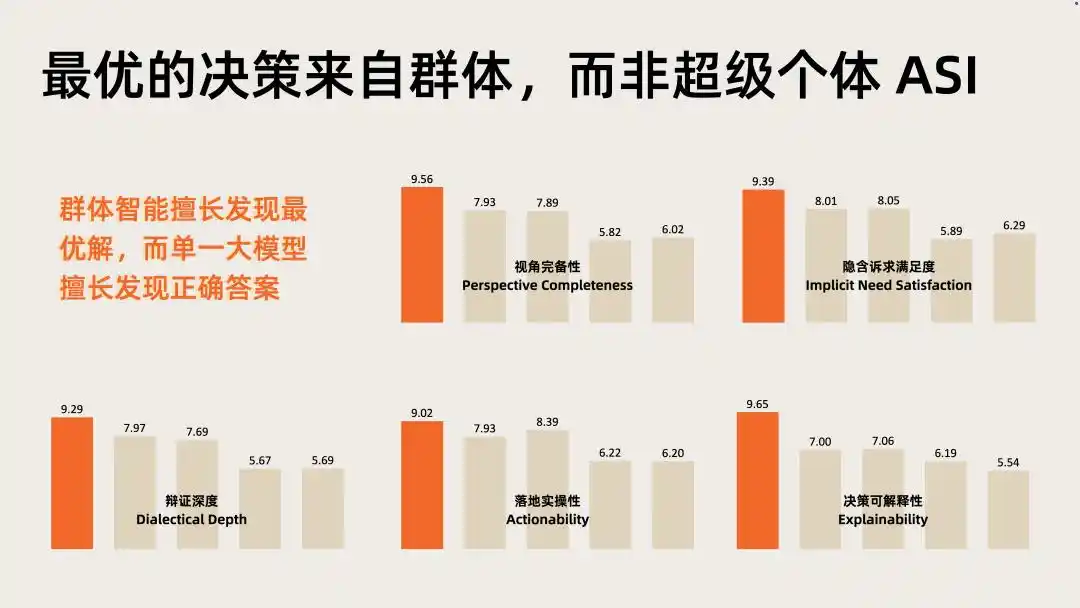
资本验证了赛道价值,评测数据则标定了明日新程在赛道内的位置。
两个信号叠加,指向同一个判断:群体多智能体是 AI 应用层的下一个高价值方向,认知模型是驱动它的关键基础设施。
认知模型改变的不只是参数,更是账本
GPU 成本营收比(GPU Cost / Revenue)是悬在所有 AI 公司头上的达摩克利斯之剑。
认知模型提供的解法,核心指向经济模型的重构——用 4B 达到千亿级才能达到的效果,意味着同样的输出质量对应一套完全不同的成本结构。
明日新程在采访中透露,团队正在训练泛化能力更强的 8B 认知模型。
如果 4B 已经能在群体智能任务中对标 GPT-5.4,8B 的能力边界值得期待。
一个更深远的问题留给整个行业:当端侧全天候运行一个认知模型的成本降至可忽略的水平,今天所有基于「用户发指令、模型响应」的响应式(Reactive)模式设计的 AI 产品,可能都需要重新审视自己的产品形态。
主动式(Proactive)智能体的商业想象空间,远超当前响应式(Reactive)智能体下的一切。
本文来自微信公众号“新智元”,作者:ASI启示录
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容