



SubQuery开发者指南丨SubQuery 字典如何工作?
SubQuery中文站热度: 34653
一文解析SubQuery开发者指南丨SubQuery 字典如何工作?

一个通用字典项目的整个想法是从区块链中对所有数据进行索引并记录事件,插件及其类型(模块和方法),并按区块高度排序。另一个项目然后可以查询此 network.dictionary endpoint,而不是默认 network.endpoint 定义在清单文件中。network. dictionary endpoint 是一个可选的参数,如果存在,SDK 将自动检测和使用。network.endpoint 是强制性的,如果不存在,将不会编译。 将SubQuery dictionary(https://github.com/subquery/subql-dictionary)项目作为示例。schema(https://github.com/subquery/subql-dictionary/blob/main/schema.graphql)文件定义了3个实体;外观、事件、旁观版本。这3个实体分别含有6、4和2个字段。当这个项目运行时,这些字段将反映在数据库表中。
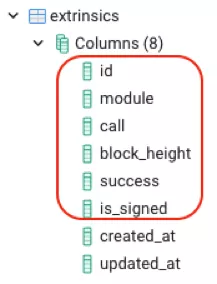
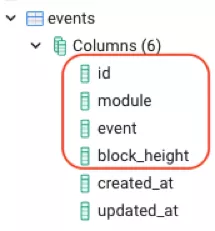
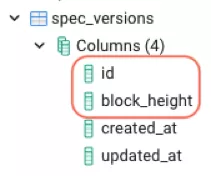
然后,区块链中的数据被存储在这些表中,可进行索引。然后该项目托管在 SubQuery 项目中,API端点可以添加到清单文件。
如何将字典纳入您的项目中?
添加 dictionary: https://api.subquery.network/sq/subquery/dictiony-polkadot 到清单的网络部分。比如:
network:endpoint: wss://polkadot.api.onfinality.io/public-wsdictionary:https://api.subquery.network/sq/subquery/dictionary-polkadot
当字典不使用时会发生什么?
未使用字典时, 一个索引器将根据默认为 100 的 batch-size 标记通过 polkadot api 获取每个区块数据, 并将此放置在缓冲区以供处理。然后,当处理区块数据时,索引器将所有这些区块从缓冲区取出, 检查这些区块中的事件和外在内容是否匹配用户定义的过滤器。 使用字典时会发生什么情况?
当使用字典时,索引器将首先将调用和事件过滤器作为参数,并将其合并为一个 GraphQL 查询。然后它使用字典的 API 来获取一个相关的区块高度列表,只包含特定事件和相关信息。如果使用默认值,这通常大大低于100。 例如,想象一下,您需要检索转账的相关事件。并非所有区块都有这个事件(在下面的图像中,区块3和4中没有转账的事件)。
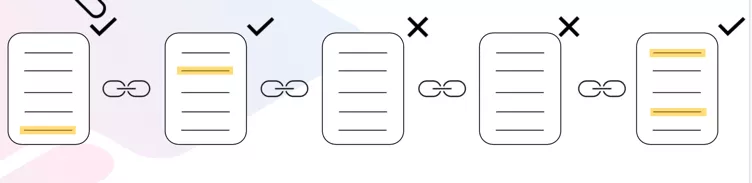
字典允许您的项目跳过这些区块,而不是在每个区块中寻找一个转账事件。它跳到了区块1、2和5。这是因为字典是事先计算的每个区块中所有调用和事件的参考值。 这意味着使用字典可以减少索引器从该区块链中获得的数据数量,并减少当地缓冲区中储存的“不想要的”区块的数量。但与传统方法相比,它增加了一个额外步骤,需要从字典的 API 获取数据。 字典什么时候没有用? 当block handlers(https://doc.subquery.network/create/mapping.html#block-handler)用于从链中获取数据,每个区块都需要处理。因此,在这种情况下使用字典并不提供任何好处,索引器将自动切换到默认的非字典方法。 另外,当处理发生或存在于每个区块的事件或外部事件时,例如 timestamp.set, 使用字典不会提供任何额外的帮助。
免责声明:本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况,及遵守所在国家和地区的相关法律法规。



24H热门新闻
暂无内容