




长推:聊聊大杀器QLoRA——单个GPU可部署ChatBot,达到ChatGPT 99%的能力
St4r热度: 20117
单个GPU即可部署的ChatBot,甚至达到了ChatGPT 99%的能力。
注:本文来自@xinqiu_bot 推特,其是TikTok后端开发工程师,原推文内容由 MarsBit整理如下:
前几天刷到的大杀器QLoRA终于放出了论文和相关实现。单个GPU即可部署的ChatBot,甚至达到了ChatGPT 99%的能力。只需使用消费级GPU微调12个小时就可以达到97%的ChatGPT水平。同时只用4B就可以保持16B精度的效果。
PDF: https://arxiv.org/abs/2305.14314
Github: https://github.com/artidoro/qlora
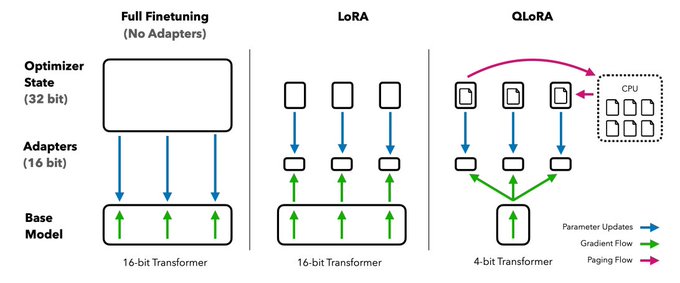
QLoRA通过以下三个创新点来优化资源:
1. 4Bit NormalFloat 4比特量化
2. Double Quantization 双重量化
3. Paged Optimizers 分页优化器
QLoRA是在LORA的基础上,先对Transformer进行4Bit量化,之后再利用GPU分页优化将65B大模型控制在41G显存。从下图中可以看出,同等参数量显存节省了一半。

作者在实验中也发现了一些有趣的点:
1. 指令调优虽然效果比较好,但只适用于指令相关的任务,在Chatbot上相关并不佳,而Chatbot更适合用Open Assistant数据集去进行finetune。通过指令类数据集的调优更像是提升大模型的推理能力,并不是为聊天而生的。
2. 高质量的数据对于微调性能比样本数量更重要,这一点也一直是大家的共识,使用Open Assistant的9000条数据调优12小时即可达到很好的效果,相比FLAN v2使用了超过100万条指令数据。这也和前两天看到的论文对应上,finetune可能并不需要非常多的数据集,少部分高质量的数据就能带来较好结果。
QLoRA的出现确实能给人带来一些新的思考,不管是finetune还是自己部署大模型之后都会变得更加容易。每个人都可以快速利用自己的私有数据进行finetune,同时又能轻松的部署推理大模型。后面我会利用QLoRA的方式来构建私有化QA Bot,看看在中文推理上是否也能取得不错的效果。
本内容旨在传递行业动态,不构成投资建议或承诺。


