




华为达芬奇与英伟达CUDA,必有一战!
一蓑烟雨热度: 14762
英特尔和微软的Wintel曾长期主导电脑市场,现在英伟达的CUDA也成为构建应用生态的重要力量。华为推出的达芬奇架构具备高算力、高能效、灵活可裁剪的特性,是实现全栈全场景AI战略的关键。与CUDA相比,达芬奇专注于端侧、边缘侧和云端的AI应用,但仍受限于生态建设。英伟达限制其他芯片使用CUDA软件,被指垄断市场,华为需要更多依赖自主研发的软件工具和开发环境。未来,英伟达的限制可能影响华为GPU在高性能计算、AI等领域的市场接受度,也加强了华为构建自身AI生态的紧迫性。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文作者:一蓑烟雨
原文来源:数据猿
当初英特尔和微软,搞出来个Wintel,制霸电脑时代很多年。
从某种意义上,英伟达的CUDA,就相当于CPU时代的windows,承担了构建应用生态的重任。而生态的壁垒,是比芯片性能更深厚的竞争壁垒。所以,CUDA才是英伟达最大的王牌。
在CPU时代,我们被Wintel压制了很多年。在AI时代,英伟达集GPU和CUDA于一身,会是另一个难以打破的Wintel么?目前看是的。
由于美国对中国AI产业的打压,芯片这张牌被用的越来越频繁。不仅美国政府,就是英伟达自身处于商业竞争的考虑,也越来越倾向于“打牌”。而CUDA,就是英伟达最大的王牌。中国要在AI计算领域突破封锁,不仅要有自己的GPU,也要有自己的CUDA。要做成这件事情,目前来看,似乎只有靠华为了。
CUDA才是英伟达最深的护城河
在图形渲染的世界中,英伟达以其精湛的GPU技术赢得了市场的青睐。然而,英伟达并未止步于此,它的目光早已超越了图形渲染的边界,投向了更为广阔的计算领域。2006年,英伟达推出了CUDA(Compute Unified Device Architecture),这一举措标志着英伟达从图形渲染巨头向计算巨头的华丽转身。

CUDA的发展历程中,有几个关键节点:
2007年:CUDA 1.0的发布,开放了GPU的通用计算能力,为开发者提供了进入GPU编程世界的钥匙。
2008年:CUDA 2.0增加了对双精度浮点运算的支持,这对于科学计算和工程模拟等领域至关重要。
2010年:CUDA 3.0进一步扩展了GPU的并行处理能力,为更复杂的计算任务提供了支持。
2012年:CUDA 5.0引入了动态并行性,允许GPU内核自我复制,极大地提升了程序的灵活性和效率。
这些版本不仅推动了CUDA技术的进步,也成为了GPU并行计算发展史上的重要里程碑。

CUDA的核心在于其创新的并行计算模型,通过将计算任务分解为成千上万的线程,CUDA能够在GPU上实现前所未有的并行处理能力。这种模型不仅极大地提高了计算效率,也使得GPU成为了解决复杂计算问题的理想平台。从深度学习到科学模拟,CUDA定义了并行计算的新纪元,开启了高性能计算的新篇章。
随着AI和大数据的兴起,CUDA的市场影响力不断扩大。开发者们纷纷转向CUDA,以利用GPU的强大计算能力来加速他们的应用程序。企业也认识到了CUDA的价值,将其作为提升产品性能和竞争力的关键技术。根据统计数据,CUDA的下载量已经超过了3300万次。
对于英伟达而言,CUDA已经成为英伟达最深的护城河。它不仅巩固了英伟达在GPU市场的领导地位,更为英伟达打开了进入高性能计算、深度学习、自动驾驶等多个前沿领域的大门。随着技术的不断进步和市场的不断扩大,CUDA无疑将继续扮演着英伟达最深护城河的角色,引领着计算技术的未来。
比CUDA晚了12年的达芬奇架构,能撑得起华为的AI野心么?
达芬奇架构,作为华为自研的AI计算架构,其起源与华为对AI未来应用的深远洞察密切相关。早在几年前,华为就预测到2025年,全球智能终端的数量将达到400亿台,智能助理的普及率将达到90%,企业数据的使用率将达到86%。基于这样的预测,华为在2018年全联接大会上提出全栈全场景AI战略,并设计了达芬奇计算架构,以在不同体积和功耗条件下提供强劲的AI算力。
达芬奇架构的发展可以追溯到2018年,华为推出的AI芯片Ascend 310(昇腾310)首次亮相,标志着达芬奇架构的正式应用。紧接着,华为在2019年6月发布了全新8系列手机SoC芯片麒麟810,首次采用达芬奇架构NPU,实现了业界领先的端侧AI算力。麒麟810在AI Benchmark榜单中表现卓越,证明了达芬奇架构的实力。
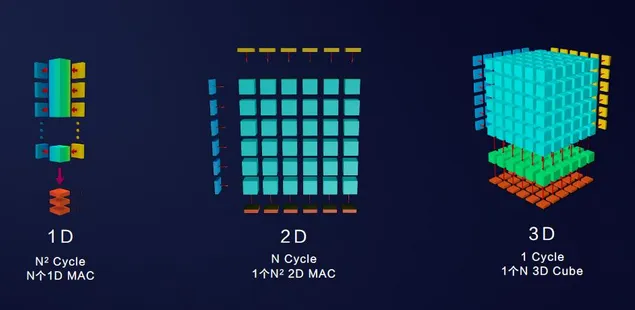
达芬奇架构是专为AI计算特征而设计的全新计算架构,具备高算力、高能效、灵活可裁剪的特性。其核心优势在于采用3D Cube针对矩阵运算做加速,每个AI Core可以在一个时钟周期内实现4096个MAC操作,相比传统的CPU和GPU实现数量级的提升。此外,达芬奇架构还集成了向量、标量、硬件加速器等多种计算单元,并支持多种精度计算,支撑训练和推理两种场景的数据精度要求。
达芬奇架构的应用领域广泛,覆盖了从端侧到云端的全场景AI应用。在端侧,麒麟810芯片的AI算力已经在智能手机中得到应用,为消费者提供了丰富的AI应用体验。在边缘侧和云端,Ascend系列AI处理器可以满足从几十毫瓦到几百瓦的训练场景,提供最优的AI算力。达芬奇架构的灵活性和高效性,使其在智慧城市、自动驾驶、工业制造等多个领域中发挥着重要作用。
诚然,达芬奇架构在华为的AI市场布局中占据了核心的位置。它不仅是华为AI芯片的技术基础,也是华为实现全栈全场景AI战略的重要支撑。通过达芬奇架构,华为能够提供从硬件到软件的全栈AI解决方案,加速AI技术的产业化和应用落地。此外,达芬奇架构的统一性也为开发者带来了便利,降低了开发和迁移成本,促进了AI应用的创新和发展。
达芬奇VS CUDA,有几分胜算?
相比于2006年推出的CUDA,华为达芬奇要晚了12个年头。这12年中,达芬奇一直在追赶。除了时间上的差距,达芬奇和CUDA还在架构设计哲学、性能表现、工具链、开发者生态等多个层面存在显著的差异。
在设计哲学方面,CUDA是英伟达开发的并行计算平台和API模型,它允许开发者使用NVIDIA的GPU进行高效的并行计算。而达芬奇架构是华为自研的面向AI计算特征的全新计算架构,它采用了3D Cube针对矩阵运算做加速,大幅提升单位功耗下的AI算力。CUDA的设计更注重通用性,而达芬奇则专注于AI计算的高效性。
在AI计算性能方面,CUDA和达芬奇各有千秋。CUDA凭借多年的技术积累,支持大规模并行处理能力,适合处理各种复杂的计算任务。达芬奇架构则通过其3D Cube计算引擎,针对矩阵运算进行优化,实现了在单位面积下的AI算力显著提升。在深度学习等AI应用场景中,达芬奇架构展现出了优秀的性能表现。
CUDA和达芬奇架构在不同领域下的适用性各有侧重,CUDA由于其通用性,被广泛应用于科学研究、医学、金融等多个领域。而达芬奇架构则主要针对AI计算,特别是在端侧、边缘侧及云端的AI应用场景中,如智能手机、自动驾驶、云业务等。
从开发者的角度来看,CUDA和达芬奇架构在编程模型与工具链的易用性上有所不同。CUDA提供了一套完整的开发工具链,包括CUDA编译器、调试器、性能分析工具等,支持多种编程语言和深度学习框架。达芬奇架构虽然起步较晚,但华为也在积极构建其工具链和开发者生态,提供必要的支持以促进开发者的使用和创新。但从工具链的完整性和丰富度来看,达芬奇离CUDA还有不少的差距。
CUDA通过其广泛的应用和成熟的技术,已经建立了一个庞大的开发者社区和生态系统。而生态的建设,是比单纯提升GPU性能更难得事情,这才是对华为真正的考验。
华为GPU快成了,但离构建自己的CUDA还很遥远
目前看,华为GPU发展态势较好。
根据公开信息,2023年华为算力GPU的出货量大约为十万片。随着产能的增加,预计到2024年,这个数字将翻几番,达到几十万片的规模。尽管产能有所提升,市场上的订单需求依然非常旺盛,仅在2024年1月份的下单量就已经达到了数十万片。目前,下单需求已经达到上百万片,远超华为当前的供应能力。
在国内购买情况方面,华为算力GPU受到了市场的热烈追捧。华为算力GPU的客户主要分为三个梯队:第一类是三大运营商和政务类客户,第二类是互联网客户,第三类是其他公司。由于算力GPU的紧缺,客户为了尽快拿到产品,都在努力成为第一梯队的客户,甚至采取与地方政府合作等措施以确保优先供应。
价格方面,华为算力GPU自2023年8月上市以来,价格已经经历了至少两次提价。最初上市的价格约为7万元人民币,而目前市场价格已经上涨至约12万元人民币。
总体来看,华为GPU的发展态势良好,市场需求强劲,尽管供应紧张,但这也反映出华为GPU在性能和国产化方面的优势,使其成为市场中的热门选择。随着技术的不断进步和产能的进一步提升,预计华为GPU将在未来市场中占据更重要的位置。
在一次专访中,黄仁勋表示:“华为是个好公司”。此外,英伟达在财报中将华为列为主要竞争对手,这反映了华为在GPU及相关技术领域的竞争力正在增强。
尽管华为GPU发展态势良好,但CUDA作为GPU领域占主导地位的框架,其生态系统的成熟度和广泛接受度远远超过了其他框架,包括AMD开发的框架。华为的AI计算框架在生态建设方面确实还有很长的路要走,需要持续的技术创新和市场推广才能逐步构建起与CUDA相匹敌的生态系统。
然而,英伟达不想给华为成长起来的时间了。
近期,英伟达对其CUDA平台的兼容性政策进行了调整,限制了CUDA软件在非英伟达硬件平台上的运行行为,这一决策始于2021年,并在随后的时间里逐步加强。具体来说,英伟达通过更新其最终用户许可协议(EULA),明确禁止了使用转换层或模拟层在非英伟达GPU上运行CUDA代码的行为。
这一政策变动主要影响了那些试图通过转译技术实现CUDA兼容性的第三方项目,例如ZLUDA等。ZLUDA是一个允许在非英伟达硬件上运行CUDA程序的转译库,它提供了一种相对简单的方式,使得开发者能够在性能略有损失的情况下,运行CUDA程序。
英伟达此举,被广泛认为是保护其市场份额和维护其技术控制权的战略举措。通过限制在其他芯片上使用CUDA软件的方式,英伟达确保其GPU仍然是开发人员和依赖其并行计算平台的企业的首选。
然而,这一决策在业界引起了不小的震动,并引发了广泛的讨论。不少人指责英伟达借助封锁政策垄断市场,压制竞争对手的发展机会。
面对英伟达的限制政策,一些国内GPU企业如摩尔线程选择了遵守EULA规定,并表态采用重新编译代码的方式与EULA保持一致,以避免违反英伟达的限制条款。
此外,业界其他力量,包括AMD、英特尔等厂商,并未因英伟达的限制而止步,他们正在积极推动开放、可移植的生态系统建设,以试图打破英伟达的市场垄断。
面对英伟达的出牌,华为在发展自己的GPU技术时,需要更多地依赖自主研发的软件工具和开发环境,而不是依赖于CUDA这样的成熟平台。这意味着华为需要投入更多的资源来构建自己的软件生态系统,包括开发与CUDA性能相匹敌的编程工具、库和API。
可以预见,在未来较长一段时间内,由于CUDA的广泛使用和对高性能计算、AI等领域的深远影响,英伟达的这一政策可能会限制华为GPU的市场接受度,特别是在那些已经深度依赖于CUDA的领域。
这加强了华为构建自身AI计算架构和AI生态的紧迫性,就像当初安卓断供成就了鸿蒙一样,CUDA的收紧会否成为华为达芬奇架构的神助攻呢?现在还不好评判,让子弹飞一会吧。
本内容旨在传递行业动态,不构成投资建议或承诺。
本文来源:一蓑烟雨
原文标题:华为达芬奇与英伟达CUDA,必有一战!



24H热门新闻
暂无内容