




10分钟搞懂英伟达核心壁垒:CUDA
沧海一粟热度: 12579
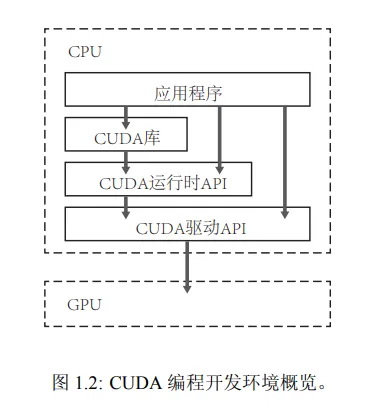
CUDA是英伟达推出的GPU计算平台,可加速各种任务。它与CPU组成异构架构,通过CUDA编程控制GPU核心解决问题。开发者可使用NVIDIA驱动、CUDA Toolkit和API进行CUDA编程。显卡驱动、CUDA Toolkit和API是CUDA的重要组成部分,深度学习框架如TensorFlow和PyTorch深度整合了CUDA,支持GPU加速神经网络训练和推理。CUDA库如cuBLAS、cuDNN提供高效的线性代数和深度学习算法实现,使开发者能更高效地开发GPU加速应用程序。CUDA支持多种编程语言。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文作者:沧海一粟
原文来源:槿墨AI
什么是CUDA
CUDA(Compute Unified Device Architecture),统一计算设备架构,英伟达推出的基于其GPU的通用高性能计算平台和编程模型。
借助CUDA,开发者可以充分利用英伟达GPU的强大计算能力加速各种计算任务。
软件生态的基石:CUDA构成了英伟达软件生态的基础,诸多前沿技术均基于CUDA构建。
例如,TensorRT、Triton和Deepstream等,这些技术解决方案都是基于CUDA平台开发的,展示了CUDA在推动软件创新方面的强大能力。
软硬件的桥梁:英伟达的硬件性能卓越,但要发挥其最大潜力,离不开与之相匹配的软件支持。
CUDA正是这样一个桥梁,它提供了强大的接口,使得开发者能够充分利用GPU硬件进行高性能计算加速。
就像驾驶一辆高性能汽车,CUDA就像是一位熟练的驾驶员,能够确保硬件性能得到充分发挥。
深度学习框架的加速器:CUDA不仅在构建英伟达自身的软件生态中扮演关键角色,在推动第三方软件生态发展方面也功不可没。
特别是在深度学习领域,CUDA为众多深度学习框架提供了强大的加速支持。
例如,在Pytorch、TensorFlow等流行框架中,CUDA加速功能成为标配。
开发者只需简单设置,即可利用GPU进行高效的训练和推理任务,从而大幅提升计算性能。

CPU+GPU异构计算
CPU:中央处理器(Central Processing Unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。
运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务,CPU更擅长数据缓存和流程控制——(少量的复杂计算)
GPU:图形处理器(Graphics Processing Unit),常被称为显卡,GPU最早主要是进行图形处理的。
如今深度学习大火,GPU高效的并行计算能力充分被发掘,GPU在AI应用上大放异彩。
GPU拥有更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算——(大量的简单运算)
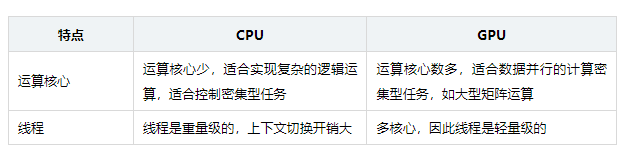
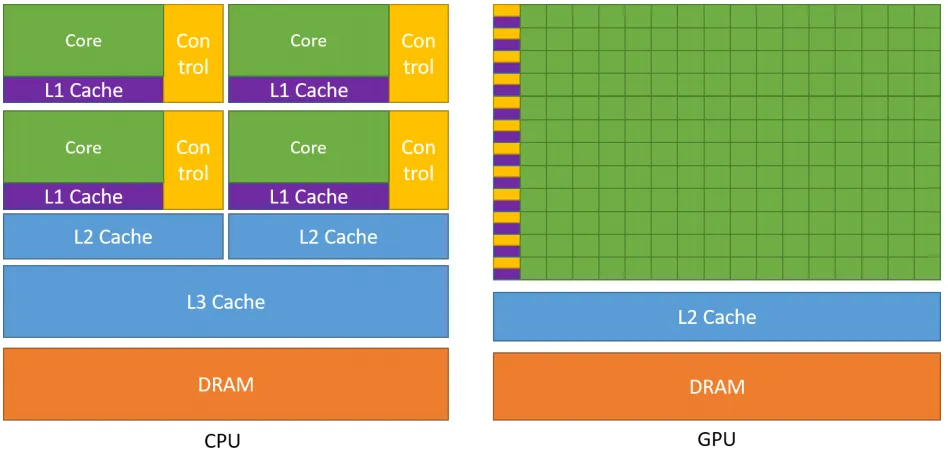
一个典型的 CPU 拥有少数几个快速的计算核心,而一个典型的 GPU 拥有几百到几千个不那么快速的计算核心。
CPU的晶体管设计更多地侧重于数据缓存和复杂的流程控制,而GPU则将大量晶体管投入到算术逻辑单元中,以实现并行处理能力。
因此,GPU正是通过其众多的计算核心集群来实现其相对较高的计算性能。
使用CUDA编程,开发者可以精确地指定数据如何被分配到GPU的各个核心上,并控制这些核心如何协同工作来解决问题。
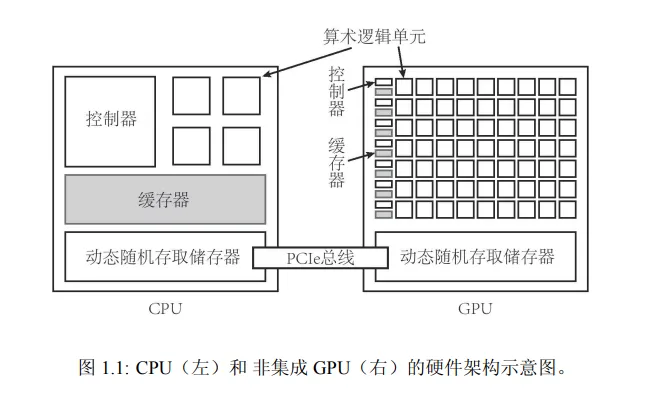
GPU不能单独进行工作,GPU相当于CPU的协处理器,由CPU进行调度,CPU+GPU组成异构计算架构。
在由 CPU 和 GPU 构成的异构计算平台中,通常将起控制作用的 CPU 称为主机(host),将起加速作用的 GPU 称为设备(device)。
主机和设备之间内存访问一般通过PCle总线链接。
计算生态
#开发工具链
①NVIDIA driver
· 显卡驱动是连接操作系统和显卡硬件之间的桥梁,确保显卡能够正常工作并发挥最佳性能。
· 显卡驱动包含硬件设备的信息,使得操作系统能够识别并与显卡硬件进行通信。
· 显卡驱动对于启用显卡的全部功能、性能优化、游戏和应用程序兼容性以及修复问题和安全更新都至关重要
②CUDA Toolkit
· CUDA Toolkit是一个由NVIDIA开发的软件开发工具包,它为NVIDIA GPU提供了一组API和工具,使得开发人员可以利用GPU的并行计算能力来加速计算密集型应用程序。
· CUDA Toolkit包括CUDA编译器(NVCC)、CUDA运行时库、CUDA驱动程序等组件,它们协同工作,使得开发人员可以使用C或C++编写GPU加速的代码。
③CUDA API
· CUDA API是CUDA编程的接口集合,它允许开发者使用CUDA进行高性能计算。
· CUDA API包括CUDA Runtime API和CUDA Driver API,它们提供了用于管理设备、内存、执行等功能的函数。
· 开发者可以通过CUDA API来编写CUDA程序,以利用GPU的并行计算能力。
④NVCC
· NVCC是CUDA的编译器,属于CUDA Toolkit的一部分,位于运行时层。
· NVCC是一种编译器驱动程序,用于简化编译C++或PTX代码。它提供简单且熟悉的命令行选项,并通过调用实现不同编译阶段的工具集合来执行它们。
· 开发者在编写CUDA程序时,需要使用NVCC来编译包含CUDA核心语言扩展的源文件。
NVIDIA driver是确保显卡正常工作的基础,而CUDA Toolkit则是利用GPU进行高性能计算的软件开发工具包。
CUDA API是CUDA编程的接口,而NVCC则是CUDA的编译器,用于将CUDA程序编译成可在GPU上执行的代码。
应用框架与库支持
CUDA广泛支持各类科学计算、工程、数据分析、人工智能等领域的应用框架和库。
例如,在深度学习领域,TensorFlow、PyTorch、CUDA Deep Neural Network Library (cuDNN) 等工具均深度整合了CUDA,使得开发者可以轻松利用GPU加速神经网络训练和推理过程。
#深度学习框架
· TensorFlow:TensorFlow是Google开发的开源机器学习框架,它支持分布式计算,并且可以高效地使用GPU进行数值计算。TensorFlow在底层使用了CUDA和cuDNN等NVIDIA的库来加速深度学习模型的训练和推理过程。
· PyTorch:PyTorch是Facebook人工智能研究院(FAIR)开发的深度学习框架。PyTorch也支持CUDA,并且提供了丰富的API来让开发者轻松地使用GPU进行深度学习模型的训练和推理。PyTorch和CUDA的版本之间存在一定的兼容性关系,需要确保PyTorch的版本与CUDA的版本兼容。
#CUDA库
· cuBLAS:用于线性代数运算的库,如矩阵乘法、前缀求和等,常用于科学和工程计算。
· cuDNN:NVIDIA CUDA深度神经网络库(cuDNN)是一个用于深度学习的GPU加速库,提供了一系列深度学习算法的高效实现。
· cuSPARSE:针对稀疏矩阵的线性代数库。
· cuFFT:快速傅里叶变换库,用于执行高效的FFT(快速傅里叶变换)操作。
· cuRAND:随机数生成库,允许开发者在GPU上生成随机数。
这些库为开发者提供了丰富的计算资源,使他们能够更高效地开发GPU加速的应用程序。
CUDA编程语言
C、C++、Fortran、Python 和 MATLAB
本内容旨在传递行业动态,不构成投资建议或承诺。
本文来源:沧海一粟
原文标题:10分钟搞懂英伟达核心壁垒:CUDA



24H热门新闻
暂无内容