




生物学变天:小扎的新开源模型,彻底掀翻谷歌AlphaFold王座
新智元热度: 10474
扎克伯格旗下Biohub发布开源AI模型ESMFold2及ESM Atlas数据库,预测11亿个蛋白质结构,规模超AlphaFold 5倍,覆盖环境微生物等新领域,在复合结构预测和蛋白质设计验证上表现优异,以完全开源、不限商用策略挑战谷歌DeepMind的闭源主导地位,推动蛋白质AI进入开源竞争新阶段。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
AlphaFold 王座告急!
Nature 刊文:扎克伯格旗下 Biohub 放了一记王炸,一口气发布 11 亿个蛋白质结构预测,比 AlphaFold 数据库多出 8 亿条。
背后的 AI 模型 ESMFold2 号称性能全面超越 AlphaFold3。
更关键的是,完全开源,不限商用。

https://www.nature.com/articles/d41586-026-01686-3
谷歌 DeepMind 苦心经营多年的蛋白质 AI 霸主地位,正在被一个开源搅局者动摇。
蛋白质 AI 赛道的格局,可能要重写了。
11 亿个蛋白质结构,一把端上桌了
5 月 27 日,扎克伯格夫妇创建的生物医学机构 Biohub,正式上线了名为 ESM Atlas 的蛋白质结构数据库。
11 亿个预测蛋白质结构,外加 68 亿条蛋白质序列信息。
AlphaFold 的数据库积累了超过 2 亿个结构预测,ESM Atlas 一来就多出 8 亿条。
生成这些预测的 AI 模型叫 ESMFold2,由 Biohub 科学负责人 Alex Rives 带队开发。

Rives 说:
这个图谱展示了蛋白质生物学的全貌,尤其是那些最未知的部分。
蛋白质结构预测为什么重要?
蛋白质是生命运转的核心零件,知道它的形状就能理解它的功能,进而设计新药、攻克疾病。
AlphaFold 靠这个拿了诺贝尔化学奖,是 AI 改变科学的标志性案例。
现在一个新模型拿着大 5 倍的数据集站了出来。
作为 AI 模型,ESMFold2 强在哪
ESMFold2 走了一条和 AlphaFold 不同的技术路线。
它基于 2024 年发布的「蛋白质语言模型」构建,核心思路借鉴了 NLP 领域的做法,把蛋白质序列当作「语言」来理解,在数十亿条蛋白质数据上训练,让模型学会从序列直接预测三维结构。
AlphaFold 的 AI 同行们看到这里应该会觉得熟悉,这和大语言模型学习人类语言的逻辑是一样的。
训练数据的覆盖范围是关键变量。
ESMFold2 纳入了大量来自土壤、海洋等环境的微生物蛋白质数据,这部分在 AlphaFold 的数据库里是空白的。
覆盖面更广,模型见过的「蛋白质世界」就更完整。
Biohub 团队称,ESMFold2 在预测蛋白质之间相互作用的复合结构方面,表现优于 AlphaFold3。
但最有说服力的不是跑分,而是落地验证。
团队用 ESMFold2 设计了全新的蛋白质,拿到实验室合成测试,高比例的设计按预期起效了。
从「预测」到「设计」再到「验证」,这条链路跑通,价值就从论文延伸到了真实世界。

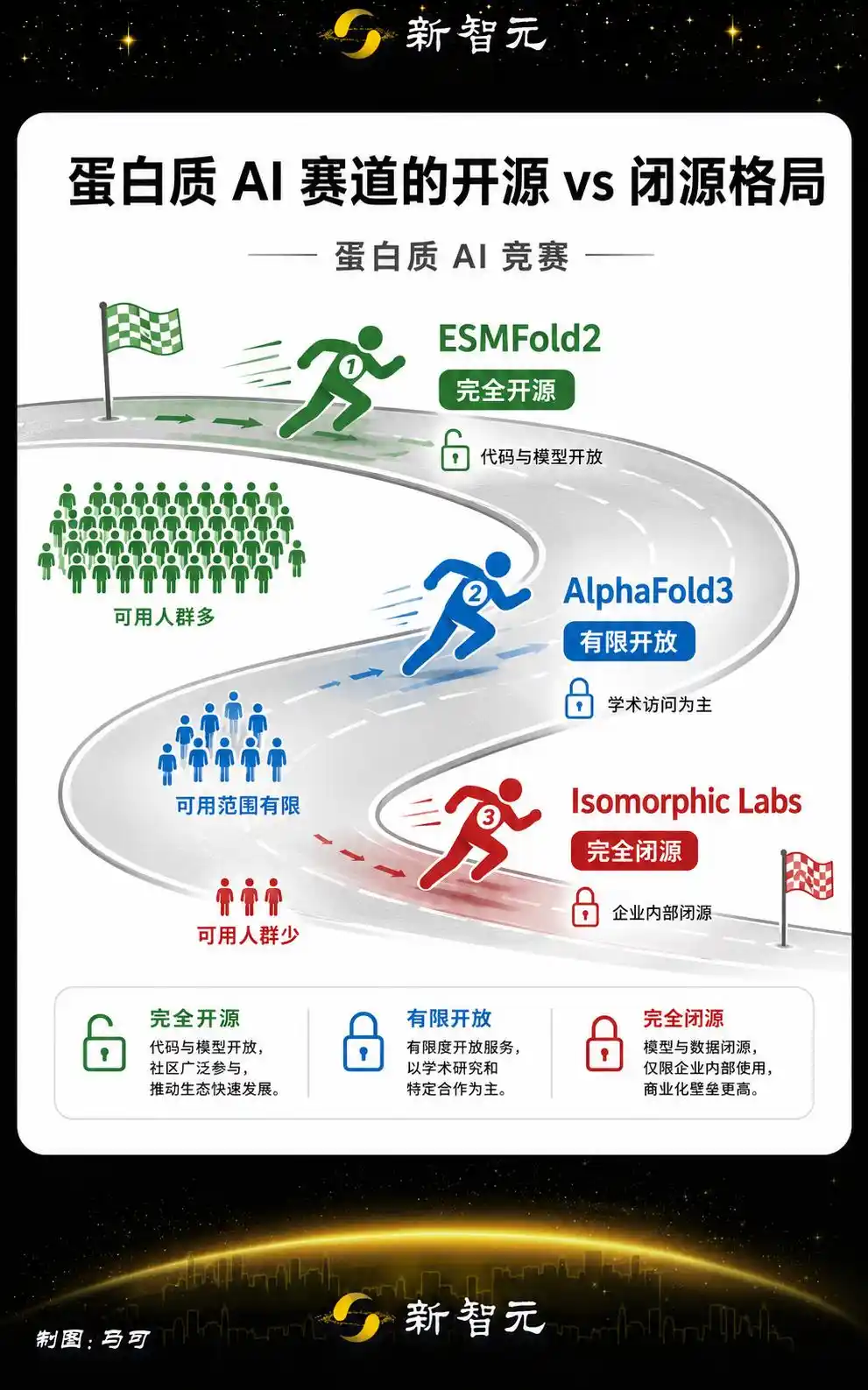
全部开源,这才是最大的杀手锏
ESMFold2 最锋利的竞争武器,是完全开源且不限商用。
这个选择的战略意义,放到整个 AI 行业的语境下看更清楚。
AlphaFold 虽然有开放数据库,但 AlphaFold3 在发布初期对商业使用做了限制。
谷歌 DeepMind 旗下的 Isomorphic Labs 今年推出的蛋白质相互作用预测模型更是完全闭源。
拓展阅读:谷歌发布「AlphaFold 4」,不再开源!性能碾压上一代
MIT 的计算生物学家 Ovchinnikov 直接点明了开源的价值,「我预计很多人会很兴奋地想试一试 ESMFold2。」
开源 AI 的杠杆效应在大语言模型赛道已经被充分验证,Meta 的 Llama 系列就是最好的例子。
一个足够强的开源模型,能撬动全球社区去迭代、应用、发现原始开发者自己都没想到的用法。
蛋白质 AI 领域的情况更特殊,全球有大量实验室和研究机构迫切需要一个免费、无限制的结构预测工具,闭源模型再强,能触达的用户群就那么大。
Biohub 选择全面开源,跟 Meta 在大语言模型上的打法一脉相承。
扎克伯格系在 AI 领域的策略越来越清晰——用开源做基础设施,用生态做护城河。
同行大牛,买不买账?
学界反应积极,但保留意见也很明确。
瑞典隆德大学的 Gemma Atkinson 称 ESM Atlas 「应该成为生物学的非凡资源」。
伦敦大学学院的 Christine Orengo 认可其价值,但强调预测结果需要独立验证。

更尖锐的问题来自首尔国立大学的 Martin Steinegger。

他关心的是,ESMFold2 面对那些与已知蛋白质差异很大的「新结构」时,表现到底如何。
他的团队此前发现,ESMFold 第一版在这方面并不出色。这个问题对 ESMFold2 依然悬而未决。
MIT 的 Ovchinnikov 给出了最冷静的判断,他认为 ESM Atlas 更适合定位为 AlphaFold 数据库的补充。

他还指出,Isomorphic Labs 的闭源模型以及一些 Biohub 没有直接拿来对比的开源模型,也取得了类似水平的成果。
ESMFold2 的领先幅度,可能没有论文暗示的那么大。
这种审慎,恰恰折射出蛋白质 AI 赛道的竞争已经白热化。
开源、闭源、学术、商业,各路模型都在以极快速度迭代。
今天的「最强」,半年后可能就被刷新。这个节奏,和大语言模型赛道的军备竞赛已经非常像了。
当 AI 开始读懂生命的源代码
过去,解析一个蛋白质的三维结构可能需要几个月到几年的实验室工作。
AlphaFold 第一次证明 AI 可以在几分钟内做到。
现在 ESMFold2 把预测规模推到了 11 亿量级,覆盖了大量此前从未被解析的蛋白质。
沿着这条路往前推演,当 AI 能精准预测所有蛋白质结构,能设计全新的功能性蛋白质且实验验证有效,那距离 AGI 在生命科学领域的落地,可能比大多数人预想的更近。
如果 ASI 真正到来,生物学对它而言不再是需要「研究」的学科,而是可以被「工程化」的系统。
从分子层面设计生命,按需定制蛋白质,重写进化的规则。
这听起来像科幻,但 ESMFold2 这类工具正在一步步把「科幻」变成「工程问题」。
今天,11 亿个蛋白质结构被摊开在桌上,全球任何有网络连接的科学家都可以免费取用。
这意味着,AI 理解生命的能力,又上了一个台阶。
参考资料:https://www.nature.com/articles/d41586-026-01686-3
本文来自微信公众号“新智元”,作者:ASI启示录;编辑:马可
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容