




EZKL:硬件加速 ZKML 的具体方案和策略
火星财经热度: 16295
Ingonyama团队开发的开源Icicle GPU加速库使开发人员能够利用硬件加速,MSM时间减少了98%,总聚合证明时间减少了35%。未来,将继续优化和扩展EZKL与Icicle集成的能力,如扩展GPU操作和将更多的CPU操作卸载到GPU,以实现更高的效率和速度。
 摘要由 Mars AI 生成
摘要由 Mars AI 生成本摘要由 Mars AI 模型生成,其生成内容的准确性、完整性还处于迭代更新阶段。
原文标题:Steps in Hardware, Leaps in Performance
原文作者:EZKL & Ingonyama
原文来源:EZKL Blog
编译:Kate, 火星财经
本文是与Ingonyama团队合作编写的。特别感谢@jeremyfelder让这一切成为可能。
硬件加速的 ZKML
我们最近整合了由Ingonyama团队构建的的开源Icicle GPU加速库。这使开发人员能够通过简单的环境配置来利用硬件加速。
该集成是对EZKL引擎的战略性增强,解决了当前ZK证明系统固有的计算瓶颈。它尤其适用于大型电路,比如为机器学习模型生成的电路。
我们观察到,与基线CPU运行相比,聚合电路的MSM时间减少了98%,总聚合证明时间与基线CPU证明时间相比减少了35%。
这是全面硬件集成的第一步。与Ingonyama团队一起,我们将继续致力于对GPU操作的全面支持。此外,我们正在努力与其他硬件供应商集成——理想情况下,为更广泛的领域展示切实的基准。
我们在下面提供上下文和技术规范。或者你也可以随时直接进入这里的库。
零知识瓶颈
引用硬件评论:GPU, FPGA和零知识证明,零知识应用程序有两个组成部分:
1. DSL和低级库:它们对于以ZK友好的方式表达计算是必不可少的。例子包括Circom、Halo2、Noir和像Arkworks这样的低级库。这些工具将程序转换为约束系统(或在这里阅读更多),其中像加法和乘法这样的操作被表示为单个约束。位操作更加棘手,需要更多的约束。
2. 证明系统:它们在生成和验证证明方面起着至关重要的作用。验证系统处理电路、证人和参数等输入。通用系统包括Groth16和PLONK,而像EZKL这样的专用系统则迎合机器学习模型等特定输入。
在最广泛部署的ZK系统中,主要的瓶颈是:
• 多标量乘法(MSM):对向量进行大规模乘法,即使在并行化时也会消耗大量时间和内存。
• 快速傅里叶变换(FFT):需要频繁变换数据的算法,使其难以加速,特别是在分布式基础设施上。
硬件的作用
硬件加速,如GPU和FPGA,通过增强并行性和优化内存访问,提供了比软件优化显著的优势:
• GPU:提供快速开发和大规模并行性,但耗电量很大。
• FPGA:提供更低的延迟,特别是对于大数据流,并且更节能,但具有复杂的开发周期。
有关最佳硬件设计和性能的更广泛讨论,请参阅此处。该领域正在迅速发展,许多方法仍然具有竞争力。
Halo2的GPU加速
在Halo2验证系统中,瓶颈可能会因所验证的具体电路而异。这些瓶颈主要分为两类:
1. 承诺瓶颈(MSM):这些主要是计算瓶颈,通常是可并行化的。在MSM是瓶颈的电路中,我们观察到一定程度的通用性。这意味着应用GPU加速的解决方案可以通过对现有代码库的最小修改来有效地解决这些瓶颈。
2. 约束评估瓶颈(尤其是在h poly中):这些瓶颈更为复杂,因为它们可能是计算密集型的,也可能是内存密集型的。它们在很大程度上取决于电路的细节。解决这些问题需要对评估算法进行量身定制的重新设计。这里的重点是优化内存使用和计算之间的权衡,以及决定是存储中间结果还是重新计算它们。

一个典型的例子是KZG聚合电路。在这种电路中,主要的挑战在于椭圆曲线群元素的积累。这些情况下的约束是相对统一且程度较低的(例如,根据Halo2文档,具有4级约束的不完全加法公式)。
因此,大部分复杂性来自于承诺(MSM),这是一个可以通过GPU加速有效解决的计算问题。
对于这个集成的范围,我们选择关注承诺瓶颈。这是唾手可得的成果,也是对引擎核心组件(KZG聚合)的优化。这只是第一步,还有很多工作要做。
Icicle:支持 CUDA 的 GPU
Ingonyama的团队开发了Icicle作为一个开源库,使用支持CUDA的GPU为ZK加速设计。CUDA,即计算统一设备架构,是由英伟达创建的并行计算平台和API模型。它允许软件利用英伟达GPU进行通用处理。Icicle的主要目标是将证明程序代码的重要部分卸载到GPU并利用并行处理能力。
Icicle在Rust和Golang中托管API,这简化了集成。该设计也可定制,具有以下特定:
• 高级API:用于提交、求值和插值多项式等常见任务。
• 低级API:针对特定运算,如多标量乘法(MSM)、数论变换(NTT)和逆数论变换(INTT)。
• GPU内核:用于GPU上特定任务的优化执行。
值得注意的是,Icicle支持基本功能,如:
• 矢量化字段/组算术:有效处理字段和组上的数学运算。
• 多项式算法:许多ZK算法的关键。
• 哈希函数:对加密应用程序至关重要。
• 复杂结构:如逆椭圆曲线数论变换(I/ECNTT)、批处理MSM和Merkle树。
与EZKL集成
Icicle库已经与EZKL引擎无缝集成,为直接访问NVIDIA GPU或简单地访问Colab的用户提供GPU加速。这种集成通过利用GPU的并行处理能力增强了EZKL引擎的性能。下面是如何启用和管理此功能:
• 启用GPU加速:要启用 GPU 加速,请使用该Icicle功能构建系统并设置环境变量,如下所示:
export ENABLE_ICICLE_GPU=true
• 恢复到CPU:要切换回CPU处理,只需取消ENABLE_ICICLE_GPU环境变量的设置,而不是将其设置为false:
unset ENABLE_ICICLE_GPU
• 定制小型电路的阈值:如果希望修改构成小型电路的阈值,可以将ICICLE_SMALL_K环境变量设置为所需值。这允许更好地控制何时使用GPU加速。
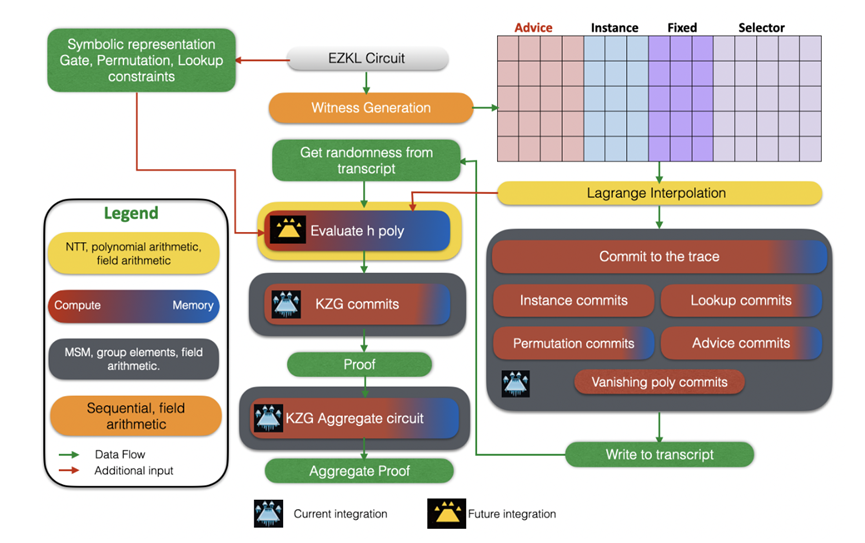
当前ICICLE整合概述。这种集成的目标是由于MSM导致的计算瓶颈,在KZG聚合电路中可以看到显著的影响。
关键功能
这种集成提供了几种技术支持。
最重要的是,该集成支持使用 Icicle 库在 GPU 中进行即插即用 MSM 操作。作为目标和测试环境,我们专注于替换EZKL聚合命令中基于CPU的KZG承诺。这是将多个证明合并为一个证明的地方。更具体地说,KZG承诺的commit和commit_lagrange(在CPU上完成)与BN254椭圆曲线的MSM操作(在GPU上)。
我们还启用了环境变量和crate功能,允许开发人员在相同二进制/构建EZKL的不同电路之间切换CPU和GPU。为了优化GPU切换,默认情况下仅对大 k 电路 (k > 8) 启用 GPU 加速。
基准测试结果
我们的基准测试结果表明,将Icicle库集成到EZKL引擎中,性能有了实质性的提高:
• MSM时间的显著减少:我们观察到,与聚合电路的基准CPU运行相比,多标量乘法(MSM)时间减少了大约98%。这表明计算任务的高效卸载到GPU。
• MSM操作的速度显著提高:与基准CPU配置相比,ICICLE执行的MSM操作平均快50倍。这种加速在aggregate命令中的大多数MSM中是一致的。
• 证明时间的总体减少:与基准CPU证明时间相比,生成聚合证明所需的总时间减少了约35%。这反映了证明生成过程中显著的整体性能增强。
这些结果突出了GPU加速在优化ZK证明系统方面的有效性,特别是在计算方面,如MSM操作。要进行验证,您可以在这里查看我们的持续集成测试。
未来的发展方向
展望未来,我们计划进一步优化和扩展EZKL与Icicle集成的能力:
• 扩展GPU操作:重点关注的一个领域是用GPU取代更多的CPU操作。这包括涉及数论变换(NTT)的操作,它目前是基于CPU的。通过将这些操作卸载到GPU,我们期望实现更高的效率和速度。
• 引入批量操作:另一个重要的发展是添加批量操作。此增强功能特别旨在即使在更小和更宽的电路中也能高效使用 GPU。通过这样做,我们的目标是将GPU加速的好处扩展到更广泛的电路类型和尺寸,确保在所有场景下的最佳性能。
更广泛地说,我们寻求看到与其他硬件系统的集成。这将为更广泛的领域提供功能基准测试和开发人员灵活性。
通过这些未来的发展,我们的目标是继续推动ZK证明系统的性能界限,使其更高效,并且适用于更广泛的应用。
附录
未来集成注意事项
对于贡献者和开发人员,我们在具有四个证明的自定义实例上使用聚合命令教程测试了这种集成。关于未来集成的一些注意事项
• 基准测试环境:使用AWS c6a.8xlarge实例与AMD Epyc 7R13的基准CPU运行c测试。
• 聚合命令教程:使用聚合命令教程验证了集成的性能,包括一个具有4个基线比较证明的测试实例。
• 在单个MSM实例上的初始测试:最初,测试集中在EZKL/halo2板条箱中的单个MSM实例上,以验证功能。
• 完整证明中GPU上下文的问题:在扩展到完整证明时,发现GPU上下文在单个操作后丢失。解决方案是通过创建静态引用来维护整个证明命令中的 GPU 上下文来实现的。
• 关注聚合电路/命令:该集成主要针对聚合电路/命令,其特点是K(约束数量)很大,而advice栏数少。
• 对Proof命令的影响:代码中的修改也会影响Proof命令。有必要确保单个证明的性能随着这些变化而保持或改进。
• 基于电路尺寸和宽度的性能变化:对于大型和狭窄的电路,GPU增强产生了积极的结果。然而,对于更小(K≤8)和更宽的电路,GPU 增强会导致性能下降。
• 通用优化的未来改进:计划将增强所有电路类型的GPU集成,特别是关注批处理操作,以实现各种电路尺寸的最佳性能。
本内容旨在传递行业动态,不构成投资建议或承诺。



24H热门新闻
暂无内容